【吐血整理】数据库的完整性
本文主讲 数据库完整性,欢迎阅读~
本文目录
- 前言
- 一、实体完整性
- 1. 实体完整性定义
- 2. 实体完整性检查和违约处理
- 二、参照完整性
- 1. 参照完整性定义
- 2. 参照完整性检查和违约处理
- 三、用户定义的完整性
- 1. 属性上的约束条件
- 2. 元组上的约束条件
- 四、完整性约束命名字句
- 1. 完整性约束命名子句
- 2. 修改表中的完整性限制
- 五、触发器
- 1. 定义触发器
- 2. 激活触发器
- 3. 删除触发器
- 六、浅谈存储过程
前言
数据库的完整性:
- 数据的正确性
数据是符合现实世界语义,反映了当前实际状况的 - 数据的相容性
同一对象在不同关系表中的数据是符合逻辑的
【例如】:学生的学号必须唯一、性别只能是男或女、本科学生年龄的取值范围为14~50的整数、学生所选的课程必须是学校开设的课程,学生所在的院系必须是学校已成立的院系
— — — — — — — — — — — — — — — — — —
数据的“完整性”和“安全性”是两个不同概念:
数据的完整性
① 防止数据库中存在不符合语义的数据,也就是防止数据库中存在不正确的数据
② 防范对象:不合语义的、不正确的数据
数据的安全性
① 保护数据库 防止恶意的破坏和非法的存取
② 防范对象:非法用户和非法操作
一、实体完整性
1. 实体完整性定义
关系模型的实体完整性: CREATE TABLE中用PRIMARY KEY定义
来看例子: 将Student表中的Sno属性定义为码:
ps:因为我之前的STUDENT数据库中已经有Student表了,所以我新建了SCHOOL数据库用户本文的实验
CREATE DATABASE SCHOOL;
1)在列级定义主码
CREATE TABLE Student (
Sno CHAR(9) PRIMARY KEY,
Sname CHAR(20) NOT NULL,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20)
);
2)在表级定义主码
CREATE TABLE Student (
Sno CHAR(9),
Sname CHAR(20) NOT NULL,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20),
PRIMARY KEY (Sno)
);
这里主码只包含一个属性,所以列级定义和表级定义均可(不过就一个的话直接在列级定义叭,毕竟写的单词少一点哈哈)。
如果主码由多个属性组成,即联合主码(2个及其以上的属性构成主码),可参照下一个例子,那就只能在表级定义了,要在列级定义的话就会出现多条PRIMARY KEY,这是不允许的(因为一张表中只能有一个主码!)

Another one: 将SC表中的Sno,Cno属性组定义为码:
CREATE TABLE SC (
Sno CHAR(9) NOT NULL,
Cno CHAR(4) NOT NULL,
Grade SMALLINT,
PRIMARY KEY (Sno, Cno) /*主码由两个属性构成,只能在表级定义主码*/
);

2. 实体完整性检查和违约处理
插入或更新操作时,DBMS按照实体完整性规则自动进行检查:
- 检查主码值是否唯一,如果不唯一则拒绝插入或修改
- 检查主码的各个属性是否为空,只要有一个为空就拒绝插入或修改
二、参照完整性
1. 参照完整性定义
关系模型的参照完整性定义:
① 在CREATE TABLE中用FOREIGN KEY短语定义哪些列为外码
② 用REFERENCES短语指明这些外码参照哪些表的主码
例如,关系SC中(Sno,Cno)是主码。Sno,Cno分别参照Student表的主码和Course表的主码,看下面的例子:
来看例子: 定义SC中的参照完整性:
CREATE TABLE SC (
Sno CHAR(9) NOT NULL,
Cno CHAR(4) NOT NULL,
Grade SMALLINT,
PRIMARY KEY (Sno, Cno), /*在表级定义实体完整性*/
FOREIGN KEY (Sno) REFERENCES Student(Sno), /*在表级定义参照完整性*/
FOREIGN KEY (Cno) REFERENCES Course(Cno) /*在表级定义参照完整性*/
);
这里需要重新创建SC表,且要用到Course表,所以我先来删除刚刚创建的SC表并创建一张Course表:
DROP TABLE SC; /*删除上面的实体完整性时的例子创建的SC表*/
CREATE TABLE Course (
Cno CHAR(4) PRIMARY KEY,
Cname CHAR(40),
Cpno CHAR(4),
Ccredit SMALLINT,
FOREIGN KEY (Cpno) REFERENCES Course(Cno) /* 表级完整性约束条件,Cpno是外码,被参照表是自身*/
);
好了,现在可以创建该例子中的SC表了
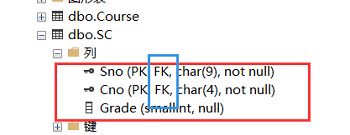
2. 参照完整性检查和违约处理
可能破坏参照完整性的情况及违约处理如下图:

比如:有下面2个关系
学生(学号,姓名,性别,专业号,年龄)
专业(专业号,专业名)
假设专业表中某个元组被删除,专业号为 12
按照设置为空值的策略,就要把学生表中专业号为12的所有元组的专业号设置为空值
对应语义:某个专业删除了,该专业的所有学生专业未定,等待重新分配专业
(如果不提前将其设置为空值的话因为有参照完整性的约束,系统会拒绝执行该删除操作)
来看例子: 显式说明参照完整性的违约处理示例:
CREATE TABLE SC (
Sno CHAR(9) NOT NULL,
Cno CHAR(4) NOT NULL,
Grade SMALLINT,
PRIMARY KEY(Sno, Cno),
FOREIGN KEY (Sno) REFERENCES Student(Sno)
ON DELETE CASCADE /*级联删除SC表中相应的元组*/
ON UPDATE CASCADE, /*级联更新SC表中相应的元组*/
FOREIGN KEY (Cno) REFERENCES Course(Cno)
ON DELETE NO ACTION /*当删除course 表中的元组造成了与SC表不一致时拒绝删除*/
ON UPDATE CASCADE /*当更新course表中的cno时,级联更新SC表中相应的元组*/
);
可以发现该SQL语句和之前的相比多出了:
ON DELETE CASCADE /*级联删除SC表中相应的元组*/
ON UPDATE CASCADE, /*级联更新SC表中相应的元组*/
ON DELETE NO ACTION /*当删除course 表中的元组造成了与SC表不一致时拒绝删除*/
ON UPDATE CASCADE /*当更新course表中的cno时,级联更新SC表中相应的元组*/
加上这样的描述之后可读性会更高一些,更容易去理解参照完整性~
三、用户定义的完整性
用户定义的完整性是:针对某一具体应用的数据必须满足的语义要求
1. 属性上的约束条件
CREATE TABLE时定义属性上的约束条件
① 列值非空(NOT NULL)
② 列值唯一(UNIQUE)
③ 检查列值是否满足一个条件表达式(CHECK)
— — — — — — — — — — — — — — — — — — — — — —
1)不允许取空值
来看例子: 在定义SC表时,说明Sno、Cno、Grade属性不允许取空值:
CREATE TABLE SC (
Sno CHAR(9) NOT NULL,
Cno CHAR(4) NOT NULL,
Grade SMALLINT NOT NULL,
/*PRIMARY KEY (Sno, Cno)*/
);
注意:如果在表级定义实体完整性(即定义了主码),隐含了Sno,Cno不允许取空值,所以在列级不允许取空值的定义可以不写(即定义了主码后主码的属性列不用再加NOT NULL)
— — — — — — — — — — — — — — — — — — — — — —
2)列值唯一
来看例子: 建立部门表DEPT,要求部门名称Dname列取值唯一,部门编号Deptno列为主码:
CREATE TABLE DEPT (
Deptno NUMERIC(2),
Dname CHAR(9) UNIQUE NOT NULL, /*Dname列值唯一, 并且不能取空值*/
Location CHAR(10),
PRIMARY KEY (Deptno)
);
(这里注意一下:唯一就隐含着不为空的条件,因为如果能为空值的话,那如果存在多个NULL,不就不满足唯一这个条件了吗,所以当题目要求唯一时注意隐含条件还有不为空)
— — — — — — — — — — — — — — — — — — — — — —
3)用CHECK短语指定列值应该满足的条件
来看例子: Student表的Ssex只允许取“男”或“女”:
CREATE TABLE Student (
Sno CHAR(9) PRIMARY KEY,
Sname CHAR(8) NOT NULL,
Ssex CHAR(2) CHECK (Ssex IN ('男', '女')), /*性别属性Ssex只允许取'男'或'女' */
Sage SMALLINT,
Sdept CHAR(20)
);
Another one: SC表的Grade的值应该在0和100之间:
CREATE TABLE SC (
Sno CHAR(9),
Cno CHAR(4),
Grade SMALLINT CHECK (Grade >= 0 AND Grade <= 100), /*Grade取值范围是0到100*/
PRIMARY KEY (Sno, Cno),
FOREIGN KEY (Sno) REFERENCES Student(Sno),
FOREIGN KEY (Cno) REFERENCES Course(Cno)
);
可见CHECK短语还是很有用的,防止用户输入一些不相关的产生坏的影响的数据。
2. 元组上的约束条件
① 元组上的约束条件的定义:
在CREATE TABLE时可以用CHECK短语定义元组上的约束条件,即元组级的限制
来看例子: 当学生的性别是男时,其名字不能以Ms.打头:
CREATE TABLE Student (
Sno CHAR(9),
Sname CHAR(8) NOT NULL,
Ssex CHAR(2),
Sage SMALLINT,
Sdept CHAR(20),
PRIMARY KEY (Sno),
CHECK (Ssex = '女' OR Sname NOT LIKE 'Ms.%') /*定义了元组中Sname和 Ssex两个属性值之间的约束条件*/
);
性别是女的元组都能通过该项检查,因为Ssex = '女’成立,当性别是男性时,要通过检查则名字一定不能以Ms.打头(%是模糊匹配中的一个通配符,它表示的是一串任意字符,而另一个通配符_表示一个任意字符)
② 元组上的约束条件检查和违约处理:
· 插入元组或修改属性的值时,关系数据库管理系统检查元组上的约束条件是否被满足
· 如果不满足则操作被拒绝执行
四、完整性约束命名字句
1. 完整性约束命名子句
CONSTRAINT <完整性约束条件名><完整性约束条件>
<完整性约束条件>包括NOT NULL、UNIQUE、PRIMARY KEY短语、FOREIGN KEY短语、CHECK短语等
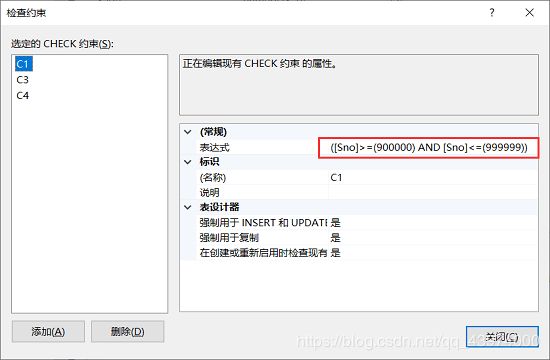
来看例子: 建立学生登记表Student,要求学号在90000~99999之间,姓名不能取空值,年龄小于30,性别只能是 “男”或“女”:
CREATE TABLE Student (
Sno NUMERIC(6)
CONSTRAINT C1 CHECK (Sno BETWEEN 90000 AND 99999),
Sname CHAR(20)
CONSTRAINT C2 NOT NULL,
Sage NUMERIC(3)
CONSTRAINT C3 CHECK (Sage < 30),
Ssex CHAR(2)
CONSTRAINT C4 CHECK (Ssex IN ('男', '女')),
CONSTRAINT StudentKey PRIMARY KEY(Sno)
);
在Student表上建立了5个约束条件,包括主码约束(命名为StudentKey)以及C1、C2、C3、C4四个列级约束
约束条件可以直接写在后面为什么还要加上CONSTRAINT?
嘿嘿,因为直接写在后面的约束条件是系统自己分配的约束,不容易找和用,这样加上CONSTRAINT和名字后自己知道给哪一个约束起了什么名,还是挺方便的~
Another one: 建立教师表TEACHER,要求每个教师的应发工资不低于3000元。应发工资是工资列Sal与扣除项Deduct之和:
CREATE TABLE TEACHER (
Eno NUMERIC(4) PRIMARY KEY, /*在列级定义主码*/
Ename CHAR(10),
Job CHAR(8),
Sal NUMERIC(7, 2),
Deduct NUMERIC(7, 2),
Deptno NUMERIC(2),
CONSTRAINT TEACHERFKey FOREIGN KEY (Deptno) REFERENCES DEPT(Deptno),
CONSTRAINT C1 CHECK (Sal + Deduct >= 3000)
);
可见约束条件还可以是一个表达式,不得不说挺好用的~
2. 修改表中的完整性限制
使用ALTER TABLE语句修改表中的完整性限制
来看例子: 去掉例5.10 Student表中对性别的限制:
ALTER TABLE Student
DROP CONSTRAINT C4;
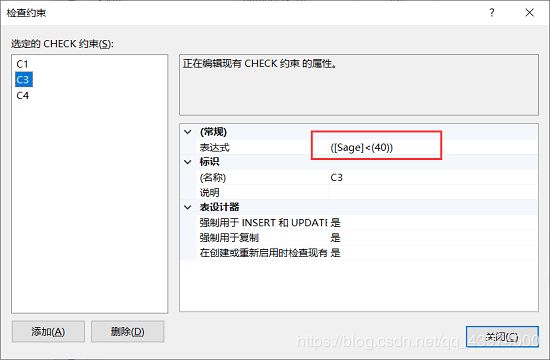
Another one: 修改表Student中的约束条件,要求学号改为在900000~999999之间,年龄由小于30改为小于40:
ps:因为没有功能是修改约束条件的SQL语句,所以可以先删除原来的约束条件,再增加新的约束条件来实现修改的功能~
ALTER TABLE Student
DROP CONSTRAINT C1;
ALTER TABLE Student
ADD CONSTRAINT C1 CHECK (Sno BETWEEN 900000 AND 999999);
ALTER TABLE Student
DROP CONSTRAINT C3;
ALTER TABLE Student
ADD CONSTRAINT C3 CHECK(Sage < 40);
可看到修改成功啦!!
五、触发器
触发器(Trigger):
① 任何用户对表的增、删、改操作均由服务器自动激活相应的触发器
② 触发器可以实施更为复杂的检查和操作,具有更精细和更强大的数据控制能力
1. 定义触发器
CREATE TRIGGER语法格式:
CREATE TRIGGER <触发器名>
{BEFORE | AFTER} <触发事件> ON <表名>
REFERENCING NEW|OLD ROW AS<变量>
FOR EACH {ROW | STATEMENT}
[WHEN <触发条件>]<触发动作体>
· 当特定的系统事件发生时,对规则的条件进行检查
· 如果条件成立则执行规则中的动作,否则不执行该动作
· 规则中的动作体可以很复杂,通常是一段SQL存储过程
— — — — — — — — — — — — — — — — — —
触发事件:
① 触发事件可以是INSERT、DELETE或UPDATE,也可以是这几个事件的组合
② 还可以UPDATE OF<触发列,…>,即进一步指明修改哪些列时激活触发器
③ AFTER/BEFORE是触发的时机
· AFTER表示在触发事件的操作执行之后激活触发器
· BEFORE表示在触发事件的操作执行之前激活触发器
— — — — — — — — — — — — — — — — — —
ps:AS后的<变量>在这里相当于是起了个别名一样的,只是在这个过程中使用
触发器类型:
· 行级触发器(FOR EACH ROW)
· 语句级触发器(FOR EACH STATEMENT)
例如,在上面的完整性约束命名子句的例子中的TEACHER表上创建一个AFTER UPDATE触发器,触发事件是UPDATE语句:
UPDATE TEACHER SET Deptno = 5;
假设TEACHER表有1000行:
如果是语句级触发器,那么执行完该语句后,触发动作只发生1次
如果是行级触发器,触发动作将执行1000次(即有多少行就执行多少次)
(注意:不同的RDBMS产品触发器语法各不相同)
— — — — — — — — — — — — — — — — — —
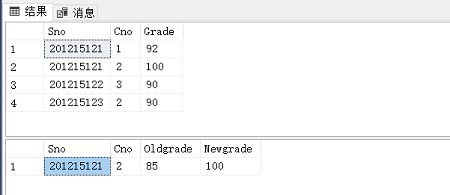
来看例子: 当对表SC的Grade属性进行修改时,若分数增加了10%则将此次操作记录到下面表中:
SC_U(Sno, Cno, Oldgrade, Newgrade),其中Oldgrade是修改前的分数,Newgrade是修改后的分数。
(注意做这个例子前先给Student、Course、SC表都要添加上数据~)
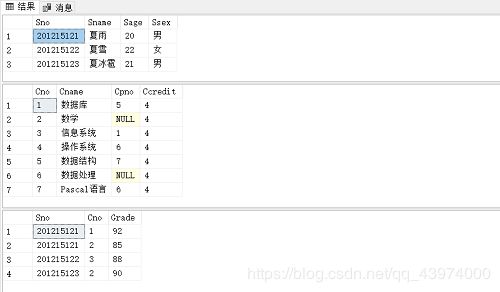
在新建触发器前可以新建一个表用于记录其修改的记录(虽然没有日志记录的详细,但是这里该表的作用其实就相当于日志啦,将激活了触发器的记录给记录下来)
CREATE TABLE SC_U (
Sno CHAR(9),
Cno CHAR(4),
Oldgrade SMALLINT, /*因为SC表中Grade数据类型为SMALLINT,所以这里与其相同设置*/
Newgrade SMALLINT
)
CREATE TRIGGER SC_T
AFTER UPDATE OF Grade ON SC
REFERENCING
OLD row AS OldTuple,
NEW row AS NewTuple
FOR EACH ROW
WHEN (NewTuple.Grade >= 1.1 * OldTuple.Grade) /*题目中分数增加10%,就等同于这里的 >= 旧的分数*1.1 */
INSERT INTO SC_U(Sno, Cno, OldGrade, NewGrade)
VALUES(OldTuple.Sno, OldTuple.Cno, OldTuple.Grade, NewTuple.Grade)

看来T-SQL是不支持该写法的,查阅了官方文档我了解到以下内容:
— — — — — — — — — — — — — — — — — — — — —
T-SQL可创建 DML、DDL 或登录触发器(分为三种)
触发器是一种特殊类型的存储过程,在数据库服务器中发生事件时自动运行。
① 如果用户尝试通过数据操作语言 (DML) 事件修改数据,DML 触发器运行。 DML 事件是针对表或视图的 INSERT、UPDATE 或 DELETE 语句。 此类触发器在任何有效事件触发时触发,无论表行是否受影响。
② DDL 触发器是为了响应各种数据定义语言 (DDL) 事件而运行。 这些事件主要对应于 Transact-SQL CREATE、ALTER 和 DROP 语句,以及执行类似 DDL 操作的某些系统存储过程。
③ 登录触发器是为了响应在建立用户会话时触发的 LOGON 事件而触发。
可以直接使用 Transact-SQL 语句创建触发器,也可以使用程序集方法,可以为任何特定语句创建多个触发器。
— — — — — — — — — — — — — — — — — — — — —
该例题中涉及的是DML事件,所以应创建DML触发器,可使用SSMS和T-SQL两种办法来创建,这里我采用T-SQL方法,想看SSMS创建的小伙伴可查看官方文档:创建 DML 触发器
了解后该例题应改写为:
CREATE TRIGGER SC_T
ON SC
FOR UPDATE
AS /*声明变量*/
declare @OLD SMALLINT
declare @NEW SMALLINT
declare @SNO CHAR(9)
declare @CNO CHAR(4)
IF(UPDATE(Grade))
BEGIN
select @OLD = Grade FROM DELETED
select @NEW = Grade FROM INSERTED
select @SNO = Sno FROM DELETED
select @CNO = Cno FROM DELETED
IF(@NEW >= 1.1 * @OLD)
INSERT INTO SC_U(Sno, Cno, Oldgrade, Newgrade)
VALUES (@SNO, @CNO, @OLD, @NEW)
END;
ps:DML 触发器使用 deleted 和 inserted 逻辑(概念)表。 它们在结构上类似于定义了触发器的表,即尝试对其执行用户操作的表。 deleted 和 inserted 表保存了可能会被用户更改的行的旧值或新值。
· 咱们现在来测试一下刚刚新建的触发器:
先看看SC表长啥样:

UPDATE SC
SET Grade = 90
WHERE Sno='201215122' AND Cno='3';
UPDATE SC
SET Grade = 100
WHERE Sno='201215121' AND Cno='2';
SELECT * FROM SC;
SELECT * FROM SC_U;
bingo~ 成功啦✌
Another one: 将每次对表Student的插入操作所增加的学生个数记录到表StudentInsertLog中:
-- 同样的,先新建一个表StudentInsertLog存储学生人数
CREATE TABLE StudentInsertLog (
Numbers INT
)
-- 再新建一个表存储用户名和操作时间
CREATE TABLE StudentInsertLogUser (
UserName nchar(10),
DateAndTime datetime
)
-- 新建触发器Student_Count
CREATE TRIGGER Student_Count
AFTER INSERT ON Student
REFERENCING
NEW TABLE AS DELTA
FOR EACH STATEMENT
INSERT INTO StudentInsertLog (Numbers)
SELECT COUNT(*) FROM DELTA
以上是标准SQL的写法,在SQL Server运行时新建触发器是会报错的,所以应采用下面的T-SQL写法:
-- 先新建一个表存储学生人数
CREATE TABLE StudentInsertLog (
Numbers INT
)
-- 再新建一个表存储用户名和操作时间
CREATE TABLE StudentInsertLogUser (
UserName nchar(10),
DateAndTime datetime
)
-- 新建触发器Student_Count
-- 当插入新的学生记录时,触发器执行,自动在StudentInsertLog记录学生人数
CREATE TRIGGER Student_Count
ON Student
AFTER INSERT
AS
INSERT INTO StudentInsertLog(Numbers)
SELECT COUNT(*) FROM Student
-- 当插入新的学生记录时,触发器启动,自动在StudentInsertLogUser记录用户名和操作时间
CREATE TRIGGER Student_Time
ON Student
AFTER INSERT
AS
declare @UserName nchar(10)
declare @DateTime datetime
select @UserName = system_user
select @DateTime = CONVERT(datetime, GETDATE(), 120)
INSERT INTO StudentInsertLogUser(UserName, DateAndTime)
VALUES(@UserName, @DateTime)
-- 查看该触发器的效果
INSERT
INTO Student
VALUES ('201215124', 'Henry', 20, '男');
SELECT * FROM Student;
SELECT * FROM StudentInsertLog;
SELECT * FROM StudentInsertLogUser;
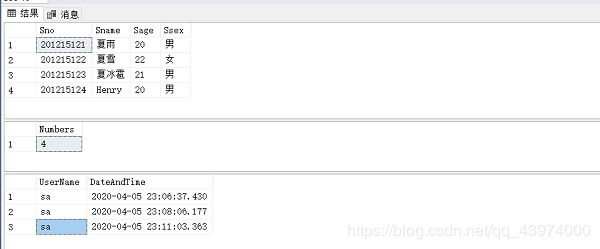
嘿嘿,这里用户名和操作时间的记录有三条是因为我一开始忘记新建触发器Student_Count来记录学生人数了,我说为啥人数那里一直没有反应,hhh,第二次测试后发现了,所以删了Henry记录后重新插入记录在了Student_Time表的第三行。
对了,刚刚新建好的触发器在Student表里找,因为创建时ON Student即创建在了Student表内:

Another one: 定义一个BEFORE行级触发器,为教师表Teacher定义完整性规则“教授的工资不得低于4000元,如果低于4000元,自动改为4000元”:
(同样的,在进行该实验前需要给Teacher表添加好数据)
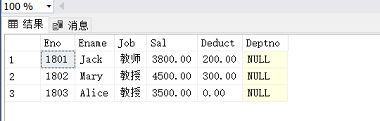
(ps:表中的Deduct指的是扣除的费用)
-- 标准SQL
CREATE TRIGGER Insert_Or_Update_Sal
BEFORE INSERT OR UPDATE ON Teacher /*触发事件是插入或更新操作*/
FOR EACH ROW /*行级触发器*/
BEGIN /*定义触发动作体,是PL/SQL过程块*/
IF (new.Job = '教授') AND (new.Sal < 4000)
THEN new.Sal := 4000;
END IF;
END;
-- T-SQL
CREATE TRIGGER Insert_Or_Update_Sal
ON Teacher
FOR UPDATE, INSERT
AS
IF UPDATE(Sal)
BEGIN
declare @JOB CHAR(9)
declare @SAL SMALLINT
select @SAL = Sal FROM INSERTED
select @JOB = Job FROM Teacher
IF(@SAL < 4000 AND @JOB = '教授')
UPDATE Teacher
SET SAL = 4000
WHERE Sal < 4000 AND Job = '教授'
END;
-- 测试刚刚新建好的触发器Insert_Or_Update_Sal
INSERT
INTO Teacher
VALUES('1804', 'Pete', '教授', 3900, 0, NULL);
SELECT * FROM Teacher;
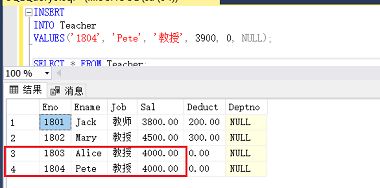
可看到Alice和Pete都是教授且工资不足4000,执行触发器后工资均调整为4000~
2. 激活触发器
触发器的执行,是由触发事件激活的,并由数据库服务器自动执行!
一个数据表上定义了多个触发器时,遵循如下的执行顺序:
① 执行该表上的BEFORE触发器
② 激活触发器的SQL语句
③ 执行该表上的AFTER触发器
3. 删除触发器
删除触发器的SQL语法:
DROP TRIGGER <触发器名> ON <表名>;
不过在T-SQL中这样写是不对的,如果是删除DML触发器的话去掉ON <表名>就可以:
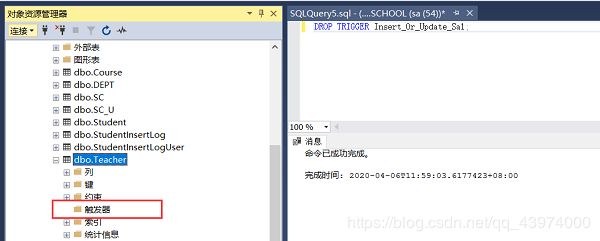
因为标准SQL和T-SQL在触发器这一块有很多出入,删除触发器具体可参考官方文档:DROP TRIGGER (Transact-SQL)
六、浅谈存储过程
这里将此内容提前放到这里写啦,有一些相关性
存储过程: 由过程化SQL语句,经编译和优化后存储在数据库服务器中,可以被反复调用,运行速度较快
其优点是:
① 运行效率高
② 降低了客户机和服务器之间的通信量
③ 方便实施企业规则
— — — — — — — — — — — — — — — —
1)创建存储过程:
CREATE OR REPLACE PROCEDURE 过程名([参数1,参数2,...]) AS <过程化SQL块>;
2)执行存储过程:
CALL/PERFORM PROCEDURE 过程名([参数1,参数2,...]);
使用CALL或者PERFORM等方式激活存储过程的执行
数据库服务器支持在过程体中调用其他存储过程
来看例子: 利用存储过程来实现下面的应用:从账户1转指定数额的款项到账户2中:
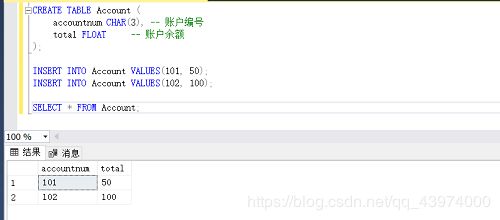
Step 1:建立新表Account,并写入两个用户:
DROP TABLE IF EXISTS Account;
CREATE TABLE Account (
accountnum CHAR(3), -- 账户编号
total FLOAT -- 账户余额
);
INSERT INTO Account VALUES(101, 50);
INSERT INTO Account VALUES(102, 100);
SELECT * FROM Account;
Step 2:创建存储过程:
IF (exists (select * from sys.objects where name = 'Proc_TRANSFER'))
DROP PROCEDURE Proc_TRANSFER
GO
CREATE PROCEDURE Proc_TRANSFER
@inAccount INT, @outAccount INT, @amount FLOAT
/*定义存储过程TRANSFER,参数为转入账户、转出账户、转账额度*/
AS
BEGIN TRANSACTION TRANS
DECLARE /*定义变量*/
@totalDepositOut Float,
@totalDepositIn Float,
@inAccountnum INT;
/*检查转出账户的余额 */
SELECT @totalDepositOut = total FROM Account WHERE accountnum = @outAccount;
/*如果转出账户不存在或账户中没有存款*/
IF @totalDepositOut IS NULL
BEGIN
PRINT '转出账户不存在或账户中没有存款'
ROLLBACK TRANSACTION TRANS; /*回滚事务*/
RETURN;
END;
/*如果账户存款不足*/
IF @totalDepositOut < @amount
BEGIN
PRINT '账户存款不足'
ROLLBACK TRANSACTION TRANS; /*回滚事务*/
RETURN;
END
/*检查转入账户的状态 */
SELECT @inAccountnum = accountnum FROM Account WHERE accountnum = @inAccount;
/*如果转入账户不存在*/
IF @inAccountnum IS NULL
BEGIN
PRINT '转入账户不存在'
ROLLBACK TRANSACTION TRANS; /*回滚事务*/
RETURN;
END;
/*如果条件都没有异常,开始转账。*/
BEGIN
UPDATE Account SET total = total - @amount WHERE accountnum = @outAccount; /* 修改转出账户余额,减去转出额 */
UPDATE Account SET total = total + @amount WHERE accountnum = @inAccount; /* 修改转入账户余额,增加转入额 */
PRINT '转账完成,请取走银行卡'
COMMIT TRANSACTION TRANS; /* 提交转账事务 */
RETURN;
END;
Step 3:执行存储过程:
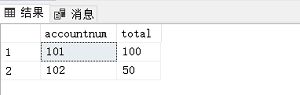
EXEC Proc_TRANSFER
@inAccount = 101, --转入账户
@outAccount = 102, --转出账户
@amount = 50 --转出金额
SELECT * FROM Account;
语义即:从账户102转50元到账户101。原先账户102有100块,账户101有50块,执行存储过程后两人的余额正好反过来了:
以上测试是条件没有异常的情况,现在测试一下余额不足、转入账户不存在、转出账户不存在的情况:
-- 余额不足
EXEC Proc_TRANSFER
@inAccount = 101, --转入账户
@outAccount = 102, --转出账户
@amount = 520 --转出金额
-- 转入账户不存在
EXEC Proc_TRANSFER
@inAccount = 666, --转入账户
@outAccount = 102, --转出账户
@amount = 520 --转出金额
-- 转出账户不存在情况
EXEC Proc_TRANSFER
@inAccount = 102, --转入账户
@outAccount = 222, --转出账户
@amount = 520 --转出金额
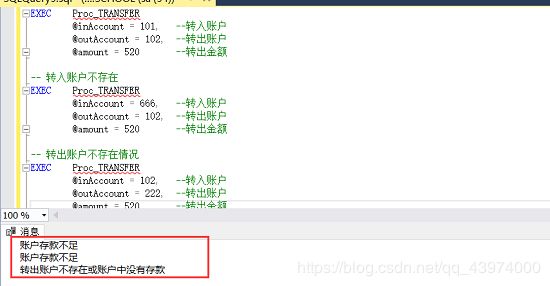
咦,第二个跟我们想得到的结果不一样,原因是我们创建该存储过程时是先判断余额再判断转入账户是否存在的,所以在创建存储过程时要注意判断情况的顺序根据需求来安排~
Another one: 从账户01003815868转52000元到01003813828账户中:
CALL PROCEDURE TRANSFER(01003813828, 01003815868, 10000);
有了上一个例题的经验,T-SQL应改写为:
(注意因为上面创建Account表时账户的数据类型是char(3),这里需要先修改类型(或长度)后再插入数据)
-- 先创建题中需要的两个账户及其余额
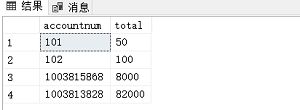
INSERT INTO Account VALUES(01003815868,60000);
INSERT INTO Account VALUES(01003813828,30000);
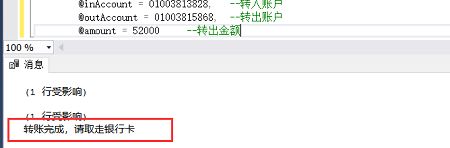
EXEC Proc_TRANSFER
@inAccount = 01003813828, --转入账户
@outAccount = 01003815868, --转出账户
@amount = 52000 --转出金额
SELECT * FROM Account;
3)修改存储过程:
ALTER { PROC | PROCEDURE } [schema_name.] procedure_name
[ { @parameterdata_type } [= ] ] [ ,...n ]
AS { [ BEGIN ] sql_statement [ ; ] [ ,...n ] [ END ] }
[;]
修改和创建相比不同的地方就是创建的CREATE改为了ALTER,其他地方写法一样~可参考上面的创建例题,将CREATE改为ALTER,修改需要改动的地方即可
4)删除存储过程:
DROP PROCEDURE 过程名();
我以删除刚刚的存储过程Proc_TRANSFER 为例,执行删除语句后刷新SCHOOL数据库

这是新建好的时候的截图,对比可见存储过程Proc_TRANSFER删除成功!
嘿嘿,数据库的完整性总算整理完啦~ 因为T-SQL中没有断言ASSERTION,所以本文没有做相关的介绍,感谢阅读~
如文中有不恰当的地方,望提出指正~
- 相关推荐:【吐血整理】数据库的安全性
- 安利一下:SQL Server 创建登录名和用户名【详细介绍】