DP学习手记——线性回归分类器
深度学习实际上是通过将数据进行多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示后,用“简单模型”即可完成复杂的分类等学习任务。由此可将深度学习理解为进行“特征学习”(feature learning)或“表示学习”(representation learning)。简单来说,深度学习解决的是复杂的的分类问题。
在对数据进行二分类的最直接有效的方法是线性回归分类器,所以在真正进行深度学习的学习之前,先做一个线性回归分类器对数据进行分类并与人工神经网络进行比较,是一件比较有意义的事。
线性回归的知识我们在中学以及高数中已经学过,在此就不多做赘述了,在我认为有必要进行解释的部分我会将其放在代码的注释中,个人认为在例程中学习效率会比较高,所以就直接上代码了。
线性回归分类器`
1、导入python包:
import numpy as np
from sklearn import datasets, linear_model
import matplotlib.pyplot as plt2、准备数据集:
np.random.seed(0)
X,y=datasets.make_moons(300,noise=0.25)
#300个数据,噪声设置为0.25,其中X为数据集,y为标签集
plt.scatter(X[:,0],X[:,1],s=50,c=y,edgecolors="Black")#绘制散点图
plt.title('Medical
data')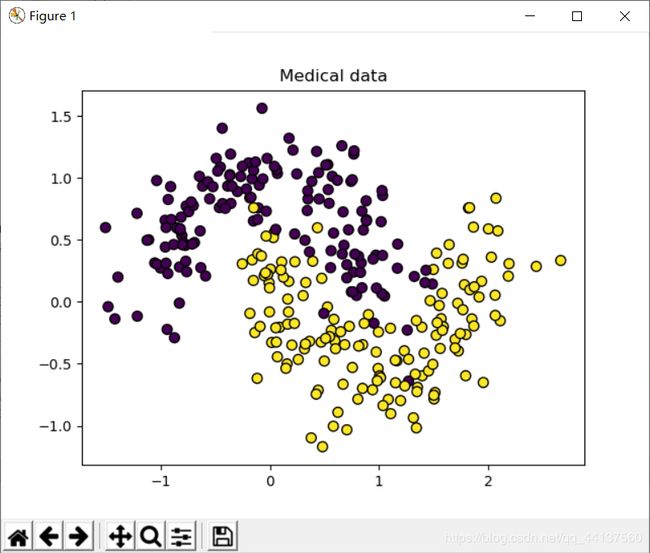
3、分类与绘制边界函数:
ef plot_boundary(pred_func,data,labels):
'''绘制分类边界函数'''
#设置最大值和最小值并增加0.5的边界
x_min,x_max=data[:,0].min()-0.5,data[:,0].max()+0.5
y_min, y_max = data[:, 1].min()
- 0.5, data[:, 1].max() + 0.5
h=0.01#点阵间距
#生成一个点阵网络,点阵间距为h
xx,yy=np.meshgrid(np.arange(x_min,x_max,h),np.arange(y_min,y_max,h))
#计算分类结果z
z=pred_func(np.c_[xx.ravel(),yy.ravel()]) #预测函数,实际上为lambda函数
z=z.reshape(xx.shape)
#绘制轮廓和训练样本,轮廓颜色使用Blues 透明度为0.2
plt.contourf(xx,yy,z,cmap=plt.cm.Blues,alpha=0.2)#绘制轮廓
plt.scatter(data[:,0],data[:,1],s=40,c=labels,edgecolors="Black")#绘制散点图
输入:
pred_func:预测函数,即分类器
Data:数据集
Labels:标签
4、线性分类函数:
clf=linear_model.LogisticRegressionCV()#使用sklearn的线性回归分类器
clf.fit(X,y) #实例化clf线性回归器
plot_boundary(lambda x: clf.predict(x),X,y)
plt.title('Logistic data')
plt.show()
结果如图所示:

如图所示,该分类结果远不能满足真实目的,因为其约有30%的分类错误,对项目需求而言,完全不能接受。