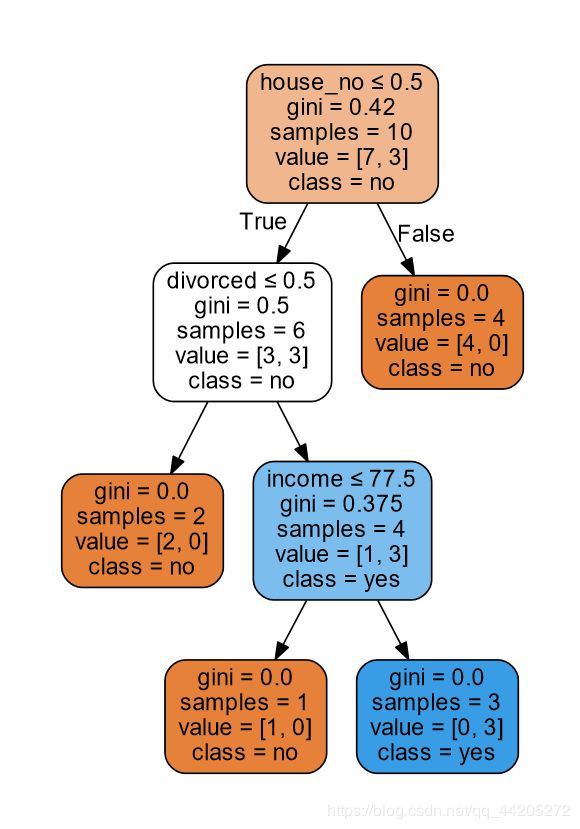
CART算法
Gini指数

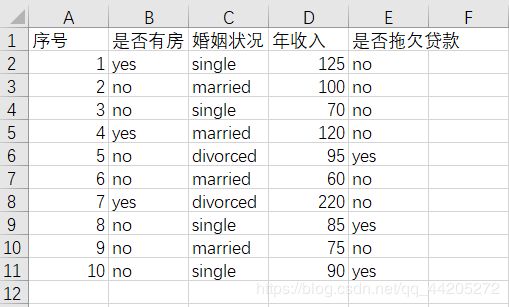
我们对以下数据进行分类



from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
import numpy as np
tree_1 = open('D:/数据/决策树2.csv', encoding='utf-8')
tree_data = csv.reader(tree_1)
headers = tree_data.__next__()
print(headers)
featureList = []
labelList = []
incomeList = []
for row in tree_data:
labelList.append(row[-1])
incomeList.append(row[-2])
rowDict = {}
for i in range(1, len(row)-2):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
print(featureList)
vec = DictVectorizer()
x_data = vec.fit_transform(featureList).toarray()
x_data_list = x_data.tolist()
for i in range(len(x_data_list)):
x_data_list[i].append(int(incomeList[i]))
x_data = np.array(x_data_list)
print(x_data)
print(vec.get_feature_names())
print(str(labelList))
label = preprocessing.LabelBinarizer()
y_data = label.fit_transform(labelList)
print(str(y_data))
model = tree.DecisionTreeClassifier()
model.fit(x_data, y_data)
x_text = x_data[0]
print("x_text:", str(x_text))
predict = model.predict(x_text.reshape(1, -1))
print("predict:", predict)
import graphviz
data = tree.export_graphviz(
model,
out_file=None,
feature_names=['house_yes', 'house_no', 'single', 'divorced', 'married', 'income'],
class_names=label.classes_,
filled=True,
rounded=True,
special_characters=True
)
graph = graphviz.Source(data)
graph.render('computer2')
'''
['\ufeff序号', '是否有房', '婚姻状况', '年收入', '是否拖欠贷款']
[{'是否有房': 'yes', '婚姻状况': 'single'}, {'是否有房': 'no', '婚姻状况': 'married'}, {'是否有房': 'no', '婚姻状况': 'single'}, {'是否有房': 'yes', '婚姻状况': 'married'}, {'是否有房': 'no', '婚姻状况': 'divorced'}, {'是否有房': 'no', '婚姻状况': 'married'}, {'是否有房': 'yes', '婚姻状况': 'divorced'}, {'是否有房': 'no', '婚姻状况': 'single'}, {'是否有房': 'no', '婚姻状况': 'married'}, {'是否有房': 'no', '婚姻状况': 'single'}]
[[ 0. 0. 1. 0. 1. 125.]
[ 0. 1. 0. 1. 0. 100.]
[ 0. 0. 1. 1. 0. 70.]
[ 0. 1. 0. 0. 1. 120.]
[ 1. 0. 0. 1. 0. 95.]
[ 0. 1. 0. 1. 0. 60.]
[ 1. 0. 0. 0. 1. 220.]
[ 0. 0. 1. 1. 0. 85.]
[ 0. 1. 0. 1. 0. 75.]
[ 0. 0. 1. 1. 0. 90.]]
['婚姻状况=divorced', '婚姻状况=married', '婚姻状况=single', '是否有房=no', '是否有房=yes']
['no', 'no', 'no', 'no', 'yes', 'no', 'no', 'yes', 'no', 'yes']
[[0]
[0]
[0]
[0]
[1]
[0]
[0]
[1]
[0]
[1]]
x_text: [ 0. 0. 1. 0. 1. 125.]
predict: [0]
'''