kylin_大数据数仓项目-点击流分析
文章目录
- 用户行为日志
- 1 日志数据格式
- 2 数据仓库-ETL处理
- 点击流概念
- 点击流模型pageviews
- 点击流模型visit
- 3 数据入库
- 1. 创建ODS层数据表
- 1.1. 原始日志数据表
- 1.2.点击流模型
- 1.3. 点击流visit模型表
用户行为日志
1 日志数据格式
日志数据内容样例
f5dd685d-6b83-4e7d-8c37-df8797812075 222.68.172.190 - - 2018-11-01 14:34:57 "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
字段解析:
- 1 、用户id信息-uid: f5dd685d-6b83-4e7d-8c37-df8797812075
- 2、访客ip地址: 222.68.172.190
- 3、访客用户信息: - -
- 4、请求时间:2018-11-01 14:34:57
- 5、请求方式:GET
- 6、请求的url:/images/my.jpg
- 7、请求所用协议:HTTP/1.1
- 8、响应码:200
- 9、返回的数据流量:19939
- 10、访客的来源url:
http://www.angularjs.cn/A00n - 11、访客所用浏览器:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36
注意:分隔符为空格
2 数据仓库-ETL处理
点击流概念
- 点击流(Click Stream)是指用户在网站上持续访问的轨迹。注重用户浏览网站的整个流程。用户对网站的每次访问包含了一系列的点击动作行为,这些点击行为数据就构成了点击流数据(Click Stream Data),它代表了用户浏览网站的整个流程。
- 点击流和网站日志是两个不同的概念,点击流是从用户的角度出发,注重用户浏览网站的整个流程;而网站日志是面向整个站点,它包含了用户行为数据、服务器响应数据等众多日志信息,我们通过对网站日志的分析可以获得用户的点击流数据。
- 点击流模型完全是业务模型,相关概念由业务指定而来。由于大量的指标统计从点击流模型中更容易得出,所以在预处理阶段,可以使用spark程序来生成点击流模型的数据。
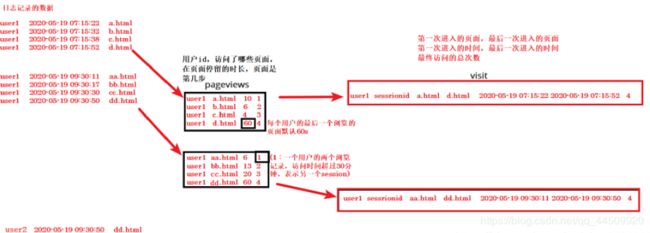
- 在点击流模型中,存在着两种模型数据:PageViews、Visits。
点击流模型pageviews
Pageviews模型数据专注于用户每次会话(session)的识别,以及每次session内访问了几步和每一步的停留时间。
在日志数据分析中,通常把前后两条访问记录时间差在30分钟以内算成一次会话。如果超过30分钟,则把下次访问算成新的会话开始。
- 大致步骤如下:
在所有访问日志中找出该用户的所有访问记录
把该用户所有访问记录按照时间正序排序
计算前后两条记录时间差是否为30分钟
如果小于30分钟,则是同一会话session的延续
如果大于30分钟,则是下一会话session的开始
用前后两条记录时间差算出上一步停留时间
最后一步和只有一步的 业务默认指定页面停留时间60s
点击流模型visit
Visit模型专注于每次会话session内起始、结束的访问情况信息。比如用户在某一个会话session内,进入会话的起始页面和起始时间,会话结束是从哪个页面离开的,离开时间,本次session总共访问了几个页面等信息。
- 大致步骤如下:
在pageviews模型上进行梳理
在每一次回收session内所有访问记录按照时间正序排序
第一天的时间页面就是起始时间页面
业务指定最后一条记录的时间页面作为离开时间和离开页面
3 数据入库
1. 创建ODS层数据表
1.1. 原始日志数据表
drop table if exists itcast_ods.ods_weblog_origin;
create table itcast_ods.ods_weblog_origin(
valid Boolean,
remote_addr string,
remote_user string,
time_local string,
request string,
status string,
body_bytes_sent string,
http_referer string,
http_user_agent string,
guid string)
partitioned by (dt string)
STORED AS PARQUET;
对应的字段
valid Boolean, --判断数据是否合法
remote_addr string, --记录客户端的ip地址
remote_user string, --记录客户端用户名称,忽略属性"-"
time_local string, --记录访问时间与时区
request string, --记录请求的url与http协议
status string, --记录请求状态;成功是200
body_bytes_sent string, --记录发送给客户端文件主体内容大小
http_referer string, --用来记录从那个页面链接访问过来的
http_user_agent string, --记录客户浏览器的相关
guid string) --用户id信息
注意事项:
parquet中字段数据类型要与hive表字段类型保持一致!
1.2.点击流模型
drop table if exists itcast_ods.ods_click_pageviews;
create table itcast_ods.ods_click_pageviews(
session string,
remote_addr string,
time_local string,
request string,
visit_step int,
page_staylong string,
http_referer string,
http_user_agent string,
body_bytes_sent string,
status string)
partitioned by (dt string)
STORED AS PARQUET;
对应的字段
session string, //session
remote_addr string, //ip地址
time_local string, //访问时间
request string, //请求路径
visit_step int, //访问第几个页面
page_staylong string, //停留时长
http_referer string, //用来记录从那个页面链接访问过来的
http_user_agent string, //记录客户浏览器的相关
body_bytes_sent string, //记录发送给客户端文件主体内容大小
status string //状态//用户ID
1.3. 点击流visit模型表
drop table if exist itcast_ods.ods_click_stream_visit;
create table itcast_ods.ods_click_stream_visit(
session string,
remote_addr string,
inTime string,
outTime string,
inPage string,
outPage string,
referal string,
pageVisits int)
partitioned by (dt string)
STORED AS PARQUET;
对应的字段
session string, //session
remote_addr string, //IP地址
inTime string, //进入时间
outTime string, //离开时间
inPage string, //进入的页面
outPage string, //离开的页面
referal string, //用来记录从那个页面链接访问过来的
pageVisits int) //访问页面数量
将原始的数据通过不同的预处理,将数据分别写入到ods的3个不同功能的表中
- DateUtil代码:
object ClicklogApp {
// 程序入口
def main(args: Array[String]): Unit = {
val pages: mutable.HashSet[String] = new mutable.HashSet[String]()
//初始化静态资源路径集合
def initlizePages(): Unit = {
pages.add("/about")
pages.add("/black-ip-list/")
pages.add("/cassandra-clustor/")
pages.add("/finance-rhive-repurchase/")
pages.add("/hadoop-family-roadmap/")
pages.add("/hadoop-hive-intro/")
pages.add("/hadoop-zookeeper-intro/")
pages.add("/hadoop-mahout-roadmap/")
}
/*
1、对数据进行预处理,过滤掉无效的数据,将有效的数据写入到hive表
*/
// 1. 初始化 spark session
val spark: SparkSession = SparkSession.builder().appName("Clicklog").master("local[*]").getOrCreate()
// 获取到SparkContext
val sc: SparkContext = spark.sparkContext
// 设置日志级别
sc.setLogLevel("WARN")
// 2. 读取数据
val logDatas: RDD[String] = sc.textFile("E://BigData//项目//0519//access.log.20181101.dat_new.bak")
// 3. 将每一条数据转换成WebLogBean
val webLogBeanRDD: RDD[WebLogBean] = logDatas.map(WebLogBean(_))
// 4. 对数据进行过滤(删除无效数据)
val activeWebLogBeans: RDD[WebLogBean] = webLogBeanRDD.filter(webLogBean => {
// 若bean不为空,并且数据有效,那么保留该数据。反之删除数据
if (webLogBean != null && webLogBean.valid) {
true
} else {
false
}
})
// 初始化静态数据
initlizePages()
// 5. 过滤静态数据
val noStaticActiveWebLogBeans: RDD[WebLogBean] = activeWebLogBeans.filter(activeWebLogBean => {
// 静态数据中包含用户访问的路径,表示这个数据是无效的
if (pages.contains(activeWebLogBean.request)) {
false
} else {
// 表示数据有效
true
}
})
// 导入隐式转换
import spark.implicits._
// 6. WebLogBean 转换成 WebLogBeanCase --> 因为WebLogBeanCase 的结构与最终存储数据的表结构相同
val weblogBeanCaseRDD: RDD[WeblogBeanCase] = noStaticActiveWebLogBeans.map(webLogBean => {
WeblogBeanCase(webLogBean.valid,
webLogBean.remote_addr,
webLogBean.remote_user,
webLogBean.time_local,
webLogBean.request,
webLogBean.status,
webLogBean.body_bytes_sent,
webLogBean.http_referer,
webLogBean.http_user_agent,
webLogBean.guid)
})
// // 7. 将数据写入到hive表
// val weblogBeanCaseDF: DataFrame = weblogBeanCaseRDD.toDF()
//
//
// // 将数据写入到HDFS
// weblogBeanCaseDF.write.mode("overwrite").parquet("hdfs://node01:8020/user/hive/warehouse/itcast_ods.db/ods_weblog_origin/dt=20191212")
/* 下面是点击流模型的计算 */
//1. 根据用户 ID 对数据进行分组
val userWebLogList: RDD[(String, Iterable[WeblogBeanCase])] = weblogBeanCaseRDD.groupBy(weblogBeanCase=>weblogBeanCase.guid)
//2. 得到的数据是一个用户的数据都在一起,按照浏览的时间排序 -》 某一个用户浏览的顺序数据
val pageViewsBeanCaseRDD: RDD[PageViewsBeanCase] = userWebLogList.flatMap(oneUserWebLog => {
// 一个用户的数据
// 获取用户的 useId
val userId: String = oneUserWebLog._1
// 获取到用户的浏览记录(排好序的记录)
val webLogList: List[WeblogBeanCase] = oneUserWebLog._2.toList.sortBy(_.time_local)
// 初始化Session
var session: String = UUID.randomUUID().toString
// 初始化用户访问的第几步
var setp: Int = 1
//初始化存储PageViewsBeanCase的list
var pageViewsBeanCaseList: ListBuffer[PageViewsBeanCase] = ListBuffer[PageViewsBeanCase]()
//导入隐式转化,下面需要使用到continue和break
import scala.util.control.Breaks._
//3. 遍历每个用户的数据
for (num <- 0 until (webLogList.size - 1)) {
// 获取当前的浏览记录
var cruurentWebLog: WeblogBeanCase = webLogList(num)
// 3.1 数据量可能为一条,浏览时间默认为60s
if (webLogList.size == 1) {
// 封装PageViewsBeanCase
val pageViewsBeanCase: PageViewsBeanCase = PageViewsBeanCase(session,
cruurentWebLog.remote_addr,
cruurentWebLog.time_local,
cruurentWebLog.request,
setp,
60 + "",
cruurentWebLog.http_referer,
cruurentWebLog.http_user_agent,
cruurentWebLog.body_bytes_sent,
cruurentWebLog.status,
cruurentWebLog.guid )
pageViewsBeanCase
// 将刚计算的 pageViewBeanCase 保存到PageViewsBeanCaseList【最终写入到HDFS】
pageViewsBeanCaseList += pageViewsBeanCase
//重新生成新的uuid
session = UUID.randomUUID().toString
} else {
// 若没有进入上面的 if 表示有多条数据
// 3.2 数据量有可能是多条 1 2 3 4 5
// 先获取第一条数据时间
// 若是第一条数据 我们跳过第一天 进入第二个循环 得到第二天数据
breakable {
if (num == 0) {
// num == 0 表示 这是第一天的数据
// 跳过第一天
break()
}
// 先获取到上一次记录的时间(因为第一天已经跳过,cruurentWebLog 为第二天条的数据)
val upDataTime: String = webLogList(num - 1).time_local
// 获取到这一次记录的时间
val nextDataTime: String = cruurentWebLog.time_local
// 求两个界面的时间差
// 第二条数据的时间 - 第一条数据的时间 = 第一个页面的停留时长
val diffTime: Long = DateUtil.getTimeDiff(upDataTime, nextDataTime)
//获取上一个数据的 WeblogBeanCase
val upWeblogBean: WeblogBeanCase = webLogList(num - 1)
if (diffTime < 30 * 60 * 1000) {
// 3.2.1 两个数据之间的间隔在30分钟之内
// 封装PageViewsBeanCase ,这个PageViewsBeanCase 是第一天数据的PageViewsBeanCase
val beanCase: PageViewsBeanCase = PageViewsBeanCase(session, upWeblogBean.remote_addr, upWeblogBean.time_local, upWeblogBean.request,
setp, diffTime + "", upWeblogBean.http_referer, upWeblogBean.http_user_agent, upWeblogBean.body_bytes_sent,
upWeblogBean.status, upWeblogBean.guid)
// 添加到结果集
pageViewsBeanCaseList += beanCase
// session不需要更新
setp += 1
} else {
// 3.2.2 两个数据之间的间隔超过30分钟,换另外一个session会话
//封装PageViewsBeanCase
val beanCase: PageViewsBeanCase = PageViewsBeanCase(session, upWeblogBean.remote_addr, upWeblogBean.time_local, upWeblogBean.request,
setp, 60 + "", upWeblogBean.http_referer, upWeblogBean.http_user_agent, upWeblogBean.body_bytes_sent,
upWeblogBean.status, upWeblogBean.guid)
//添加到结果集
pageViewsBeanCaseList += beanCase
//为下一个会话准备数据
//session需要更新
//重新生成session
session = UUID.randomUUID().toString
//sept 归1
setp = 1
}
//最后一条数据
if (webLogList.size - 1 == num) {
//3.3最后一条数据 浏览时间默认60s
//封装PageViewsBeanCase
val lastViewsBeanCase: PageViewsBeanCase = PageViewsBeanCase(session, cruurentWebLog.remote_addr, cruurentWebLog.time_local, cruurentWebLog.request,
setp, 60 + "", cruurentWebLog.http_referer, cruurentWebLog.http_user_agent, cruurentWebLog.body_bytes_sent,
cruurentWebLog.status, cruurentWebLog.guid
)
//添加到结果集
pageViewsBeanCaseList += lastViewsBeanCase
}
}
}
}
pageViewsBeanCaseList
}
)
//每个用户的最终
//写入Hive itcast_ods.ods_click_pageviews
//pageViewsBeanCaseRDD.toDF().write.mode("overwrite").parquet("hdfs://node01:8020/user/hive/warehouse/itcast_ods.db/ods_click_pageviews/dt=20191212/")
/* 下面是点击流visit模型表的计算 */
// 1. 根据session 对数据进行分组
val sessionGroupDatas: RDD[(String, Iterable[PageViewsBeanCase])] = pageViewsBeanCaseRDD.groupBy(bean=>bean.session)
// 2. 获取到一个session内有哪些页面
val visitBeanCaseRDD: RDD[VisitBeanCase] = sessionGroupDatas.map(pageViewsBeanCase => {
// 获取到session
val session: String = pageViewsBeanCase._1
// 3. 获取到PageViewsBeanCase的集合,对一个会话内的数据进行排序 [按照步骤排序]
val pageViewsBeanCases: List[PageViewsBeanCase] = pageViewsBeanCase._2.toList.sortBy(_.visit_step)
// 4. 获取第一个访问页面的数据
val firstPageViewsBeanCase: PageViewsBeanCase = pageViewsBeanCases.head
// 5. 获取最后一个访问页面数据
val lastPageViewsBeanCase: PageViewsBeanCase = pageViewsBeanCases.last
// 6. 封装VisitBeanCase
VisitBeanCase(session, firstPageViewsBeanCase.remote_addr, firstPageViewsBeanCase.time_local, lastPageViewsBeanCase.time_local,
firstPageViewsBeanCase.request, lastPageViewsBeanCase.request, firstPageViewsBeanCase.htp_referer, pageViewsBeanCases.size)
})
// 将数据写入到Hive
visitBeanCaseRDD.toDF().write.mode("overwrite").parquet("hdfs://node01:8020/user/hive/warehouse/itcast_ods.db/ods_click_stream_visit/dt=20191212/")
}
}