一学就会 | PyTorch入门看这篇就够了
如果觉得本篇文章对您的学习起到帮助作用,请 点赞 + 关注 + 评论 ,留下您的足迹
本文主要介绍PyTorch的常用模块与功能,使用MNIST手写数字数据集进行分类实验。本例将会采用传统python函数进行搭建神经网络和使用PyTorch封装好的库与函数搭建神经网络两种方式,逐步引导,循序渐进开始PyTorch的学习。
本文相关推荐阅读:
一学就会 | 基于PyTorch的TensorBoard可视化
一学就会 | LeNet在CIFAR10数据集上的应用
文章目录
- 全文框架
- 前言
- 手动构建神经网络
- 处理MNIST数据集
- 设置神经网络权重参数
- 构建交叉熵损失函数、ReLU激活函数、准确率测试函数
- 训练神经网络
- 测试神经网络
- 使用PyTorch封装模块构建神经网络
- 使用TensorDataset、DataLoader加载数据
- 使用nn.Module、nn.Linear、nn.functional搭建神经网络模型
- 定义损失函数和优化器
- 训练神经网络
- 测试神经网络
- 使用CNN对MNIST分类
- 构建卷积神经网络
- 训练卷积神经网络
- 测试神经网络
- 使用GPU加速
- 总结
全文框架

前言
PyTorch提供了大量精心设计的模块和类,例如, torch.nn、torch.optim、Dataset和DataLoader,帮助用户创建和训练神经网络。为了充分利用这些模块和类,并根据自己实际要解决的问题制定它们,我们需要真正了解它们的工作流程。为了更好理解,我们将首先在MNIST数据集上训练基本神经网络,而不使用这些模型的任何功能, 我们最初只会使用最基本的PyTorch张量功能。然后,我们将添加torch.nn、torch.optim、Dataset或DataLoader,精确地显示每一部分的功能,以及如何使代码更简洁或更灵活。
手动构建神经网络
这里所说的手动构建神经网络的意思是不使用torch.nn、torch.optim、Dataset或DataLoader等PyTorch封装好的官方模块,我们还原神经网络的工作过程,可以更好了解神经网络工作机制。我们手动构建神经网络的各个功能,可以和后期使用PyTorch模块功能进行比较学习。
处理MNIST数据集
数据处理是指对收集到的数据进行加工、整理,以便将数据喂给模型进行训练,它是训练模型前必不可少的阶段。数据预处理在深度学习分类任务中的作用十分重要,可以说数据处理的好不好对于模型的训练起到事倍功半的效果。
我们将使用经典的MNIST数据集,该数据集由手绘数字(0到9之间)的黑白图像组成。
我们使用标准python库来处理数据,首先解决文件路径,使用的是python3标准库pathlib,一些常用方法请看博文pathlib的常用方法,相信会对你有所帮助。我们将事先准备好MNIST数据集放到指定的路径,本文路径为"F:\OfficialData\mnist\mnist.pkl.gz",请读者以自己的数据集实际存放位置为准。
数据集下载请查看深度学习数据集下载
我们还用到了pickle模块和gzip模块:
pickle模块 - 此模块实现了一个算法将一个任意的Python对象转换为一系列字节,这个过程也被称为串行化对象,可以传输或存储表示对象的字节流,然后再重新构造来创建有相同性质的对象。
gzip模块 - 此模块为GUN zip文件提供了一个类似文件的接口。
先看代码:
from pathlib import Path
import pickle
import gzip
PATH = Path("F:\OfficialData\mnist\mnist.pkl.gz")
with gzip.open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
实际上这一段代码就是从路径"F:\OfficialData\mnist\mnist.pkl.gz"获取数据集,并把压缩包解压加载,共60000个样本分成两个部分,训练集和验证集,(x_train, y_train)为训练集,数目大小为50000,(x_valid, y_valid)为验证集,数目大小为10000。
我们用代码来验证一下:
print('训练集size:')
print(x_train.shape)
print(y_train.shape)
print('验证集size:')
print(x_valid.shape)
print(y_valid.shape)
Out:
训练集size:
(50000, 784)
(50000,)
验证集size:
(10000, 784)
(10000,)
MNIST中的每张训练图片分辨率为 28x28, 被存储为 784(28x28) 的一行。我们输出看一下数据,首先需要转换回 28x28的图像。
import matplotlib.pyplot as plt
plt.imshow(x_train[1].reshape((28, 28)), cmap="gray")
Out:

PyTorch使用 Tensor数据类型 ,所以我们需要对numpy类型数据进行转换,使用torch.tensor函数进行转换。
torch.tensor是PyTorch内置函数,可以将其他的数据类型转换成Tensor张量。
import torch
x_train = torch.tensor(x_train)
y_train = torch.tensor(y_train)
x_valid = torch.tensor(x_valid)
y_valid = torch.tensor(y_valid)
print(x_train.shape)
Out:
torch.Size([50000, 784])
通过观察输出,可以看到维度信息包含在torch.Size中,数据已经转换成为Tensor数据类型。
设置神经网络权重参数
首先,我们并不使用PyTorch的模型,仅使用PyTorch张量操作来创建模型。PyTorch提供了很多创建张量的操作,我们将用这些方法来初始化权值weights和偏置 bais来创建一个线性模型。在创建需要更新的Tensor张量时,需要支持梯度(requires_grad=True)求导。这样PyTorch将记录在张量上完成的所有操作,以便它可以在反向传播过程中自动计算梯度!我们这里创建三层神经网络,并初始化它的权值与参数。
我们weights权值的初始化使用“Xavier初始值”,现在在一般的深度学习框架中,Xavier初始值已经被作为标准使用。
Xavier论文中,为了使各层的激活值呈现出具有相同广度的分布,推导了合适的权重尺度。推导出的结论是,如果前一层的节点数为n,则初始值使用标准差为 1/np.sqr(n) 的分布。
bias初始化为0即可,而且是一维的,后面应用广播技术参与计算。
import numpy as np
w1 = torch.randn(784, 500) / np.sqrt(784)
w1.requires_grad_()
b1 = torch.zeros(500, requires_grad=True)
w2 = torch.randn(500, 200) / np.sqrt(784)
w2.requires_grad_()
b2 = torch.zeros(200, requires_grad=True)
w3 = torch.randn(200, 10) / np.sqrt(784)
w3.requires_grad_()
b3 = torch.zeros(10, requires_grad=True)
构建交叉熵损失函数、ReLU激活函数、准确率测试函数
1、交叉熵损失函数
PyTorch的nn.CrossEntropyLoss实际上就是把Softmax–Log–NLLLoss合并成一步。
Softmax:
我们知道softmax激活函数的计算方式是对输入的每个元素值x求以自然常数e为底的指数,然后再分别除以他们的和,其计算公式如下:
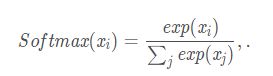
LogSoftmax:
顾名思义,logsoftmax其实就是对softmax求出来的值再求一次log值,其计算公式如下:
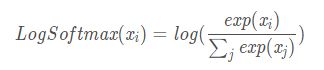
NLLLoss:
假设我们对以下Tensor数据进行NLLLoss运算

NLLLoss的计算方式就是将上面Tensor数据的值与对应标签中的类别拿出来去掉负号,求均值。比如,我们现在的Target标签为[0, 2, 1],分别表示第一张图片的标签为0,第二张图片的标签为2,第三张图片的标签为1。那么NLLLoss的计算就是取出上面输出的第一行-1.5623,第二行-0.9569,第三行-0.3399,取他们的绝对值求和取平均。
(-1.5623 + -0.9569 + -0.3399) / 3 = -0.953033
详情请看博客Pytorch中Softmax、Log_Softmax、NLLLoss以及CrossEntropyLoss的关系与区别详解的讲解。
使用python代码构建CrossEntropyLoss函数:
def log_softmax(x):
return x - x.exp().sum(-1).log().unsqueeze(-1)
def CrossEntropyLoss(input, target):
return -log_softmax(input)[range(target.shape[0]), target].mean()
2、ReLU激活函数
ReLU函数在输入大于0时,直接输出该值;在输入小于等于0时,输出0。
ReLU函数可以表示为下面的公式:

使用python代码构建ReLU激活函数:
这里使用了PyTorch的 clamp 函数。 x.clamp(0) 函数会从输入的数值中选择大于0的值,小于0的值置0。
def relu(x):
return x.clamp(0)
3、准确率测验函数
对于每个预测,如果具有最大值的索引与目标值匹配,则该预测是正确的。
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
训练神经网络
下面我们构建前向传播网络,可以看出,输入批大小为bs的一批数据,输入层为(bs,784)经过三层神经网络的计算,输出(bs,10),层与层之间,是自定义的relu激活函数。
注意:此时我们的神经网络还没有经过训练,参数w1,w2,w3,b1,b2,b3仍为初始化时的数值。
def model(xb):
xb = xb @ w1 + b1
xb = relu(xb)
xb = xb @ w2 + b2
xb = relu(xb)
xb = xb @ w3 + b3
return xb
现在我们开始循环训练模型,每一步我们执行以下操作:
- 选择一批数据
- 使用模型进行预测
- 计算损失函数
- 反向传播更新参数w1,w2,w3,b1,b2,b3
我们在torch.no_grad()中执行更新权重和偏差的操作,因为我们不想在接下来的梯度计算中记录这些动作。
每一步参数更新后,我们都要清零梯度信息,以便开始下一轮循环,否则导数会在原来的基础上累加,而非替代原来的导数值。
bs = 64
lr = 0.5 # 学习率
epochs = 3 # 训练世代数
n, c = x_train.shape
for epoch in range(epochs):
for i in range((n - 1) // bs + 1):
start_i = i * bs
end_i = start_i + bs
xb = x_train[start_i:end_i]
yb = y_train[start_i:end_i]
pred = model(xb)
loss = CrossEntropyLoss(pred, yb)
loss.backward()
with torch.no_grad():
w1 -= w1.grad * lr
b1 -= b1.grad * lr
w1.grad.zero_()
b1.grad.zero_()
w2 -= w2.grad * lr
b2 -= b2.grad * lr
w2.grad.zero_()
b2.grad.zero_()
w3 -= w3.grad * lr
b3 -= b3.grad * lr
w3.grad.zero_()
b3.grad.zero_()
测试神经网络
训练得到拟合程度高的网络,测试样本的准确率未必高。一个好的网络应该具有很好的泛化能力。
可以这样理解,训练是根据你输入的数据通过修正权值来减小误差得到网络模型,测试是用另外的数据去测试网络的性能。
所以我们事先将60000数据集分为训练集和验证集,现在我们使用10000验证集,对训练好的神经网络进行验证,看模型对未知数据的拟合程度。
首先,先看一看模型在训练集上的损失函数和准确率。
pred_train = model(x_train)
loss_train = CrossEntropyLoss(pred_train, y_train)
acc_train = accuracy(pred_train, y_train)
print(loss)
print(acc_train)
Out:
tensor(0.1342, grad_fn=<NegBackward>)
tensor(0.8999)
然后,再看一看模型在验证集上的损失函数和准确率。
pred_valid = model(x_valid)
loss_valid = CrossEntropyLoss(pred_valid, y_valid)
acc_valid = accuracy(pred_valid, y_valid)
print(loss_valid)
print(acc_valid)
Out:
tensor(0.4815, grad_fn=<NegBackward>)
tensor(0.8992)
训练集上准确率为89.99%,验证集上准确率为89.92%,出现了并不严重的过拟合,总的来说,训练的模型在全新的数据上表现很好,有很好的泛化能力。
使用PyTorch封装模块构建神经网络
PyTorch数据加载的核心是可在数据集上迭代的torch.utils.data.DataLoader类。使用DataLoaser处理和加载数据为编程提供了极大便利,相信在接下来的学习中,你也会深有感触。
我们仍然从路径"F:\OfficialData\mnist\mnist.pkl.gz"获取数据集,并把压缩包解压加载,训练集大小为50000,测试集大小为10000.
from pathlib import Path
import pickle
import gzip
PATH = Path("F:\OfficialData\mnist\mnist.pkl.gz")
with gzip.open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
转换为Tensor数据类型
import torch
x_train = torch.tensor(x_train)
y_train = torch.tensor(y_train)
x_valid = torch.tensor(x_valid)
y_valid = torch.tensor(y_valid)
使用TensorDataset、DataLoader加载数据
PyTorch的TensorDataset作用是包装张量的数据集,即传入张量(张量的第一个维度应该相同),每个样本将通过沿着第一维索引加载到神经网络模型。
x_train和y_train都可以合并在一个TensorDataset中,这将更易于迭代和切片。
在未使用TensorDataset前,在训练神经网络的时候,我们需要分别对x_train和y_train进行遍历。而在使用TensorDataset后,我们只需要对数据集遍历一次。
DataLoader负责管理批次,它为一个数据加载器,负责组合数据集,兼顾采样器功能,在给定数据集是可迭代的。可以说DataLoader是datasets和sampler的结合。DataLoader构造函数最重要的参数是数据集,它表示要从中加载数据的数据集对象。
DataLoader支持通过参数batch_size,drop_last和batch_sampler,自动将各个提取的数据样本整理为批次。
几个重要参数:
- batch_size:设置每个批次要装载的数据量
- dataset:需要加载的数据集
- shuffle:当设置shuffle为True时,训练数据在每一个epoch都会被随机打乱
- drop_last:如果数据集大小不能被批量大小整除,则设置为True会删除最后一个不完整的批量
bs = 64 # 一个批次大小为64
from torch.utils.data import TensorDataset, DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
xb,yb = train_ds[0 : bs]
print(xb.shape)
print(yb.shape)
Out:
torch.Size([64, 784])
torch.Size([64])
使用nn.Module、nn.Linear、nn.functional搭建神经网络模型
接下来,我们将使用nn.Module和nn.Linear来实现更清晰、更简洁的训练循环。
1、nn.Module模块
创建一个行为类似于函数但可以包含状态(例如神经网络层和权重)的可调用对象。nn.Module有许多属性和方法(例如.parameters()和.zero_grad()),在接下来的学习中我们将使用它们。
2、nn.Linear模块
我们不需要手动定义和初始化weights和bias,也不需要计算xb @ self.weights + self.bias,而是将PyTorch类nn.Linear用于线性层。Pytorch有许多类型的预定义层,它们可以极大地简化我们的代码,并且常常使代码运行速度更快。我们使用nn.Linear构建线形层,参数已经初始化,而且初始化的更加合理。
3、nn.functional模块
在本示例中,我们使用的是nn.functional模块下的ReLU激活函数,实际上,此功能与我们手写的ReLU功能一致,但是封装好的功能模块已经被优化,运行速度会更快。
import torch.nn as nn
import torch.nn.functional as F
class Mnist_model(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 500)
self.fc2 = nn.Linear(500, 200)
self.fc3 = nn.Linear(200, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
实例化模型:
model = Mnist_model()
定义损失函数和优化器
1、torch.optim模块
PyTorch提供了一个包含各种优化算法的软件包torch.optim。我们可以使用优化器中的step方法更新参数,而不是手动更新每个参数,这可以使我们的代码更加简练,同时模块化编程,有利于维护程序。
2、torch.nn.CrossEntropyLoss()模块
这里我选择的是torch.nn下的交叉熵类,其实这和我们前面手动定义的交叉熵函数功能是一致的。
实例化损失函数和优化器:
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
优化器的model.parameters()为要更新的参数,lr为学习率。
训练神经网络
一切准备工作已经完成,训练3个epoch,损失函数和迭代器都使用的PyTorch封装好的优化模型。
开始训练模型:
epochs = 3
for epoch in range(epochs):
for xb, yb in train_dl:
pred = model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
执行完毕后,让我们快来检测下神经网络训练结果是否达到我们的心中预期。
测试神经网络
这里所做的与手动构建神经网络的方法相同,都是使用神经网络从未见过的验证集,计算损失函数值和识别的准确率。
1、loss_mean()为计算损失函数值的函数。
def loss_mean(model, valid_dl):
valid_loss = 0
for xb,yb in valid_dl:
valid_loss += criterion(model(xb), yb)
return valid_loss / len(valid_dl)
print('验证集loss: %.4f' % loss_mean(model, valid_dl).item())
Out:
验证集loss: 0.1278
2、accuracy_rate()为计算识别准确率的函数。
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
def accuracy_rate(model, valid_dl):
acc = 0
for xb,yb in valid_dl:
acc += accuracy(model(xb), yb)
return (acc/len(valid_dl))
print('准确率acc: %.2f%%' % (accuracy_rate(model, valid_dl).item() * 100))
Out:
准确率acc: 96.03%
使用CNN对MNIST分类
众所周知,处理图片分类,卷积神经网络是最好的选择。本例将使用PyTorch的预定义Conv2d类作为我们的卷积层,我们构建具有2个卷积层,三个线性层的CNN网络。
构建卷积神经网络
每一个卷积层后面要连接ReLU激活函数,再接池化层,经过两次卷积后,神经网络需要将数据转换成线性层可以处理的维度,下面卷积神经网络模型定义的num_flat_features()函数便实现了维度处理。
我们依旧是从加载数据开始,为了不因为前面的运算结果导致后面结果有误,所以我们每次都从头开始执行程序。
同前面给出的程序:
from pathlib import Path
import pickle
import gzip
PATH = Path("F:\OfficialData\mnist\mnist.pkl.gz")
with gzip.open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
import torch
x_train = torch.tensor(x_train)
y_train = torch.tensor(y_train)
x_valid = torch.tensor(x_valid)
y_valid = torch.tensor(y_valid)
bs = 64 # 一个批次大小为64
from torch.utils.data import TensorDataset, DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
def loss_mean(model, valid_dl):
valid_loss = 0
for xb,yb in valid_dl:
valid_loss += criterion(model(xb), yb)
return valid_loss / len(valid_dl)
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
def accuracy_rate(model, valid_dl):
acc = 0
for xb,yb in valid_dl:
acc += accuracy(model(xb), yb)
return (acc/len(valid_dl))
卷积神经网络流程如下:
input --> conv2d --> relu --> maxpool2d --> conv2d --> relu --> maxpool2d --> view --> linear --> relu --> linear --> relu --> linear --> CrossEntropyLoss --> loss
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 4)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = x.view(-1, 1, 28, 28)
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
训练卷积神经网络
实例化卷积神经网络,损失函数仍然使用CrossEntropyLoss,优化器仍使用SGD。
cnn_model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(cnn_model.parameters(), lr=0.05)
准备就绪,开始训练,仍然训练3个epoch。
epochs = 3
for epoch in range(epochs):
for xb, yb in train_dl:
pred = cnn_model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
测试神经网络
执行完毕后,现在检测卷积神经网络的损失函数值和准确率。测试时不需要梯度信息,使用with torch.no_grad()可以节省内存。
with torch.no_grad():
print('验证集loss: %.4f' % loss_mean(cnn_model, valid_dl).item())
print('准确率acc: %.2f%%' % (accuracy_rate(cnn_model, valid_dl).item() * 100))
Out:
验证集loss: 0.0974
准确率acc: 97.14%
MNIST数据集在卷积神经网络上运行,准确率明显提高了不少。
使用GPU加速
首先,检测下GPU是否允许使用:
print(torch.cuda.is_available())
Out:
True
其次,创建一个GPU设备:
dev = torch.device("cuda:0")
最后,将我们的数据和我们创建的模型(model),使用.to(dev)功能放到GPU上,就实现了利用GPU计算。
附代码如下:
from pathlib import Path
import pickle
import gzip
PATH = Path("F:\OfficialData\mnist\mnist.pkl.gz")
with gzip.open(PATH.as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
import torch
print(torch.cuda.is_available())
dev = torch.device("cuda:0")
# 此处使用to(dev)
x_train = torch.tensor(x_train).to(dev)
y_train = torch.tensor(y_train).to(dev)
x_valid = torch.tensor(x_valid).to(dev)
y_valid = torch.tensor(y_valid).to(dev)
bs = 64 # 一个批次大小为64
from torch.utils.data import TensorDataset, DataLoader
train_ds = TensorDataset(x_train, y_train)
train_dl = DataLoader(train_ds, batch_size=bs, shuffle=True)
valid_ds = TensorDataset(x_valid, y_valid)
valid_dl = DataLoader(valid_ds, batch_size=bs * 2)
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 4)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = x.view(-1, 1, 28, 28)
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:]
num_features = 1
for s in size:
num_features *= s
return num_features
cnn_model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(cnn_model.parameters(), lr=0.05)
# 此处使用to(dev)
cnn_model.to(dev)
epochs = 3
for epoch in range(epochs):
for xb, yb in train_dl:
pred = cnn_model(xb)
loss = criterion(pred, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
def loss_mean(model, valid_dl):
valid_loss = 0
for xb,yb in valid_dl:
valid_loss += criterion(model(xb), yb)
return valid_loss / len(valid_dl)
def accuracy(out, yb):
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
def accuracy_rate(model, valid_dl):
acc = 0
for xb,yb in valid_dl:
acc += accuracy(model(xb), yb)
return (acc/len(valid_dl))
with torch.no_grad():
print('验证集loss: %.4f' % loss_mean(cnn_model, train_dl).item())
print('准确率acc: %.2f%%' % (accuracy_rate(cnn_model, valid_dl).item() * 100))
总结
总结使用PyTorch的步骤如下:
- 加载并标准化数据集
- 定义神经网络且实例化
- 定义损失函数和优化器
- 训练神经网络
- 测试神经网络
如果您觉得这篇文章对你有帮助,记得 点赞 + 关注 + 评论 三连,您只需动一动手指,将会鼓励我创作出更好的文章,快留下你的足迹吧