爬虫爬取最好大学排名

☞☞☞点击查看更多优秀Python博客☜☜☜

爬虫爬取最好大学排名
- **程序设计思路:**
- 代码细节分析
- 得到源代码函数分析
- 得到特定的tr标签函数分析
- ==**文章导航:==**
最近跟着北京理工大学的网课 学习了爬虫的知识,看了老师讲的爬虫爬取最好大学排名。下面让我们来看一下爬虫是如何爬取网页上的信息的。
爬取网页:最好大学网
学习来源:哔哩哔哩-【Python网络爬虫与信息提取】.MOOC. 北京理工大学
首先我们打开网页查看网页源代码,寻找自己所需信息所在区域,截如下:
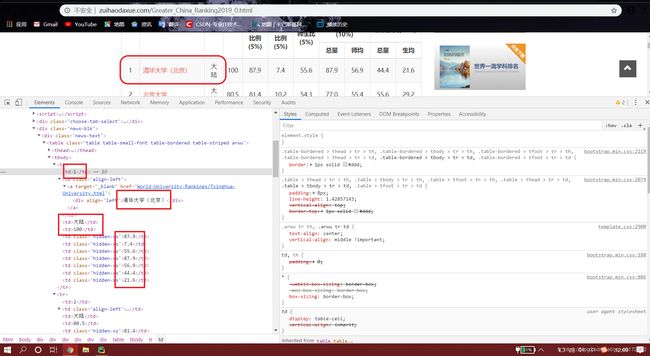
这样我们就成功地找到了所需要的信息,下面的工作就是通过程序找到以上信息并输出出来,下面直接上代码:
程序设计思路:
- 首先我们需要得到网页源代码,可以使用两种方法获得,一种是使用requests库进行得到
- 对源代码进行处理可以使用BeautifulSoup库函数进行修饰
- 得到修饰后的源代码后我们就可以进行提取了
- 最后我们进行格式化输出
- 编写程序将以上函数进行运行顺序的匹配
代码如下:
#-*- coding:utf-8 -*-
#-Author-= JamesBen
#Email: [email protected]
import requests
from bs4 import BeautifulSoup
import bs4
#定义第一个函数得到网页源代码,并且可以进行稳定的运行
def Get_HTML(url):
try :
use = {'User-Agent': 'Mozilla/5.0'} #此行代码骗过服务器我们是使用浏览器进行访问的,防止有些网站对我们进行拦截
r = requests.get(url, timeout = 30,headers = use)
r.raise_for_status() #如果状态不是200引发HTTPError异常
r.encoding = r.apparent_encoding #将文本的编辑方式传给头,防止造成编码错路出现乱码
return r.text
except :
return "产生异常"
#定义一个函数得到特定的tr标签
def U_list(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find("tbody").children:
if isinstance(tr,bs4.element.Tag): #筛选tr标签的类型,如果不是Tag定义的类型将过滤掉
tds = tr("td")
ulist.append([tds[0].string,tds[1].string,tds[3].string])
pass
#格式化输出函数
def print_Univlist(ulist,num):
tplt="{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
print("Suc"+str(num))
def main():
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html = Get_HTML(url)
U_list( uinfo,html)
print_Univlist( uinfo,20)
if __name__ == "__main__":
main()
代码如上,运行结果如下:
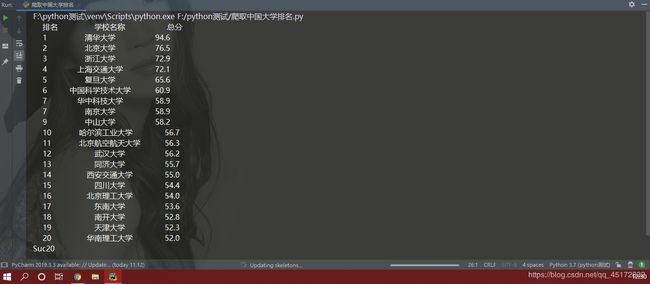
以上就是全部的代码内容,希望对你的学习有帮助。
代码细节分析
得到源代码函数分析
def Get_HTML(url):
try :
use = {'User-Agent': 'Mozilla/5.0'} #此行代码骗过服务器我们是使用浏览器进行访问的,防止有些网站对我们进行拦截
r = requests.get(url, timeout = 30,headers = use)
r.raise_for_status() #如果状态不是200引发HTTPError异常
r.encoding = r.apparent_encoding #将文本的编辑方式传给头,防止造成编码错路出现乱码
return r.text
except :
return "产生异常"
首先函数使用了try. …except…进行确保程序的稳定运行,在函数中首先在头文件中加入User-Agent的信息用于骗过服务器,让服务器误认为是浏览器操作。
第二句是GET到网页源代码并将刚才的header加入到程序中
r.raise_for_status() 确保程序的正常运行,若返回值不是200,则程序会运行except并返回"产生异常"
得到特定的tr标签函数分析
def U_list(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find("tbody").children:
if isinstance(tr,bs4.element.Tag): #筛选tr标签的类型,如果不是Tag定义的类型将过滤掉
tds = tr("td")
ulist.append([tds[0].string,tds[1].string,tds[3].string])
pass
首先我们将得到的源码传给soup,使用BeautifulSoup库函数,具体使用在上文中有讲解。
下面一个for循环是为了在tbody中找出所有的儿子节点并给tr
在if中筛选出符合要求的标签
最后进行格式化输出
以上即为两个重要函数的讲解,希望对你的学习有所帮助!
**文章导航:**
零基础学Python教程
