HDFS面试基础知识点
HDFS面试基础知识点
- HDFS 基本介绍
- HDFS角色作用简介
- HDFS分块存储
- 抽象成数据块的好处
- 块缓存
- HDFS副本机制
- 名字空间(NameSpace)
- Namenode 功能
- Datanode功能
- 机架感知
- HDFS文件读写流程
- 文件写入过程
- 文件读取过程
- 数据完整性
- 掉线时限参数设置
- DataNode的目录结构
- 一次写入,多次读出
- 常用命令实操
- HDFS的特性
- HDFS缺点
- Fsimage,Edits详解
- secondarynameNode如何辅助管理FSImage与Edits文件
- namenode元数据信息多目录配置
HDFS 基本介绍
HDFS 是 Hadoop Distribute File System 的简称,意为:Hadoop 分布式文件系统。是 Hadoop 核心组件之一,作为最底层的分布式存储服务而存在。
分布式文件系统解决的问题就是大数据存储。它们是横跨在多台计算机上的存储系统。分布式文件系统在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力。
HDFS使用Master和Slave结构对集群进行管理。一般一个 HDFS 集群只有一个 Namenode 和一定数目的Datanode 组成。Namenode 是 HDFS 集群主节点,Datanode 是 HDFS 集群从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。
HDFS角色作用简介
HDFS集群包括,NameNode和DataNode以及Secondary Namenode。
- NameNode(Master)管理者 - 负责管理整个文件系统的元数据,以及每一个路径(文件)所对应的数据块信息。
- DataNode (Slave) 工作者 - 负责管理用户的文件数据块,每一个数据块都可以在多个datanode上存储多个副本。
- Secondary NameNode 辅助管理 - 用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。最主要作用是辅助namenode管理元数据信息
HDFS分块存储
hdfs将所有的文件全部抽象成为block块来进行存储,不管文件大小,全部一视同仁都是以block块的统一大小和形式进行存储,方便我们的分布式文件系统对文件的管理。
所有的文件都是以block块的方式存放在HDFS文件系统当中,在Hadoop1当中,文件的block块默认大小是64M,Hadoop2当中,文件的block块大小默认是128M,block块的大小可以通过hdfs-site.xml当中的配置文件进行指定。
dfs.block.size</name>
块大小 以字节为单位</value>//只写数值就可以
</property>
一个文件100M,上传到HDFS占用几个快?一个块128M,剩余的28M怎么办?
事实上,128只是个数字,数据超过128M,便进行切分,如果没有超过128M,就不用切分,有多少算多少,不足128M的也是一个快。这个快的大小就是100M,没有剩余28M这个概念。
抽象成数据块的好处
- 一个文件有可能大于集群中任意一个磁盘
20T/128 = xxx块,这些block块属于一个文件 - 使用块抽象而不是文件,可以简化存储子系统。
- 块非常适合用于数据备份进而提供数据容错能力和可用性
块缓存
通常DataNode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在DataNode的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个DataNode的内存中,当然可以针对每个文件配置DataNode的数量。作业调度器通过在缓存块的DataNode上运行任务,可以利用块缓存的优势提高读操作的性能。
HDFS副本机制
HDFS视硬件错误为常态,硬件服务器随时有可能发生故障。
为了容错,文件的所有 block 都会有副本。每个文件的 block 大小和副本系数都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后改变。
数据副本默认保存三个副本,我们可以更改副本数以提高数据的安全性
在hdfs-site.xml当中修改以下配置属性,即可更改文件的副本数
dfs.replication</name>
3</value>
</property>
Hadoop2.7.2副本节点选择
第一个副本在client所处的节点上。如果客户端在集群外,随机选一个。
第二个副本和第一个副本位于相同机架,随机节点。
第三个副本位于不同机架,随机节点。
名字空间(NameSpace)
HDFS 支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode 负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode 记录下来。
HDFS 会给客户端提供一个统一的目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
Namenode 功能
我们把目录结构及文件分块位置信息叫做元数据。Namenode 负责维护整个hdfs文件系统的目录树结构,以及每一个文件所对应的 block 块信息(block 的id,及所在的datanode 服务器)。
Namenode节点负责确定指定的文件块到具体的Datanode结点的映射关系。在客户端与数据节点之间共享数据。
管理Datanode结点的状态报告,包括Datanode结点的健康状态报告和其所在结点上数据块状态报告,以便能够及时处理失效的数据结点。
Datanode功能
文件的各个 block 的具体存储管理由 datanode 节点承担。每一个 block 都可以在多个datanode 上。Datanode 需要定时向 Namenode 汇报自己持有的 block信息。 存储多个副本(副本数量也可以通过参数设置 dfs.replication,默认是 3)。
向Namenode结点报告状态。每个Datanode结点会周期性地向Namenode发送心跳信号和文件块状态报告。
心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
DataNode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息。
执行数据的流水线复制。当文件系统客户端从Namenode服务器进程获取到要进行复制的数据块列表后,完成文件块及其块副本的流水线复制。
一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
机架感知
机架感知需要人为进行配置,编写Python脚本“RackAware.py”。内容为服务器IP与交换机的对应关系。(开源hadoop,使用RackAware.sh)
#!/usr/bin/python
#-*-coding:UTF-8 -*-
import sys
rack = {
"12.12.3.1":"SW6300-1",
"12.12.3.2":"SW6300-1",
"12.12.3.3":"SW6300-1",
"12.12.3.25":"SW6300-2",
"12.12.3.26":"SW6300-2",
"12.12.3.27":"SW6300-2",
"12.12.3.49":"SW6300-3",
"12.12.3.50":"SW6300-3",
"12.12.3.51":"SW6300-3",
"12.12.3.73":"SW6300-4",
"12.12.3.74":"SW6300-4",
"12.12.3.75":"SW6300-4",
}
if __name__=="__main__":
print "/" + rack.get(sys.argv[1],"SW6300-1-2")
编辑core-site.xml配置文件,将脚本配置为topology.script.file.name的值
topology.script.file.name</name>
/home/bigdata/apps/hadoop/etc/hadoop/RackAware.py </value>
</property>
HDFS文件读写流程
文件写入过程
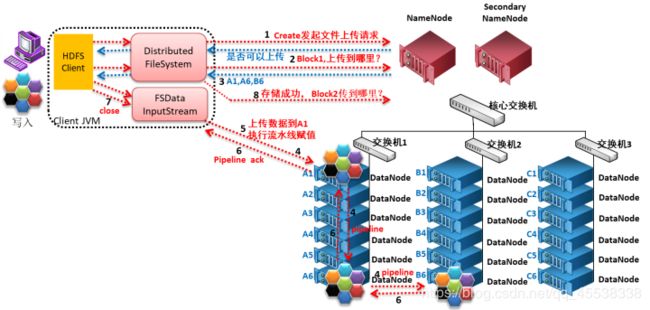
详细步骤解析:
- client发起文件上传请求,通过RPC与NameNode建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
- client请求第一个block该传输到哪些DataNode服务器上;
- NameNode根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的DataNode的地址如:A,B,C;
- client请求3台DataNode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,后逐级返回client;
- client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(默认64K),A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答。
- 数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点A将pipelineack发送给client;
7.关闭写入流。 - 当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。
文件读取过程

详细步骤解析
- 客户端通过调用FileSystem对象的open()来读取希望打开的文件。
- Client向NameNode发起RPC请求,来确定请求文件block所在的位置;
- NameNode会视情况返回文件的部分或者全部block列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址; 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
- Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据(短路读取特性);
- 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
- 并行读取,若失败重新读取
- 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
- 返回后续block列表
- 最终关闭读流,并将读取来所有的 block 会合并成一个完整的最终文件。
说明:
- 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
- read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回Client请求包含块的DataNode地址,并不是返回请求块的数据;
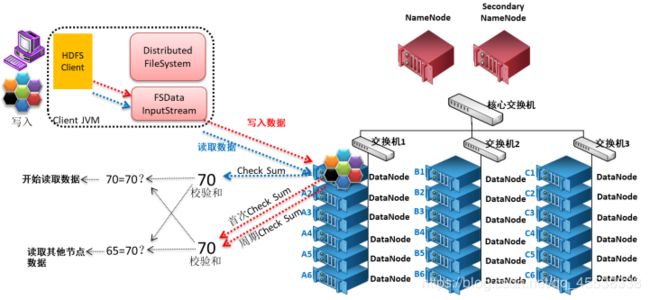
数据完整性
- 当DataNode读取block的时候,它会计算checksum
- 如果计算后的checksum,与block创建时(第一次上传是会计算checksum值)值不一样,说明block已经损坏。
- client读取其他DataNode上的block.
- datanode在其文件创建后周期验证checksum
掉线时限参数设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval。
而默认的dfs.namenode.heartbeat.recheck-interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
dfs.namenode.heartbeat.recheck-interval</name>
300000</value>
</property>
dfs.heartbeat.interval </name>
3</value>
</property>
DataNode的目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。在/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current这个目录下查看版本号
[root@node01 current]# cat VERSION
#Thu Mar 14 07:58:46 CST 2019
storageID=DS-47bcc6d5-c9b7-4c88-9cc8-6154b8a2bf39
clusterID=CID-dac2e9fa-65d2-4963-a7b5-bb4d0280d3f4
cTime=0
datanodeUuid=c44514a0-9ed6-4642-b3a8-5af79f03d7a4
storageType=DATA_NODE
layoutVersion=-56
具体解释
(1)storageID:存储id号
(2)clusterID集群id,全局唯一
(3)cTime属性标记了datanode存储系统的创建时间,对于刚刚格式化的存储系统,这个属性为0;但是在文件系统升级之后,该值会更新到新的时间戳。
(4)datanodeUuid:datanode的唯一识别码
(5)storageType:存储类型
(6)layoutVersion是一个负整数。通常只有HDFS增加新特性时才会更新这个版本号。
一次写入,多次读出
HDFS 是设计成适应一次写入,多次读出的场景,且不支持文件的修改。
正因为如此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做.网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
常用命令实操
(1)-help:输出这个命令参数
bin/hdfs dfs -help rm
(2)-ls: 显示目录信息
hdfs dfs -ls /
(3)-mkdir:在hdfs上创建目录
hdfs dfs -mkdir -p /aaa/bbb/cc/dd
(4)-moveFromLocal从本地剪切粘贴到hdfs
hdfs dfs -moveFromLocal /home/Hadoop/a.txt /aaa/bbb/cc/dd
(5)-moveToLocal:从hdfs剪切粘贴到本地
hdfs dfs -moveToLocal /aaa/bbb/cc/dd /home/Hadoop/a.txt
(6)–appendToFile :追加一个文件到已经存在的文件末尾
hdfs dfs -appendToFile ./hello.txt /hello.txt
(7)-cat :显示文件内容
hdfs dfs -cat /hadoop-daemon.sh
(8)-tail:显示一个文件的末尾
hdfs dfs -tail /weblog/access_log.1
(9)-text:以字符形式打印一个文件的内容
hdfs dfs -text /weblog/access_log.1
(10)-chgrp 、-chmod、-chown:linux文件系统中的用法一样,修改文件所属权限
hdfs dfs -chmod 666 /hello.txt
hdfs dfs -chown someuser:somegrp /hello.txt
(11)-copyFromLocal:从本地文件系统中拷贝文件到hdfs路径去
hdfs dfs -copyFromLocal ./jdk.tar.gz /aaa/
(12)-copyToLocal:从hdfs拷贝到本地
hdfs dfs -copyToLocal /aaa/jdk.tar.gz
(13)-cp :从hdfs的一个路径拷贝到hdfs的另一个路径
hdfs dfs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(14)-mv:在hdfs目录中移动文件
hdfs dfs -mv /aaa/jdk.tar.gz /
(15)-get:等同于copyToLocal,就是从hdfs下载文件到本地
hdfs dfs -get /aaa/jdk.tar.gz
(16)-getmerge :合并下载多个文件,比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,…
hdfs dfs -getmerge /aaa/log.* ./log.sum
(17)-put:等同于copyFromLocal
hdfs dfs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
(18)-rm:删除文件或文件夹
hdfs dfs -rm -r /aaa/bbb/
(19)-rmdir:删除空目录
hdfs dfs -rmdir /aaa/bbb/ccc
(20)-df :统计文件系统的可用空间信息
hdfs dfs -df -h /
(21)-du统计文件夹的大小信息
hdfs dfs -du -s -h /aaa/*
(22)-count:统计一个指定目录下的文件节点数量
hdfs dfs -count /aaa/
(23)-setrep:设置hdfs中文件的副本数量
hdfs dfs -setrep 3 /aaa/jdk.tar.gz
这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量。因为目前只有3台设备,最多也就3个副本,只有节点数的增加到10台时,副本数才能达到10。
(24) - expunge :清空hdfs垃圾桶
hdfs dfs -expunge
HDFS的特性
- 海量数据存储: HDFS可横向扩展,其存储的文件可以支持PB级别或更高级别的数据存储。
- 高容错性: 数据保存多个副本,副本丢失后自动恢复。可构建在廉价的机器上,实现线性扩展。当集群增加新节点之后,namenode也可以感知,进行负载均衡,将数据分发和备份数据均衡到新的节点上。
- 商用硬件: Hadoop并不需要运行在昂贵且高可靠的硬件上。它是设计运行在商用硬件(廉价商业硬件)的集群上的。
- 大文件存储: HDFS采用数据块的方式存储数据,将数据物理切分成多个小的数据块。所以再大的数据,切分后,大数据变成了很多小数据。用户读取时,重新将多个小数据块拼接起来。
HDFS缺点
- 不能做到低延迟数据访问:由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟访问数据的业务需求不适合HDFS。
- 不适合大量的小文件存储 :由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量。根据经验,每个文件、目录和数据块的存储信息大约占150字节。因此,如果有一百万个小文件,每个小文件都会占一个数据块,那至少需要300MB内存。如果是上亿级别的,就会超出当前硬件的能力。
- 修改文件:。HDFS适合一次写入,多次读取的场景。对于上传到HDFS上的文件,不支持修改文件。Hadoop2.0虽然支持了文件的追加功能,但不建议对HDFS上的文件进行修改。因为效率低下.
- 不支持用户的并行写:同一时间内,只能有一个用户执行写操作。
Fsimage,Edits详解
fsimage保存了最新的元数据检查点,在HDFS启动时加载fsimage的信息,包含了整个HDFS文件系统的所有目录和文件的信息。
对于文件来说包括了数据块描述信息、修改时间、访问时间等。
对于目录来说包括修改时间、访问权限控制信息(目录所属用户,所在组)等。
editlog主要是在NameNode已经启动情况下对HDFS进行的各种更新操作进行记录,HDFS客户端执行所有的写操作都会被记录到editlog中。
Fsimage,editlog主要用于在集群启动时将集群的状态恢复到关闭前的状态。
为了达到这个目的,集群启动时将Fsimage、editlog加载到内存中,进行合并,合并后恢复完成。
secondarynameNode如何辅助管理FSImage与Edits文件
由于editlog记录了集群运行期间所有对HDFS的相关操作,所以这个文件会很大。
集群关闭后再次启动时会将Fsimage,editlog加载到内存中,进行合并,恢复到集群的。
由于editlog文件很大所有,集群再次启动时会花费较长时间。
为了加快集群的启动时间,所以使用secondarynameNode辅助NameNode合并Fsimage,editlog。
namenode元数据信息多目录配置
为了保证元数据的安全性,我们一般都是先确定好我们的磁盘挂载目录,将元数据的磁盘做RAID1
namenode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性。
具体配置如下:
hdfs-site.xml
dfs.namenode.name.dir</name>
file:///export/servers/Hadoop-2.6.0-cdh5.14.0/HadoopDatas/namenodeDatas</value>
</property>
难受,没时间写了,后续再完善,,,