ELECTRA:Efficiently Learning an Encoder that Classifies Token Replacements Accurately
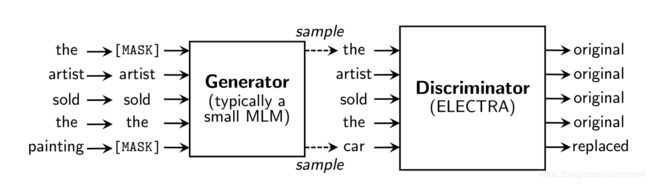
看上去是一个GAN的结构,在生成器的训练中,由于GAN模型在文本上的应用困难,因此,使用的是极大似然的方法。预训练结束后,在下游的应用上,去掉了生成器,仅使用判别器进行微调。
生成器部分:softmax函数

生成器的输入:
生成器的输出:probs Tensor("generator_predictions/Softmax:0", shape=(128, 19, 30522), dtype=float32)
模型代码的部分:
def model_fn_builder(config: configure_pretraining.PretrainingConfig):
"""Build the model for training."""
def model_fn(features, labels, mode, params):
"""Build the model for training."""
# print("config",config)
# print("feature",features)
model = PretrainingModel(config, features,
mode == tf.estimator.ModeKeys.TRAIN)
utils.log("Model is built!") #构建模型成功
if mode == tf.estimator.ModeKeys.TRAIN: #如果是训练的阶段
train_op = optimization.create_optimizer( #优化函数
model.total_loss, config.learning_rate, config.num_train_steps,
weight_decay_rate=config.weight_decay_rate,
use_tpu=config.use_tpu,
warmup_steps=config.num_warmup_steps,
lr_decay_power=config.lr_decay_power
)
output_spec = tf.estimator.tpu.TPUEstimatorSpec(
mode=mode,
loss=model.total_loss,
train_op=train_op,
training_hooks=[training_utils.ETAHook(
{} if config.use_tpu else dict(loss=model.total_loss),
config.num_train_steps, config.iterations_per_loop,
config.use_tpu)]
)
elif mode == tf.estimator.ModeKeys.EVAL: #如果是验证的阶段
output_spec = tf.estimator.tpu.TPUEstimatorSpec(
mode=mode,
loss=model.total_loss,
eval_metrics=model.eval_metrics,
evaluation_hooks=[training_utils.ETAHook(
{} if config.use_tpu else dict(loss=model.total_loss),
config.num_eval_steps, config.iterations_per_loop,
config.use_tpu, is_training=False)])
else:
raise ValueError("Only TRAIN and EVAL modes are supported")
return output_spec
return model_fn #返回函数
features:
features :
Inputs(input_ids=, 输入序列
input_mask=, 掩码后的输入
segment_ids=, 句子分段部分,第一句和第二句
masked_lm_positions=, 掩码的位置
masked_lm_ids=, 掩码对应的字的序列
masked_lm_weights=) #需要掩码的位置的权重
生成器的代码
generator = self._build_transformer(
masked_inputs, is_training,
bert_config=get_generator_config(config, self._bert_config),
embedding_size=(None if config.untied_generator_embeddings
else embedding_size),
untied_embeddings=config.untied_generator_embeddings,
name="generator")
masked_inputs:为输入部分等同于features
Inputs(input_ids=,
input_mask=,
segment_ids=, masked_lm_positions=,
masked_lm_ids=,
masked_lm_weights=)
生成器的输入:
generator = self._build_transformer(
masked_inputs, is_training, embedding_size=embedding_size)输入为:masked_inputs
标签为:
oh_labels = tf.one_hot(
inputs.masked_lm_ids, depth=self._bert_config.vocab_size,
dtype=tf.float32)生成器的softmax层输出概率:
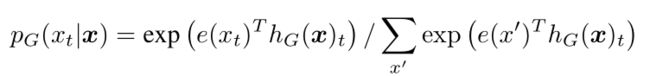
e(xt)为t位置上的向量表示,给定x生成xt的概率

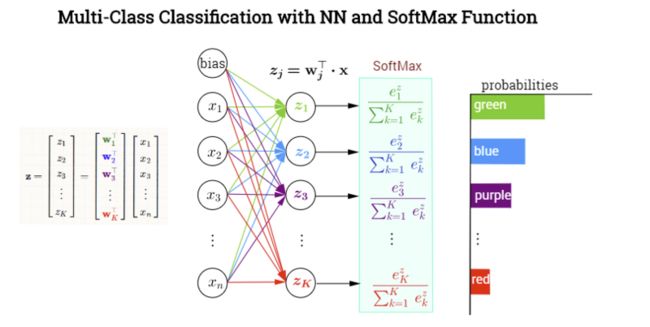

softmax:probs = tf.nn.softmax(logits)log-softmax: log_probs = tf.nn.log_softmax(logits)
交叉熵:
label_log_probs = -tf.reduce_sum(log_probs * oh_labels, axis=-1)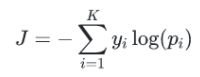
Loss函数:
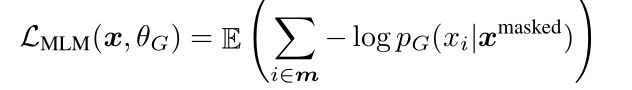
与GAN的不同点
注意:生成器生成的数据正好是对的,这时依然认为是真实的而不是生成的数据。
更重要的是,生成器是用最大似然法训练的,而不是训练来愚弄鉴别器。不能像GAN一样,用带有噪声的向量输入
logits = tf.matmul(hidden, model.get_embedding_table(),
transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
#print("===",inputs.masked_lm_ids) #Tensor("mul_4:0", shape=(128, 19), dtype=int32)
oh_labels = tf.one_hot(
inputs.masked_lm_ids, depth=self._bert_config.vocab_size,
dtype=tf.float32)
#one_hot标签
#print(inputs) #Inputs(input_ids=,
#print("======",oh_labels) #Tensor("generator_predictions/one_hot:0", shape=(128, 19, 30522), dtype=float32)
probs = tf.nn.softmax(logits)
#print("probs",probs)
#probs Tensor("generator_predictions/Softmax:0", shape=(128, 19, 30522), dtype=float32)
log_probs = tf.nn.log_softmax(logits)
label_log_probs = -tf.reduce_sum(log_probs * oh_labels, axis=-1)
numerator = tf.reduce_sum(inputs.masked_lm_weights * label_log_probs)
denominator = tf.reduce_sum(masked_lm_weights) + 1e-6
loss = numerator / denominator #分子/分母
preds = tf.argmax(log_probs, axis=-1, output_type=tf.int32)
数据生成的流程
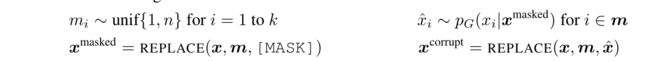
随机mask输入生成器,训练模型。生成器生成数据x^替换mask。
判别器:
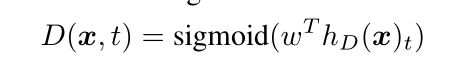
判别器是二分类
判别器的损失函数
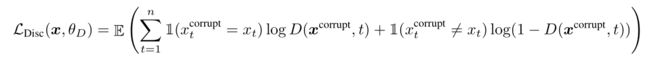
代买实现
losses = tf.nn.sigmoid_cross_entropy_with_logits(
logits=logits, labels=labelsf) * weights def _get_discriminator_output(self, inputs, discriminator, labels):
"""Discriminator binary classifier.判别器二分类"""
with tf.variable_scope("discriminator_predictions"):
hidden = tf.layers.dense(
discriminator.get_sequence_output(), #判别器的数据输出
units=self._bert_config.hidden_size,
activation=modeling.get_activation(self._bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
self._bert_config.initializer_range))
logits = tf.squeeze(tf.layers.dense(hidden, units=1), -1)
weights = tf.cast(inputs.input_mask, tf.float32)
labelsf = tf.cast(labels, tf.float32)
losses = tf.nn.sigmoid_cross_entropy_with_logits(
logits=logits, labels=labelsf) * weights
per_example_loss = (tf.reduce_sum(losses, axis=-1) /
(1e-6 + tf.reduce_sum(weights, axis=-1)))
loss = tf.reduce_sum(losses) / (1e-6 + tf.reduce_sum(weights))
probs = tf.nn.sigmoid(logits)
preds = tf.cast(tf.round((tf.sign(logits) + 1) / 2), tf.int32)
DiscOutput = collections.namedtuple(
"DiscOutput", ["loss", "per_example_loss", "probs", "preds",
"labels"])
return DiscOutput(
loss=loss, per_example_loss=per_example_loss, probs=probs,
preds=preds, labels=labels,
)
labels :Tensor("mul_18:0", shape=(128, 128), dtype=int32),此处的标签是整个原始文本与生成的文本做对比,判断每个词是生成的还是真实的
同生成器的标签是不一样的生成器的标签为mask掉的19个词,但每个词都有30522种选择,也就是字典的大小-vocab_size
Tensor("generator_predictions/one_hot:0", shape=(128, 19, 30522), dtype=float32)#使用生成器生成的数据替换掉mask位置上的数据,作为判别器的输入
updated_input_ids, masked = pretrain_helpers.scatter_update(
inputs.input_ids, sampled_tokids, inputs.masked_lm_positions)论文中的公式解析:
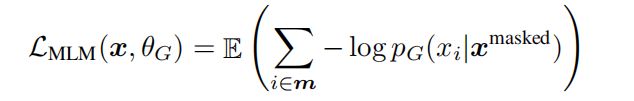
上面是求期望
期望的公式是:
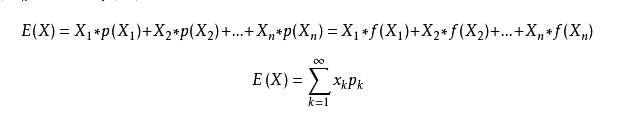
可以得出,其中损失函数等价与交叉熵



代码的实现
probs = tf.nn.softmax(logits)
log_probs = tf.nn.log_softmax(logits)
#print(log_probs) #Tensor("generator_predictions/LogSoftmax:0", shape=(128, 19, 30522), dtype=float32)
label_log_probs = -tf.reduce_sum(log_probs * oh_labels, axis=-1) #axis:指定的维,如果不指定,则计算所有元素的总和;交叉熵
#print(label_log_probs) #Tensor("generator_predictions/Neg:0", shape=(128, 19), dtype=float32)
numerator = tf.reduce_sum(inputs.masked_lm_weights * label_log_probs)
denominator = tf.reduce_sum(masked_lm_weights) + 1e-6
#print(masked_lm_weights) #Tensor("Cast_3:0", shape=(128, 19), dtype=float32)
loss = numerator / denominator
preds = tf.argmax(log_probs, axis=-1, output_type=tf.int32)
典型的交叉熵的实现啊