MFS分布式文件系统实战(三)——MFS高可用(利用pacemaker+corosync+iscsi)、部署Fence解决mfsmaster高可用的解决脑裂
文章目录
- 一、什么是MFS高可用
- 1.1 什么是Pacemaker?
- 1.2 什么是corosync?
- 二、MFS高可用搭建
- 2.1 配置server4作为mfsmaster-backup端
- 2.2 安装高可用套件pacemaker+corosync
- 2.3 安装iscsi实现数据共享
- 2.4 添加MFS相关资源
- 2.5 配置通过虚拟ip访问web监控页面
- 三、部署Fence解决mfsmaster高可用的解决脑裂
一、什么是MFS高可用
mfsmaster是MFS分布式文件系统的调度器,是最核心的地方。 如果mfsmaster挂了,那么整个MFS架构就会挂掉,对此我们要对mfsmaster进行高可用冗余操作。
构建思路:
利用pacemaker构建高可用平台,利用iscis做共享存储,mfschunkserver做存储设备。
有人可能要问为什么不用keepalived,我想说的是就是keepalived是可以完全做的,但是keepalived不具备对服务的健康检查;整个corosync验证都是脚本编写的,再通过vrrp_script模块进行调用,利用pacemaker比较方便。
用途:
解决mfs master的单点问题,同样可以作为其他需要高可用环境的标准配置方法
1.1 什么是Pacemaker?
Pacemaker是一个集群管理器。
它利用首选集群基础设施(OpenAIS或heartbeat)提供的消息和成员能力,由辅助节点和系统进行故障检测和回收,实现性群集服务(亦称资源)的高可用性。
它可以做几乎任何规模的集群,并带有一个强大的依赖模式,让管理员能够准确地表达群集资源之间的关系(包括顺序和位置)。
几乎任何可以编写的脚本,都可以作为管理起搏器集群的一部分。
尤为重要的是Pacemaker不是一个heartbeat的分支,似乎很多人存在这样的误解。
Pacemaker是CRM项目(亦名V2资源管理器)的延续,该项目最初是为heartbeat而开发,但目前已经成为独立项目。
1.2 什么是corosync?
Corosync是集群管理套件的一部分,它在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。
corosync+pacemaker:在配置corosync时最好具有三个以上的节点,并且节点个数为奇数个,如果使用偶数个节点的话也没关系,只是要关闭不具有法定票数的决策策略功能
二、MFS高可用搭建
实验环境
| 主机 | 服务 |
|---|---|
| server1 | mfsmaster,pacemaker,iscsi客户端 |
| server2 | mfschunkserever,iscsi服务端 |
| server3 | mfschunkserever |
| server4 | mfsmaster-backup,pacemaker,iscsi客户端 |
| server5 | client |
实验准备
在基础MFS分布式文件系统上搭建高可用,停掉之前mfs分布式文件系统启动的服务,并卸载客户端挂载的目录,为后续的pcs集群做准备
[root@server1 ~]# systemctl stop moosefs-master
##moosefs-cgiserv服务可以不用关闭,因为moosefs-cgisev服务只是用来提供web界面的
[root@server2 ~]# systemctl stop moosefs-chunkserver
[root@server3 ~]# systemctl stop moosefs-chunkserver
[root@server5 ~]# umount /mnt/mfsmeta
[root@server5 ~]# umount /mnt/mfs
2.1 配置server4作为mfsmaster-backup端
1、配置MooseFS的yum源
(1)添加键值
curl "https://ppa.moosefs.com/RPM-GPG-KEY-MooseFS" > /etc/pki/rpm-gpg/RPM-GPG-KEY-MooseFS
(2)添加YUM源
curl "http://ppa.moosefs.com/MooseFS-3-el7.repo" > /etc/yum.repos.d/MooseFS.repo
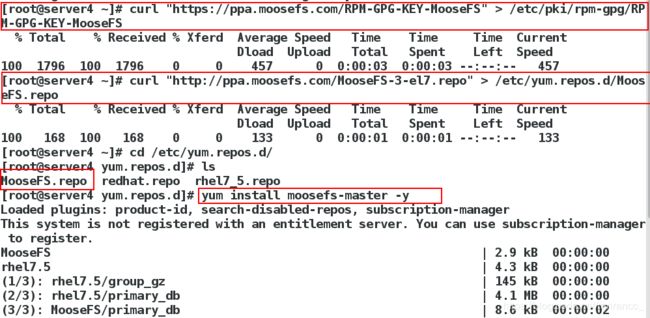
2、安装moosefs-master
yum install moosefs-master moosefs-cgiserv -y
3、编辑本地解析文件
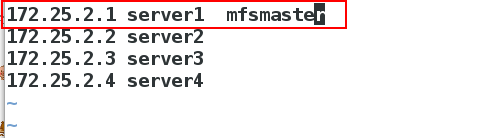
[root@server4 ~]# vim /etc/hosts
172.25.2.1 server1 mfsmaster
4、修改moosefs-master服务的启动脚本/usr/lib/systemd/system/moosefs-master.service
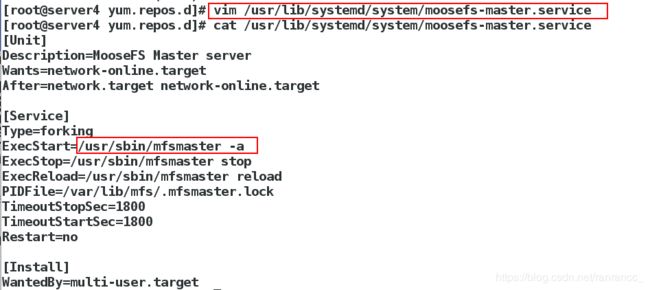
[root@server4 ~]vim /usr/lib/systemd/system/moosefs-master.service
8 ExecStart=/usr/sbin/mfsmaster -a
[root@server4 ~]# systemctl daemon-reload
[root@server4 ~]# systemctl start moosefs-master #检查脚本是否有错误,即查看moosefs-master服务是否能够正常启动
[root@server4 ~]# systemctl stop moosefs-master

2.2 安装高可用套件pacemaker+corosync
使用corosync作为集群消息事务层(Massage Layer),pacemaker作为集群资源管理器(Cluster Resource Management),pcs作为CRM的管理接口工具。
1、server1和server4 配置高可用yum源
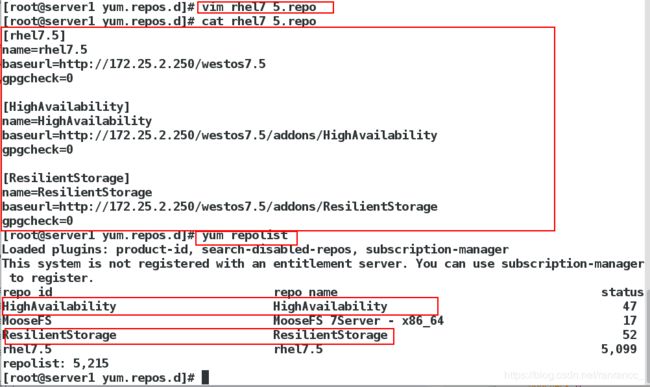
[root@server1 yum.repos.d]# vim rhel7_5.repo
[rhel7.5]
name=rhel7.5
baseurl=http://172.25.2.250/westos7.5
gpgcheck=0
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.2.250/westos7.5/addons/HighAvailability
gpgcheck=0
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.2.250/westos7.5/addons/ResilientStorage
gpgcheck=0
 2、在server1上和server4上,安装pacemaker+corosync
2、在server1上和server4上,安装pacemaker+corosync
[root@server1 yum.repos.d]# yum install pacemaker corosync -y
[root@server4 ~]# yum install pacemaker corosync -y
3、在server1和server4 节点之间要做ssh免密
[root@server1 yum.repos.d]# ssh-keygen
[root@server1 yum.repos.d]# ssh-copy-id server4
[root@server1 yum.repos.d]# ssh-copy-id server1
 验证免密是否成功
验证免密是否成功

4、在server1和server4上,安装集群化管理工具pcs并且开启相应服务
yum install -y pcs
systemctl start pcsd
systemctl enable pcsd
##开启该服务之后会在/etc/passwd目录下生成hacluster用户,及高可用管理用户
passwd hacluster
##配置高可用集群管理用户的密码

5、在server1上,创建mfs集群mycluster并且启动
[root@server1 yum.repos.d]# pcs cluster auth server1 server4
Username: hacluster (此处需要输入的用户名必须为pcs自动创建的hacluster,其他用户不能添加成功)
Password:
server4: Authorized
server1: Authorized
[root@server1 yum.repos.d]# pcs cluster setup --name mycluster server1 server4
#创建集群mycluster
[root@server1 yum.repos.d]# pcs cluster start --all
#启动集群

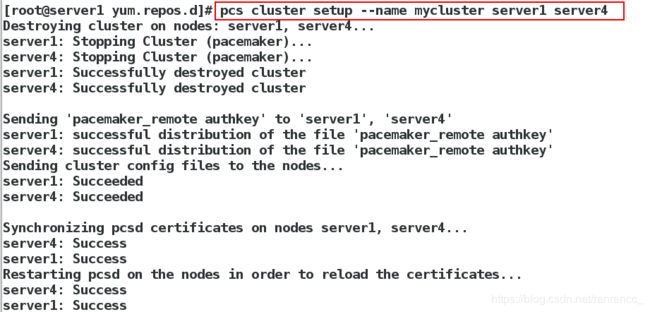

6、查看集群状态
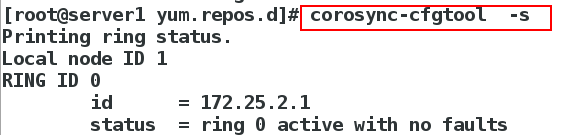
[root@server1 yum.repos.d]# corosync-cfgtool -s
##查看节点状态
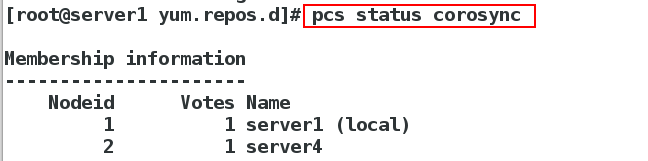
[root@server1 yum.repos.d]# pcs status corosync
##查看corosync状态
7、检查集群服务是否正常
[root@server1 yum.repos.d]# crm_verify -L -V
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
##这里的错误是由于没有设置fence导致的,后面我们会设置fence
[root@server1 yum.repos.d]# pcs property set stonith-enabled=false
##当前没有Fence,建议禁用STONITH,再次检查就不会报错
[root@server1 yum.repos.d]# crm_verify -L -V
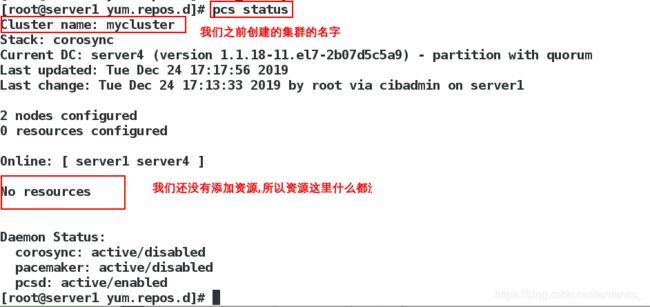
 8、此时,查看我们创建的集群,还没有添加过资源,所以资源这里什么都没有
8、此时,查看我们创建的集群,还没有添加过资源,所以资源这里什么都没有
[root@server1 ~]# pcs status
9、创建集群资源,添加VIP
[root@server1 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.2.100 cidr_netmask=32 op monitor interval=30s
[root@server1 ~]# pcs resource show #同命令"pcs resource"
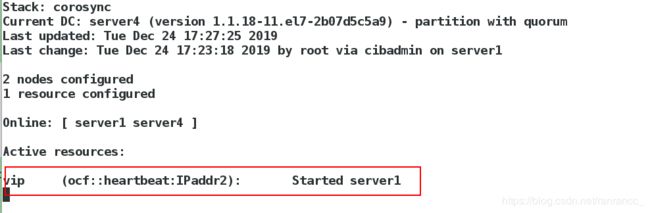
 在server1上,可以看到
在server1上,可以看到vip:172.25.2.100
 当然也可以在server4端打开监控,来实时监控集群中资源的状态
当然也可以在server4端打开监控,来实时监控集群中资源的状态
[root@server4 ~]# crm_mon #使用Ctrl+c退出监控
10、为了验证vip这个资源的高可用,我们停掉pcs集群中的server1端,看vip是否在server4上运行
[root@server1 ~]# pcs cluster stop server1
[root@server1 ~]# ip addr show ##此时已经没有vip

此时vip在server4上面
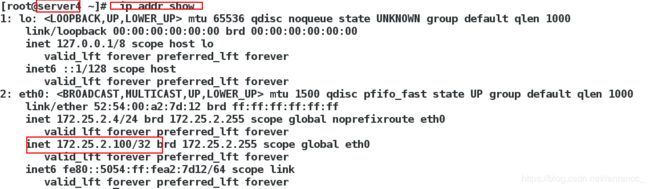
为查看是否回切,再次打开pcs集群中的server1端,vip仍在server4上运行,并未回切到server1

此时,已经实现了高可用。
2.3 安装iscsi实现数据共享
1、添加20G的虚拟硬盘
2、.在server2,即chunkserver节点上进行iscsi配置:
[root@server2 ~]# yum install -y targetcli
[root@server2 ~]# targetcli
targetcli shell version 2.1.fb46
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> ls ##查看targetcli的相关信息
/> backstores/block create my_disk1 /dev/sdb ##添加磁盘
Created block storage object my_disk1 using /dev/sdb.
/> iscsi/ create iqn.2019-12.com.example:server2 ##创建磁盘目录,进入目录下的相应目录创建已添加磁盘
Created target iqn.2019-12.com.example:server2.
Created TPG 1.
Global pref auto_add_default_portal=true
Created default portal listening on all IPs (0.0.0.0), port 3260.
/> iscsi/iqn.2019-12.com.example:server2/tpg1/luns create /backstores/block/my_disk1
Created LUN 0.
##创建client磁盘共享目录
/> iscsi/iqn.2019-12.com.example:server2/tpg1/acls create iqn.2019-12.com.example:client
Created Node ACL for iqn.2019-12.com.example:client
Created mapped LUN 0.
/> exit

3、在server1上,下载iscsi并且做相应配置
[root@server1 ~]# yum install -y iscsi-*
##修改客户端的iscsi加密服务文件的问题,及添加服务端的钥匙
[root@server1 ~]# vim /etc/iscsi/initiatorname.iscsi
[root@server1 ~]# cat /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-12.com.example:client
##登录查看是否共享成功
[root@server1 ~]# iscsiadm -m discovery -t st -p 172.25.2.2
[root@server1 ~]# iscsiadm -m node -l

 在server1上,登录查看:
在server1上,登录查看:fdisk -l

4.在server1 上,创建共享的磁盘分区并格式化
[root@server1 ~]# fdisk /dev/sdb
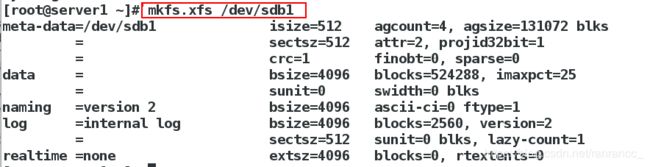
[root@server1 ~]# mkfs.xfs /dev/sdb1

5、server1上,挂载格式化后的分区/dev/sdb1
[root@server1 ~]# mount /dev/sdb1 /mnt
[root@server1 ~]# cd /var/lib/mfs/ 这是mfs的数据目录
[root@server1 mfs]# ls
changelog.2.mfs changelog.4.mfs changelog.6.mfs metadata.mfs metadata.mfs.empty
changelog.3.mfs changelog.5.mfs metadata.crc metadata.mfs.back.1 stats.mfs
[root@server1 mfs]# cp -p * /mnt/ 带权限拷贝/var/lib/mfs的所有数据文件到/dev/sdb1上
[root@server1 mfs]# cd /mnt/
[root@server1 mnt]# ls
changelog.2.mfs changelog.4.mfs changelog.6.mfs metadata.crc metadata.mfs.back.1 stats.mfs
changelog.3.mfs changelog.5.mfs lost+found metadata.mfs metadata.mfs.empty
[root@server1 mnt]# chown mfs.mfs /mnt 当目录属于mfs用户和组时,才能正常使用
[root@server1 mnt]# cd
[root@server1 ~]# umount /mnt
[root@server1 ~]# mount /dev/sdb1 /var/lib/mfs/ # 使用分区,测试是否可以使用共享磁盘
[root@server1 ~]# systemctl start moosefs-master 服务开启成功,就说明数据文件拷贝成功,共享磁盘可以正常使用

6、在server4上操作同server1
root@server4 system]# yum install -y iscsi-*
[root@server4 system]# vim /etc/iscsi/initiatorname.iscsi
文件编辑内容如下:
InitiatorName=iqn.2019-05.com.example:client
[root@server4 system]# iscsiadm -m discovery -t st -p 172.25.16.2
[root@server4 system]# iscsiadm -m node -l
[root@server4 system]# fdisk -l #共享成功

2.4 添加MFS相关资源
##创建资源
[root@server1 mfs]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/var/lib/mfs/ fstype=xfs op monitor interval=30s
##创建mfsd文件系统
[root@server1 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min
[root@server1 ~]# pcs resource show
##此时服务并未集中在一台主机上
vip (ocf::heartbeat:IPaddr2): Started server4
mfsdata (ocf::heartbeat:Filesystem): Started server1
mfsd (systemd:moosefs-master): Started server1
[root@server1 ~]# pcs resource group add mfsgroup vip mfsdata mfsd
##把服务集中在一台主机上,其中添加的顺序是有严格限制的,按照资源添加的顺序,进行添加。
[root@server1 ~]# pcs resource show
##此时服务已集中在一台主机上了。
Resource Group: mfsgroup
vip (ocf::heartbeat:IPaddr2): Started server4
mfsdata (ocf::heartbeat:Filesystem): Started server4
mfsd (systemd:moosefs-master): Started server4
![]()
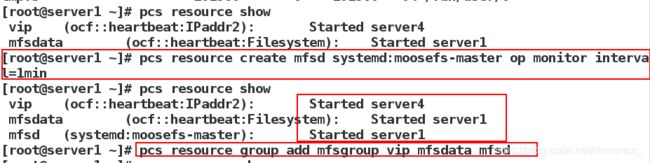

此时,关掉server4上的master服务,发现backup master上的服务迁移到master上也就是server1
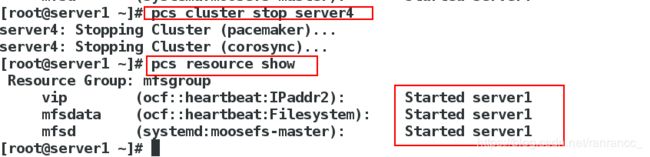
2.5 配置通过虚拟ip访问web监控页面
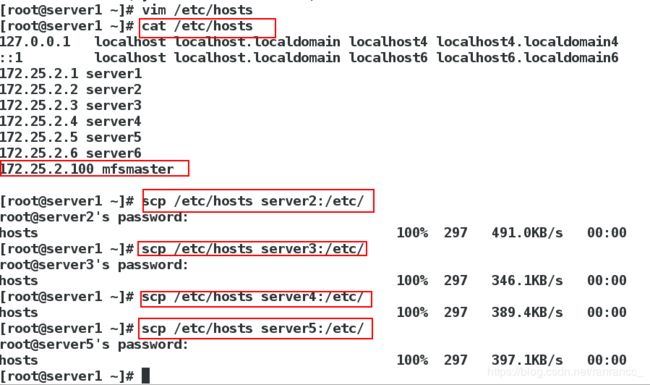
1、修改server1,server2,server3,server4,server5的本地解析文件
[root@server1 ~]# vim /etc/hosts
172.25.2.100 mfsmaster
[root@server1 ~]# scp /etc/hosts server2:/etc/
[root@server1 ~]# scp /etc/hosts server3:/etc/
[root@server1 ~]# scp /etc/hosts server4:/etc/
[root@server1 ~]# scp /etc/hosts server5:/etc/
2、开启server2和server3的moosefs-chunkserver服务
[root@server2 ~]# systemctl start moosefs-chunkserver
[root@server3 ~]# systemctl start moosefs-chunkserver
3、访问浏览器172.25.2.100:9425,看到的内容

4、测试:客户端往mfs分布式文件系统中写入内容,此时服务端(mfsmaster)端挂掉了,我们看看客户端会不会受到影响。
#客户端往mfs分布式文件系统中写内容。
[root@foundation83 mfs]# dd if=/dev/zero of=dir1/bigfile3 bs=1M count=1000
#同时mfsmaster端挂掉mfsmaster服务
[root@server1 ~]# pcs cluster stop server4
#值的注意的是:两端的操作要同时进行,即两端都要卡顿一下


查看状态,切换到了server4:

客户端没有受到一点的影响,这就是实现mfsmatser高可用的好处
三、部署Fence解决mfsmaster高可用的解决脑裂
fence的工作原理:
当意外原因导致主机异常或者宕机时,备机会首先调用FENCE设备,然后通过FENCE设备将异常主机重启或者从网络隔离,当FENCE操作成功执行后,返回信息给备机,备机在接到FENCE成功的信息后,开始接管主机的服务和资源。这样通过FENCE设备,将异常节点占据的资 源进行了释放,保证了资源和服务始终运行在一个节点上,并且有效的阻止了脑裂(高可用节点分裂为两个独立节点,这个时候会开始争抢共享资源)的发生。
1、配置物理机,作为fence服务端:
yum install fence-virtd.x86_64 fence-virtd-libvirt.x86_64 fence-virtd-multicast.x86_64 -y
2、进行初始化设置(其中要将接口设备改为br0,其他默认回车,最后一项输入y确定即可)
fence_virtd -c

3、生成fence_xvm.key
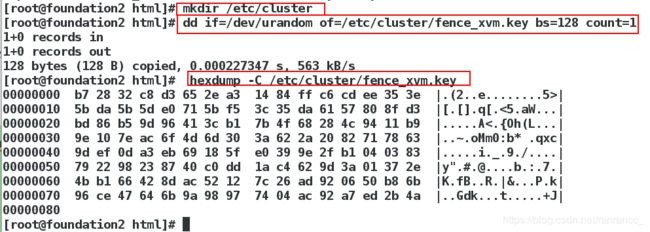
[root@foundation2 html]# mkdir /etc/cluster
[root@foundation2 html]# dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
##dd截取,生成128位的fence_xvm.key,可以file查看这个key类型是数据(data),所以只能利用下面的命令来查看该文件
[root@foundation2 html]# hexdump -C /etc/cluster/fence_xvm.key
###查看key
 4、启动fence_virtd服务,并查看1229端口(fence_virtd服务对应的端口)是否存在
4、启动fence_virtd服务,并查看1229端口(fence_virtd服务对应的端口)是否存在
[root@foundation2 html]# systemctl start fence_virtd.service
[root@foundation2 html]# netstat -antulpe | grep 1229
![]()
5、配置server1和server4,作为fence客户端
yum install fence-virt -y
从fence服务端那里拷贝fence_xvm.key
[root@server1 ~]# mkdir /etc/cluster
[root@server1 ~]# cd /etc/cluster
[root@server1 cluster]# scp @172.25.2.250:/etc/cluster/fence_xvm.key .
[root@server1 cluster]# ll /etc/cluster/

6、添加fence设备,启用STONITH
[root@server1 ~]# pcs stonith create vmfence fence_xvm pcmk_host_map="server1:server1;server4:server4" op monitor interval=1min #添加名为vmfence的fence设备(其中第一个server1表示虚拟机的名字,第二个server1表示主机名。server4同理)。其中vmfence这个名字随意给
[root@server1 ~]# pcs property set stonith-enabled=true
[root@server1 ~]# crm_verify -L -V
[root@server1 ~]# fence_xvm -H server4 # 使server4断电重启
[root@server1 ~]# crm_mon

`[root@server1 cluster]# crm_mon # 查看监控,server4上的服务迁移到master的server1上`
[root@server1 cluster]# echo c > /proc/sysrq-trigger # 模拟master端内核崩溃
查看监控,server4会立刻接管master的所有服务

server1重启成功后,不会抢占资源,不会出现脑裂的状况。查看监控发现,master重启成功之后,并不会抢占资源,服务依旧在backup-master端正常运行,说明fence生效。