数据大清洗_Pandas库进阶(数据合并)
目录
- 一、认识数据处理
- 二、数据集成-concat
- (一)横向堆叠-concat
- (二)纵向堆叠-concat
- 三、垂钓装备的合并案例
- 四、主键合并-megre
- 五、重叠合并-combine_first
一、认识数据处理
1、现实世界的数据是“肮脏的”——数据多了,什么问题都会出现
(1)不完整的:缺少属性值,缺少感兴趣的属性,或仅包含聚集数据。 如:e.g., Occupation=“”;
(2)含噪声的:包含错误或者“孤立点”。 e.g.,Salary=“-10”;
(3)不一致的:在编码或者命名上存在差异。E.g.Age=“42” Birthday=“03/07/1997” 如:等级代码 前面“1,2,3”, 后面“A,B, C”。
2、没有高质量的数据,就没有高质量的挖掘结果
高质量的决策必须依赖高质量的数据。
数据处理的主要任务
1、数据集成
集成多个数据库、数据立方体或文件。(本文内容)
2、数据清理
(1)填充缺失值; (2)识别孤立点,去除噪音; (3)修正不一致数据; (4)解决由于数据集成造成的数据冗余问题。
3、数据规约
得到数据集的压缩表示,它小得多,但可以得到相同或相近的结果,包括维规约和数值
规约。
4、数据变换
规范化:将数据按比例缩放,使之落入一个小的特定区间。
5、数据离散化
离散化:数值属性的原始值用区间标签或概念标签替换,或者标称属性转化为数值属性。
二、数据集成-concat
(一)横向堆叠-concat
横向堆叠,即将两个表在 X 轴向拼接在一起,可以使用 concat 函数完成,concat 函数
的基本语法如下。
pandas.concat(objs,axis=1,join='outer',join_axes=None,ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True)


当 axis=1 的时候,concat 做行对齐,然后将不同列名称的两张或多张表合并。
合并的原理图:

代码实现:
import pandas as pd
# 横向堆叠 --->在列的方向上进行拼接合并
# --->沿着x轴的方向进行拼接合并
# --->水平方向的进行拼接合并
# 加载数据
df1 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=0)
df2 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=1)
print('df1:\n', df1)
print('df2:\n', df2)
# 横向堆叠 ---给数据堆叠新的属性
# axis = 1 --->横向堆叠
# outer --外连接 --求并集
# 在横向,直接堆叠, 在行的方向,求所有行的并集,如果出现没有的值,用NaN补齐
res1 = pd.concat((df1, df2), axis=1, join='outer')
print('res1:\n', res1)
# 在横向,直接堆叠,在行的方向,求所有行的交集
res2 = pd.concat((df1, df2), axis=1, join='inner')
print('res2:\n', res2)
(二)纵向堆叠-concat
当 axis=0 的时候,concat 做列对齐,然后将不同列名称的两张或多张表合并。
合并的原理图:
代码实现:
import pandas as pd
# # 加载数据
# df1 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=0)
# df2 = pd.read_excel('./concat直接拼接数据.xlsx', sheet_name=1)
#
# print('df1:\n', df1)
# print('df2:\n', df2)
# 纵向堆叠---在行的方向上进行合并数据
# ---在垂直的方向进行合并数据
# axis= 0 --->纵向堆叠
# # outer --外连接 --求并集
# 在纵向,直接堆叠,在列的方向上,求所有列的并集,如果遇到没有数据,用NaN来补齐
# res = pd.concat((df1, df2), axis=0, join='outer')
# print(res)
# 在纵向,直接堆叠,在列的方向上,求所有列的交集
# res = pd.concat((df1, df2), axis=0, join='inner')
# print(res)
# 纵向堆叠
# append
# 前提:追加的时候,列名一致
# 加载数据
df1 = pd.read_excel('./append直接拼接数据.xlsx', sheet_name=0)
df2 = pd.read_excel('./append直接拼接数据.xlsx', sheet_name=1)
print('df1:\n', df1)
print('df2:\n', df2)
print('*' * 100)
# 追加 ---返回追加之后的结果
res = df1.append(df2)
print('追加的结果:\n', res)
三、垂钓装备的合并案例
近年来,随着人们的生活水平的提高,人们对于精神生活品质的要求越来越高,于是,
各种娱乐活动出现,其中,钓鱼属于一种户外运动,目标是用渔具把鱼从水里钓上来,而且
钓鱼不限制性别与年龄,大人小孩子都喜欢。钓鱼亲近大自然,陶冶情操。然而在钓鱼的时
候,钓鱼装备又影响着钓鱼的成果,所以,越来越多的钓友对于钓鱼装备的要求越来越高,
对于钓鱼装备的需求也越来越多,那么对于钓鱼装备的销售公司来说,了解客户对于不同品
牌的钓鱼装备的喜爱程度,对于销售公司来说至关重要。
以下为某钓鱼装备公司的销售记录,针对于销售记录,来确定客户最喜爱的品牌或者最
火品牌。

以下为每类钓鱼装备销售记录细表(表结构类似)

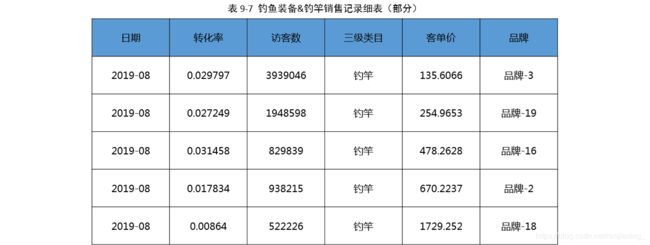
到底如何理解最火品牌?
其实可以转化为确定哪个品牌的销售额最高,那么该品牌就是
最火的品牌。会发现在各个类别的销售记录细表中,并不存在着销售额特征字段,但是可以
通过销售额=访问数转化率客单价”来确定销售额。
相关data数据,随后我会将源码放入码云上,关注作者,稍后领取。
import pandas as pd
import os # 对文件夹处理
import time
# 哪个品牌的 装备最火?
# --->哪个品牌的销售额最大--->该品牌最火
# 销售额 --->访问量 * 转化率 *单价
# 单个问价的 类目下 不同品牌的 销售额数据
# # 加载 垂钓装备&绑钩器.xlsx 文件
# # 查看单个文件 结构
# data = pd.read_excel('./data/垂钓装备&绑钩器.xlsx')
# print('data:\n', data)
#
#
# # 计算销售额
# data.loc[:, '销售额'] = data.loc[:, '转化率'] * data.loc[:, '访客数'] * data.loc[:, '客单价']
# print('data:\n', data)
#
# # 按照品牌 统计 各个品牌的销售额
# res_df = data.groupby(by='品牌')['销售额'].sum().reset_index()
#
# # 增加大的类目
# res_df.loc[:, '类目'] = '垂钓装备&绑钩器.xlsx'.replace('.xlsx', '')
#
# print('res_df:\n', res_df)
start = time.time()
# 所有文件的--->也可以进行运算
# 获取data里面所有的文件名称
file_name_list = os.listdir('./data/')
print('file_name_list:\n', file_name_list)
# 创建一个空的df 进行占位
df_all = pd.DataFrame()
# 循环加载、并处理每一个文件
for file_name in file_name_list:
# 加载每一个文件 ---返回的就是file_data
file_data = pd.read_excel('./data/' + file_name)
# 计算销售额
file_data.loc[:, '销售额'] = file_data.loc[:, '转化率'] * file_data.loc[:, '访客数'] * file_data.loc[:, '客单价']
# print('file_data:\n', file_data)
# 各个品牌的销售额
res_df = file_data.groupby(by='品牌')['销售额'].sum().reset_index()
# 添加类目
res_df.loc[:, '类目'] = file_name.replace('.xlsx', '')
print('新生成的类目:\n', res_df)
# 将 各个类目、各个品牌的销售额 进行合并
# 合并到 df_all
# 因为 列 都是相同
df_all = pd.concat((df_all, res_df), axis=0)
# df_all = df_all.append(res_df)
print('*' * 100)
# 获取到所有类目下的 对应品牌的销售额
print('所有品牌的销售额:\n', df_all)
print('*' * 100)
# 展示的小数 保留 2位小数
# 保留两位小数
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# 按照品牌进行分组,统计销售额的sum ---排序---降序
res = df_all.groupby(by='品牌')['销售额'].sum().reset_index().sort_values(by='销售额', ascending=False).head()
print('所有品牌销售额排行:\n', res)
end = time.time()
print('总共花费时间为:', end - start)
运行效果:



四、主键合并-megre
主键合并,即通过一个或多个键将两个数据集的行连接起来,类似于 SQL 中的 JOIN。
针对同一个主键存在两张包含不同字段的表,将其根据某几个字段一一对应拼接起来,结果
集列数为两个元数据的列数和减去连接键的数量。


想要进行左右两表的主键合并,可以使用 megre 函数,和数据库的 join 一样,merge
函数也有左连接(left)、右连接(right)、内连接(inner)和外连接(outer),但比起数
据库 SQL 语言中的 join 和 merge 函数还有其自身独到之处,例如可以在合并过程中对数据集中的数据进行排序等。
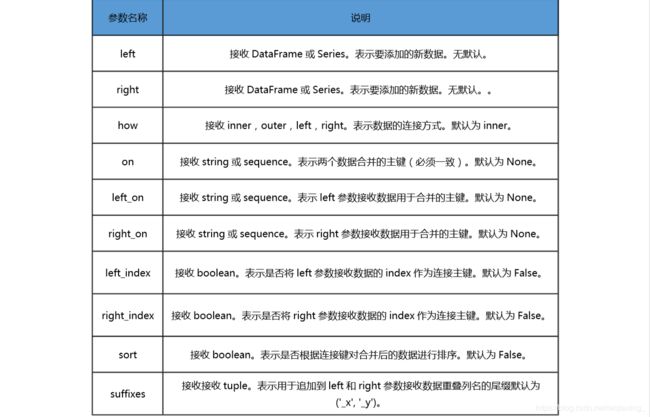
pandas.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True,
indicator=False)
merge 参数说明表
代码实现:
import pandas as pd
# 主键合并:类似于mysql数据库中外键连接
# 根据键值(指定的列)进行的数据合并
# 加载数据
# df1 = pd.read_excel('./merge主键拼接数据.xlsx', index_col=0, sheet_name=0)
# df2 = pd.read_excel('./merge主键拼接数据.xlsx', index_col=0, sheet_name=1)
# print('df1:\n', df1)
# print('df2:\n', df2)
# 进行主键连接
# 存在相同名称,且值大部分相同的列 ---键
# left---左边的df
# right ---右边的df
# how ---指定的是连接方式
# -------inner --内连接 ---求交集 --即拿取键所在列两个df共同拥有的值进行拼接合并
# -------outer --外连接 ---求并集 --即拿取键所在列的所有的值进行拼接合并
# -------left --左连接(左外连接) ---即拿取左df中键所有值,再利用右df来配合左df连接
# -------right --右连接(右外连接)---即拿取右df中键所有值,再利用左df来配合右df连接
# on ---指定键,即指定连接的列
# res = pd.merge(left=df1, right=df2, how='inner', on='key')
# print('res:\n',res)
# res = pd.merge(left=df1, right=df2, how='outer', on='key')
# print('res:\n', res)
# res = pd.merge(left=df1, right=df2, how='left', on='key')
# print('res:\n', res)
# res = pd.merge(left=df1, right=df2, how='right', on='key')
# print('res:\n', res)
# 多个主键的拼接
# 可能存在---如df1 省、 市、 属性1 属性2
# 如df2 省、市 、属性3 、 属性4 ---->可以使用主键拼接,键指定为:省、市
# 假设又存在 左右两个df 键的名称不同、键里面的值大部分相同的情况下
df1 = pd.read_excel('./merge主键拼接数据.xlsx', index_col=0, sheet_name=2)
df2 = pd.read_excel('./merge主键拼接数据.xlsx', index_col=0, sheet_name=3)
print('df1:\n', df1)
print('df2:\n', df2)
# 也可以使用主键拼接
# 拿取Kx和Ky中共同拥有的值进行主键合并
# res = pd.merge(left=df1, right=df2, how='inner', left_on='Kx', right_on='Ky')
# print('res:\n',res)
# 拿取Kx 与Ky 中所有的值进行主键合并
# res = pd.merge(left=df1, right=df2, how='outer', left_on='Kx', right_on='Ky')
# print('res:\n', res)
# 拿取Kx中所有的值,用Ky里面的值来配合着主键合并
# res = pd.merge(left=df1, right=df2, how='left', left_on='Kx', right_on='Ky')
# # print('res:\n', res)
# 拿取Ky中所有的值,用Kx里面的值配合着进行主键合并
# res = pd.merge(left=df1, right=df2, how='right', left_on='Kx', right_on='Ky')
# print('res:\n', res)
# 加载数据
# df3 = pd.read_excel('./merge主键拼接数据.xlsx', index_col=0, sheet_name=4)
# print('df3:\n', df3)
# 主键合并 ---Kx Ky
# suffixes --->如果合并的两个df中出现相同的列名,会在结果中加入_x _y来区分
# res = pd.merge(left=df1, right=df3, left_on='Kx', right_on='Ky', how='inner')
# print('res:\n',res)
# 主键拼接---只有列方向的拼接合并,没有的行的方向的合并
# join --主键合并方式
# df1.join() ---知道
五、重叠合并-combine_first
数据分析和处理过程中若出现两份数据的内容几乎一致的情况,但是某些特征在其中一 张表上是完整的,而在另外一张表上的数据则是缺失的时候,可以用 combine_first 方法进行 重叠数据合并,其原理如下。

代码实现:
import pandas as pd
# 将多个存在缺失的结构类似的表,可以合并起来,组成一个少量的、甚至没有缺失的表
# 加载数据
df1 = pd.read_excel('./重叠合并数据.xlsx', index_col=0, sheet_name=0)
df2 = pd.read_excel('./重叠合并数据.xlsx', index_col=0, sheet_name=1)
print('df1:\n', df1)
print('df2:\n', df2)
# 使用df2来填充df1
res = df1.combine_first(df2)
print('res:\n', res)
# 对应位置进行填充,如果被填充的df的对应位置上有值,还是原来的值,如果没有值,才会被填充df对应位置的值填充