周志华《机器学习》课后习题(第八章):集成学习

作者 | 我是韩小琦
链接 | https://zhuanlan.zhihu.com/p/51206123
8.1 假设抛硬币正面朝上的概率为 , 反面朝上的概率为 。令 代表抛 次硬币所得正面朝上的次数,则最多 次正面朝上的概率为
. (8.43)
对 有: 不等式
. (8.44)
试推导8.3。
答:
8.3式如下:
.
第一个等式很好理解, 表示 个基分类器中有 个分类器预测错误的概率, 即将所有 下可能预测错误的基分类器个数遍历取总。或者可以直接套用8.43式,
,
其中 表示 个基分类器中,预测正确的个数,即可得第一个等式。
关于第二个不等式,
取8.44中
,
且于是:
于是8.3得证。这里需要注意一点
是建立在 的基础上的。
8.3 从网上下载或自己编程实现 AdaBoost,以不剪枝抉策树为基学习器,在西瓜数据集 3.0α 上训练一个 AdaBoost 集成,并与图 8.4进行比较。
答:
代码在:
https://github.com/han1057578619/MachineLearning_Zhouzhihua_ProblemSets/tree/master/ch8--%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0
这里题目有点问题,如果以不剪枝决策树为基学习器,可以生成一个完美符合数据的决策树,此时AdaBoost就没意义了,因为第一颗树错误率就为0了,样本权重也不会发生改变。
所有这里代码是限定树的深度为2,但训练到第四颗树,错误率就已经到0了,下图给出来的决策边界,其实基本上就是第四颗树的决策了,因为错误率为0,其权重太大。
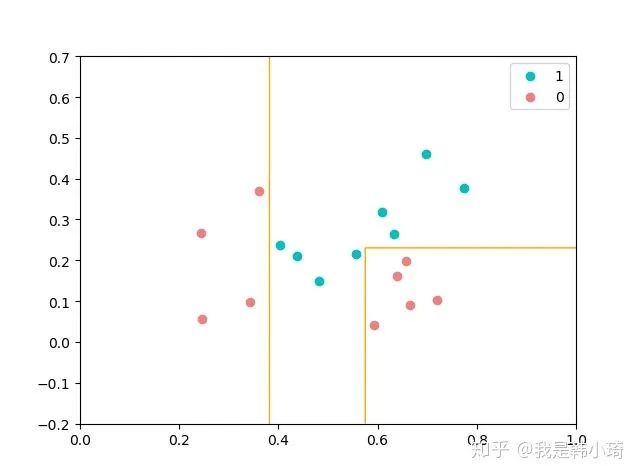
8.4 GradientBoosting [Friedman, 2001] 是一种常用的 Boosting 算法,试析其与 AdaBoost 的异同.
答:
这个问题,网上已经有很多总结了:
Gradient Boosting和其它Boosting算法一样,通过将表现一般的数个模型(通常是深度固定的决策树)组合在一起来集成一个表现较好的模型。抽象地说,模型的训练过程是对一任意可导目标函数的优化过程。通过反复地选择一个指向负梯度方向的函数,该算法可被看做在函数空间里对目标函数进行优化。因此可以说Gradient Boosting = Gradient Descent + Boosting。
和AdaBoost一样,Gradient Boosting也是重复选择一个表现一般的模型并且每次基于先前模型的表现进行调整。不同的是,AdaBoost是通过提升错分数据点的权重来定位模型的不足而Gradient Boosting是通过算梯度(gradient)来定位模型的不足。因此相比AdaBoost, Gradient Boosting可以使用更多种类的目标函数。
参考:机器学习算法中GBDT与Adaboost的区别与联系是什么?
8.5 试编程实现 Bagging,以决策树桩为基学习器,在西瓜数据集 3.0α 上训练一个 Bagging 集戚,井与图 8.6 进行比较.
答:
代码在:han1057578619/MachineLearning_Zhouzhihua_ProblemSets
以决策树桩作为Bagging的基学习器,效果不太好。尝试了下,设置基学习器数量为21时算是拟合最好的,决策边界如下:
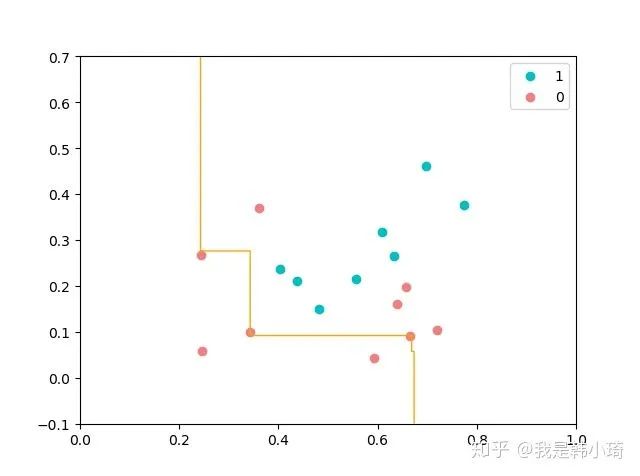
8.6 试析 Bagging 通常为何难以提升朴素贝叶斯分类器的性能.
答:
书中P177和P179提到过:
从偏差—方差分解的角度看, Boosting 主要关住降低偏差,因此 Boosting能基于泛化性能相当弱的学习器构建出很强的集成.
从偏差—方差分解的角度看, Bagging 主要关注降低方差,因此它在不剪枝决策树、神经网络等易受样本扰动的学习器上效用更为明显.
朴素贝叶斯中假设各特征相互独立,已经是很简化模型,其误差主要是在于偏差,没有方差可降。
ps.同样道理,这也是为什么8.5中,以决策树桩为基学习器的Bagging时,效果很差的原因;决策树桩同样是高偏差低方差的模型。
个人理解:
方差大(偏差低)的模型往往是因为对训练数据拟合得过好,模型比较复杂,输入数据的一点点变动都会导致输出结果有较大的差异,它描述的是模型输出的预测值相比于真实值的离散程度,方差越大,越离散,所以为什么Bagging适合以不剪枝决策树、神经网络这些容易过拟合的模型为基学习器;
偏差大(方差低)的模型则相反,往往因为对训练数据拟合得不够,模型比较简单,输入数据发生变化并不会导致输出结果有多大改变,它描述的是预测值和和真实值直接的差距,偏差越大,越偏离真实值。
8.7 试析随机森林为何比决策树 Bagging 集成的训练速度更快.
答:
决策树的生成过程中,最耗时的就是搜寻最优切分属性;随机森林在决策树训练过程中引入了随机属性选择,大大减少了此过程的计算量;因而随机森林比普通决策树Bagging训练速度要快。
系列文章:
1. 周志华机器学习课后习题解析【第二章】
2. 周志华《机器学习》课后习题(第三章):线性模型
3. 周志华《机器学习》课后习题解析(第四章):决策树
4. 周志华《机器学习》课后习题(第五章):神经网络
5. 周志华《机器学习》课后习题(第六章):支持向量机
6. 周志华《机器学习》课后习题(第七章):贝叶斯分类
推荐阅读
(点击标题可跳转阅读)
干货 | 公众号历史文章精选
我的深度学习入门路线
我的机器学习入门路线图
重磅!
AI有道年度技术文章电子版PDF来啦!
扫描下方二维码,添加 AI有道小助手微信,可申请入群,并获得2020完整技术文章合集PDF(一定要备注:入群 + 地点 + 学校/公司。例如:入群+上海+复旦。

长按扫码,申请入群
(添加人数较多,请耐心等待)
最新 AI 干货,我在看 