HtmlParser 一个不错的网站爬虫工具
有时候我们需要在网上获取自己需要的内容时,而且需求量达到一定程度时,就要通过代码来实现重复的操作。
当用Java来帮我们解决这个问题时,我们又如何通过Java来过滤掉多余的内容,剩余自己想要的信息呢,这时HtmlParser会是一个不错的选择。
HtmlParser是一个用java语言写的,用来解析html文件(网页)的应用库,主要的作用就是做网页的信息提取。
HtmlParser提供了许多的过滤器给我们选择,而且使用它只需要下载一个jar包,然后向项目导入jar包就可以引用了。

在这里,笔者使用几个比较常用的过滤器来做网页提取。
首先,我们需要下载HtmlParser的jar包,下载地址:点击打开链接
我们选择最新的1.6的版本,下载完后,解压压缩包,到htmlparser1_6\lib目录下,复制htmlParser.jar文件然后粘贴到你的项目里面,跟着下面步骤操作。

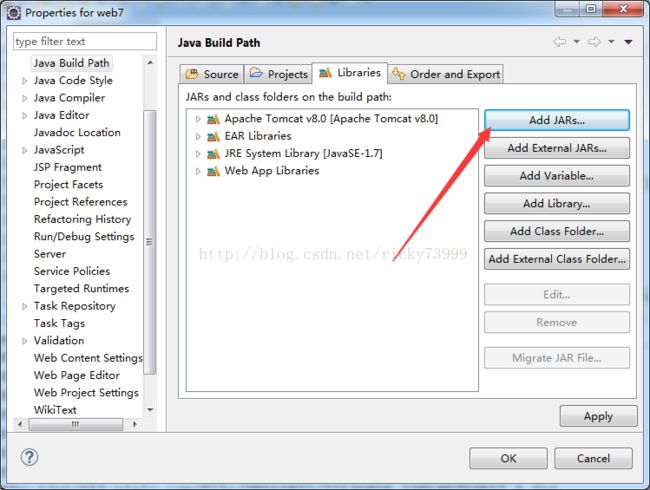
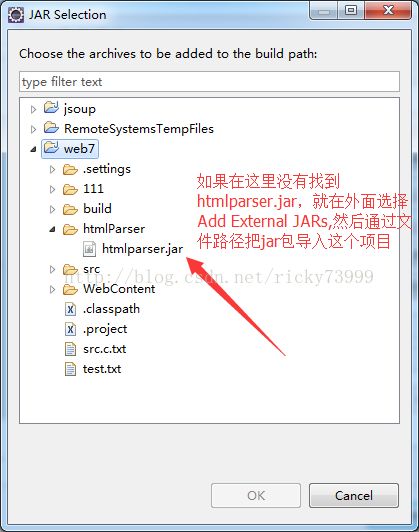
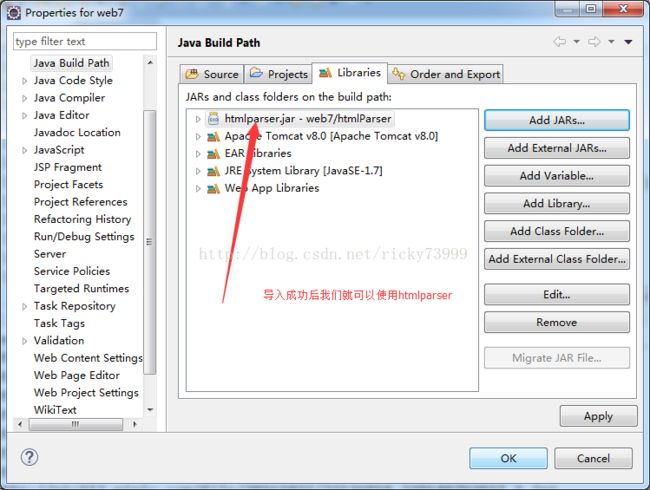
然后,我们就要用htmlparser来为我们提取我们需要的信息
第一种过滤器:LinkStringFilter
(LinkStringFilter(String 属性值)过滤器是根据href连接属性中是否含属性值字段来筛选)
场景:
估计大家都不会讨厌看电影的,那么就先来获取电影的下载链接
(有些人也许会感觉纳闷,直接点击链接不就可以了吗,但当你要获取1000个电影的连接时,你就不会这么觉得了)
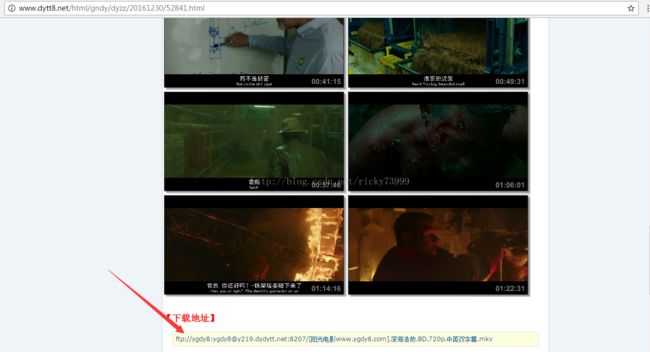
抓取代码并不是这么容易的,要在网页的源代码找到我们需要的信息(也就是下载地址),然后找到这个信息特别的地方,然后利用合适的过滤器去抓取。


下面用代码来获取电影的下载地址(部分代码会有提示):
/**
* 功能:通过电影的介绍地址来获取下载地址
* @param movieIntroUrl:电影的介绍地址
* @return 返回电影的下载地址
*/
public static String getDownloadUrl(String movieIntroUrl) {
String downloadUrl="";
try {
Parser parser=new Parser(movieIntroUrl);
//通过Parser来对Url建立连接,获取该html的内容
parser.setEncoding("GBK");
//设置编码格式
NodeList list=(NodeList) parser.extractAllNodesThatMatch(new LinkStringFilter("ftp"));
//parser.extractAllNodesThatMatch是一个html文本过滤选择器,返回类型是NodeList
//extractAllNodesThatMatch(new 过滤器类型)
//LinkStringFilter(String 属性值)过滤器是根据href连接属性中是否含属性值字段来筛选
for(int i=0;i System.out.println(downloadUrl);
} catch (ParserException e) {
e.printStackTrace();
}
return downloadUrl;
}public static void main(String[] args) {
getDownloadUrl("http://www.dytt8.net/html/gndy/dyzz/20161230/52841.html");
}
第二种过滤器:HasAttributeFilter
(HasAttributeFilter(String 属性名,String 属性值)根据对应的属性名是否存在这样的属性值查找元素)
这个过滤器的功能强大一些,但是有一些地方需要注意,不是包含属性值,只能找到完全相等的属性值的元素
场景:

有些网页有许多部电影,如果你想把这些电影的下载地址全部获取,怎么办?
点击这些链接,只是进去电影的介绍界面,里面才有我们要的下载地址,也就是一个电影至少要点击两次才能下载电影,重复的事情让代码帮我们去完成吧。
分析:首先我们要进入每个电影的介绍界面才能获取电影的下载地址,那么我们就要把它们的介绍地址全部拿过来,然后再循环进入到这些介绍界面获取我们最爱的下载地址。查看网页的源代码寻找一些这些链接的规律。


下面来获取电影的介绍地址(部分代码有提示):
/**
* 功能:获取一个分页里面的所有电影的介绍地址
* @param pageListUrl 分页的地址
* @return 返回一个String[]用于存储这个分页的所有的电影的介绍地址
*/
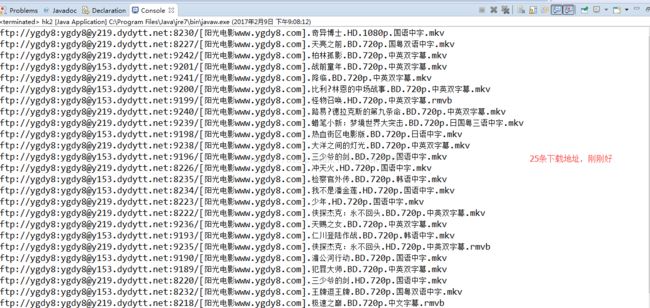
public static String[] getIntroUrlFromPageList(String pageListUrl) {
String movieIntroUrl[]=new String[25];
//定义String数组,储存介绍地址,注意长度一定要刚刚好,否则会出现错误
try {
Parser parser=new Parser(pageListUrl);
parser.setEncoding("GBK");
NodeList list=(NodeList)parser.extractAllNodesThatMatch(new HasAttributeFilter("class","ulink"));
//HasAttributeFilter(String 属性名,String 属性值)根据对应的属性名是否存在这样的属性值查找元素
//注意不是包含属性值,只能找到完全相等属性值的元素
for(int i=0;i
public static void main(String[] args) {
String introUrl[]=new String[25];
introUrl=getIntroUrlFromPageList("http://www.ygdy8.net/html/gndy/dyzz/index.html");
for (int i = 0; i < introUrl.length; i++) {
String downloadUrl=getDownloadUrl(introUrl[i]); }
}
第三种过滤器:TagNameFilter
(TagNameFilter(String 标签名),根据标签名来查找对应的元素)
这个过滤器一般结合其他过滤器来使用,单独使用的查找效果很低,这里就不作范例了。
其他过滤器的使用方法与使用效果可以去查看htmlparser的API文档:点击打开链接