饿了么元数据管理实践之路
本文转载自dbaplus社群(ID:dbaplus)

王金海
饿了么大数据平台架构师
多年大数据平台开发架构实践,曾在唯品会担任人群个性化推荐研发工作;
目前主要负责饿了么大数据平台的调度系统和元数据系统架构研发。
大数据时代,饿了么面临数据管理、数据使用、数据问题等多重挑战。具体可以参考下图:

数据问题:多种执行、存储引擎,分钟、小时、天级的任务调度,怎样梳理数据的时间线变化?
数据使用:任务、表、列、指标等数据,如何进行检索、复用、清理、热度Top计算?
数据管理:怎样对表、列、指标等进行权限控制、任务治理以及上下游依赖影响分析?
元数据打通数据源、数据仓库、数据应用,记录了数据从产生到消费的完整链路。它包含静态的表、列、分区信息(也就是MetaStore);动态的任务、表依赖映射关系;数据仓库的模型定义、数据生命周期;以及ETL任务调度信息、输入输出等。
元数据是数据管理、数据内容、数据应用的基础。例如可以利用元数据构建任务、表、列、用户之间的数据图谱;构建任务DAG依赖关系,编排任务执行序列;构建任务画像,进行任务质量治理;数据分析时,使用数据图谱进行字典检索;根据表名查看表详情,以及每张表的来源、去向,每个字段的加工逻辑;提供个人或BU的资产管理、计算资源消耗概览等。
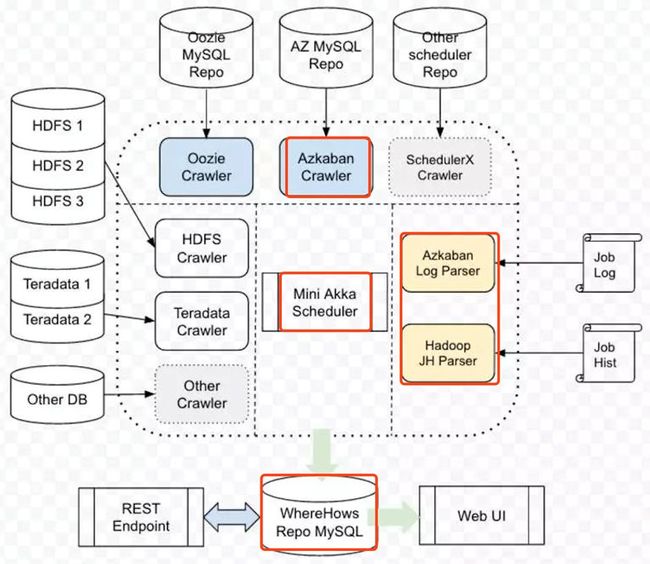
WhereHows是LinkedIn开源的元数据治理方案。Azkaban调度器抓取job执行日志,也就是Hadoop的JobHistory,Log Parser后保存DB,并提供REST查询。WhereHows太重,需要部署Azkaban等调度器,以及只支持表血缘,功能局限。
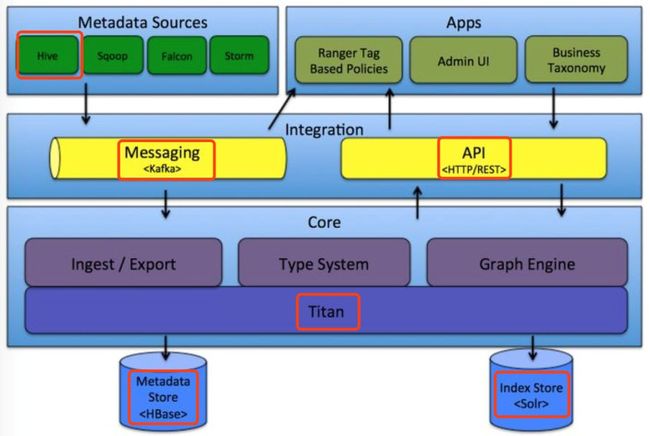
Atlas是Apache开源的元数据治理方案。Hook执行中采集数据(比如HiveHook),发送Kafka,消费Kafka数据,生成Relation关系保存图数据库Titan,并提供REST接口查询功能,支持表血缘,列级支持不完善。
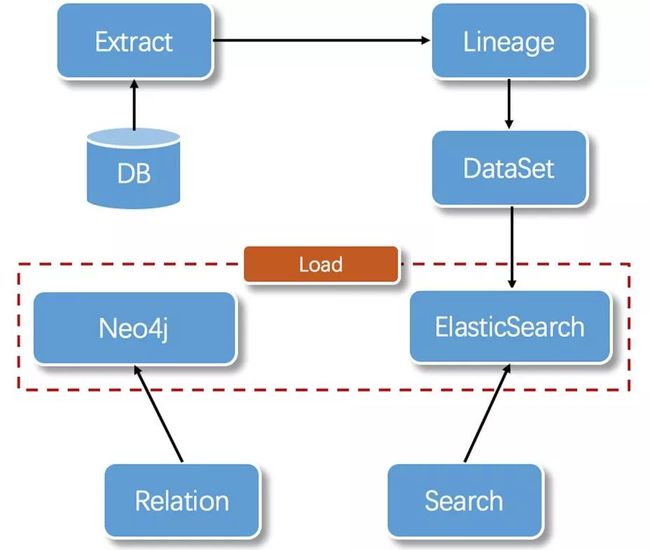
DB保存任务的SQL数据、任务基础信息、执行引擎上下文信息;
Extract循环抽取SQL并解析成表、列级血缘Lineage;
DataSet包含Lineage关系数据+任务信息+引擎上下文;
将DataSet数据集保存到Neo4j,并提供关系查询;保存ES,提供表、字段等信息检索。
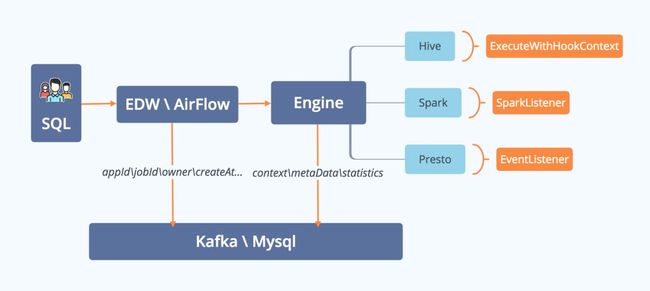
饿了么的SQL数据,以执行中采集为主+保存前submit为辅。因为任务的SQL可能包含一些时间变量,比如dt、hour,以及任务可能是天调度、小时调度。执行中采集SQL实时性更高,也更容易处理。
EDW是饿了么的调度系统,类比开源的AirFlow。调度系统执行任务,并将任务相关的信息,比如appId、jobId、owner、SQL等信息存入DB。
计算引擎实现相关的监听接口,比如Hive实现Execute With Hook Context接口;Spark实现Spark Listener接口;Presto实现Event Listener接口。将计算引擎相关的上下文Context、元数据MetaData、统计Statistics等信息存入DB。
解析SQL的方案,以Hive为例。先定义词法规则和语法规则文件,然后使用Antlr实现SQL的词法和语法解析,生成AST语法树,遍历AST语法树完成后续操作。
但对于SELECT *、CTAS等操作,直接遍历AST,不去获取Schema信息来检查表名、列名,就无法判定SQL的正确性,导致数据污染。
综上所述,饿了么的SQL解析方案,直接参考Hive的底层源码实现。
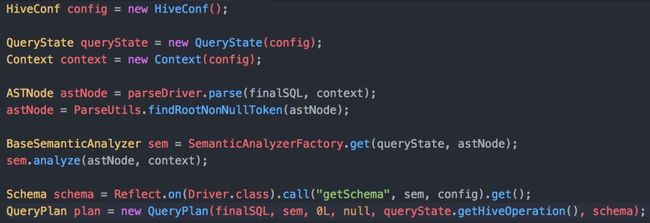
以本土做简单示例,先经过Semantic Analyzer Factory类进行语法分析,再根据Schema生成执行计划QueryPlan。关于表、列的血缘,可以从LineageInfo、LineageLogger类中获得解决方案。
当然,你需要针对部分类型SQL设置Hive Conf,比如“开启动态分区非严格模式”。对于CTAS类型,需要设置Context。UDF函数需要修改部分Hive源码,避免UDF Registry检查。
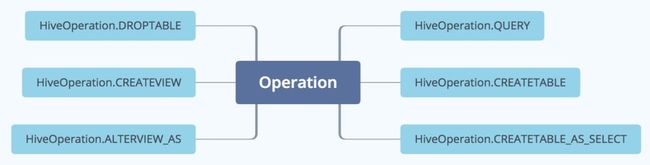
饿了么解析血缘的SQL支持的操作有:Query(包含select\insert into\insert overwrite)、CreateTable、CreateTableAsSelect、DropTable、CreateView、AlterView。基本覆盖饿了么生产环境99%+的SQL语法。
![]()
举个栗子,根据上面的SQL,分别产生表、列血缘结构。
input是表、列输入值;output是表、列输出值;operation代表操作类型。比如表A+B通过insert,生成表C,则延展成A insert C; B insert C。
列式也一样:
input:name,
operation: coalesce(name, count(id)),
output: lineage_name;
input: id,
operation: coalesce(name, count(id)),
output:lineage_name
表血缘结构
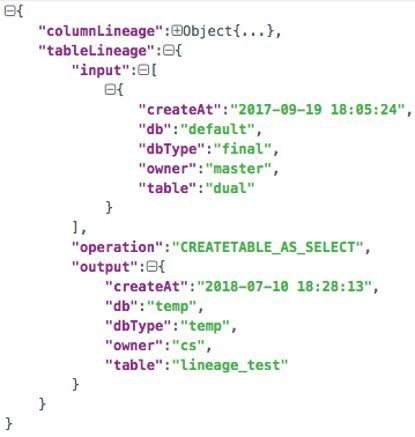
列血缘结构

图存储
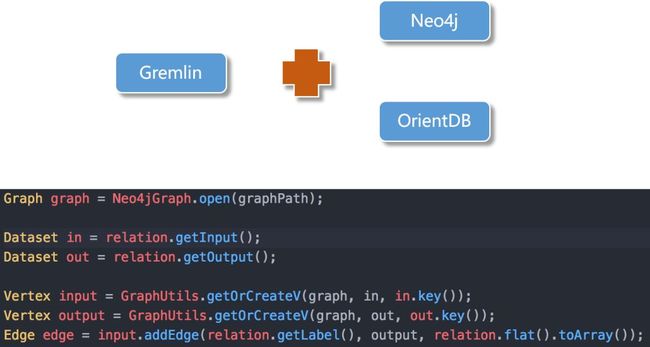
有了input、operation、output关系,将input、output保存为图节点,operation保存为图边。图数据库选用Gremlin+Neo4j。
Gremlin是图语言,存储实现方案比较多,Cypher查询不太直观,且只能Neo4j使用。社区版Neo4j只能单机跑,我们正在测试OrientDB。
下面是饿了么在元数据应用上的部分场景:

静态的Hive MetaStore表,比如DBS、TBLS、SDS、COLUMNS_V2、TABLE_PARAMS、PARTITIONS,保存表、字段、分区、Owner等基础信息,便于表、字段的信息检索功能。
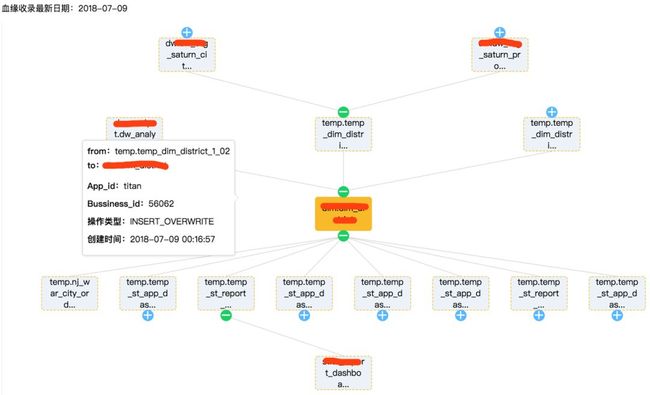
提供动态的表依赖血缘关系查询。节点是表基础信息,节点之间的边是Operation信息,同时附加任务执行Id、执行时间等属性。列血缘结构展示等同表血缘结构。
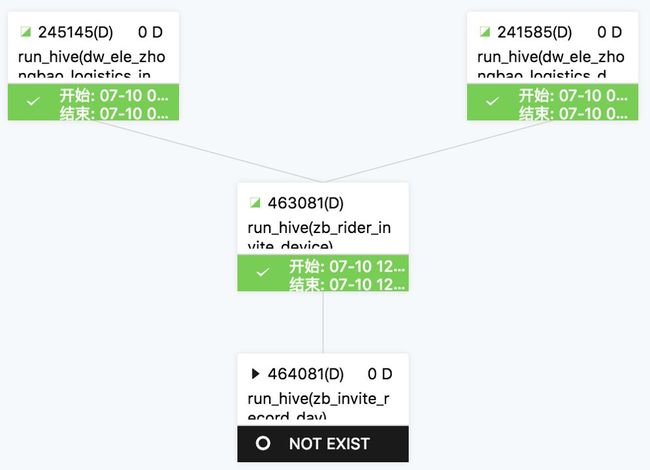
根据SQL的input、output构建表的依赖关系,进一步构建任务的DAG依赖结构。可以对任务进行DAG调度,重新编排任务执行序列。
Q1:咱们的数据生命周期是如何管理的,能具体说下吗?
A:表级数据进行热度分析,比如近三个月没人访问,是否可以下线,特别是一些临时表 需要定时清理。
Q2:质量监控会影响到任务调度编排么?
A:会影响质量编排,构建DAG依赖执行。
Q3:把从SQL中的埋点数据存储到MySQL中,是如何规划的?这些埋点信息不应该像是日志数据一样被处理吗?存储在MySQL中是有自增全局ID的么?还是说你们是对任务和表分别有MySQL表,然后更新MySQL表中任务和表甚至列的信息么?这里的MySQL表就是您说的DataSet么?
A:任务jobid进行唯一,MySQL只保存执行的SQL,以及任务本身的信息,比如owner time jobid等等。
Q4:当前的支持非SQL形式生成表么?比如直接用Spark RDD任务或者Spark MLlib任务取表和生成表?
A:只支持SQL表达。
Q5:你们是怎么做热度分析的?刚才的讲解里,这个点讲得比较少。
A:任务操作的SQL产生input output表,对表进行counter就能top counter,列也一样。
Q6:你们管理的表分线上表和线下表么?在处理的时候用到了一些临时表该怎么处理?
A:对的,线上还是线下,任务调度系统埋点,临时表根据temp就知道了。
Q7:数据血缘关系如果使用Hive hook方式获取,是需要在每个执行节点中做捕捉吗?
A:Hive hook就是执行时调用,可以去了解下底层。
Q8:解析那种复杂度很高的HQL的血缘,你们平台的解析思路是什么样子的?如何保证正确率呢?
A:会有很多复杂的ppt有代码示例,会有部分SQL需要修改Hive解析实现。
Q9:表血缘图里面的上下级关系就是数据的流向?从上到下?字段的血缘是什么样子的跟表的血缘有什么不同?有字段的血缘图吗?
A:ppt里解析那里可以看到,字段也一样,input output列然后operation
Q10:SQL埋点,引擎埋点,是要去重写Hive等的源码吗?
A:重写倒不至于,只要实现ppt里的接口,很简单。
https://m.qlchat.com/topic/details?topicId=2000001595812012
