零基础实战行人重识别ReID项目-基于Milvus的以图搜图
目录
第一阶段,ReID的基本概念
1.1 ReID定义
1.2 技术难点
1.3 常用数据集
1.4 评价指标
1.5 实现思路
1.6 具体方案
第二阶段:复现算法
2.1 PCB的骨干网络
2.2 PCB的流程
2.3 PCB的细节
2.4 PCB-RPP
2.5 算法复现
第三阶段:工程化落地
3.1 业务逻辑
3.2 Milvus
3.3 以图搜图
3.4 效果展示
加入学习小组
近期正在学习ReID,完全零基础,打算复现几种主流的ReID算法,并进行工程化落地。
学习目标:掌握ReID的算法原理、实现方案,动手搭建网络模型,在数据集上复现算法。
学习内容:阅读相关资料、论文、开源代码,复现算法,工程化落地。
如果你也在学习ReID,欢迎加入免费学习小组,加入方式见文末。
第一阶段,ReID的基本概念
包括 ReID的定义、常用数据集、评价指标、实现思路
推荐一个视频教程:https://edu.csdn.net/huiyiCourse/detail/788,可下载配套PPT
这个博客对视频进行了总结:https://blog.csdn.net/ctwy291314/article/details/83618646

1.1 ReID定义
全称Person Re-Identification,主要解决跨摄像头跨场景下行人的识别与检索。该技术可以作为人脸识别技术的重要补充,可以对无法获取清晰拍摄人脸的行人进行跨摄像头连续跟踪,增强数据的时空连续性。
1.2 技术难点
相机拍摄角度,图片模糊不清楚,室内室外环境变化,行人更换服装饰配,冬季夏季风格差异,白天晚上光线差异等。
1.3 常用数据集
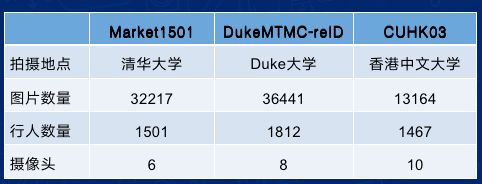
Market1501 http://liangzheng.com.cn/Project/project_reid.html 网站挂了,联系我提供下载地址
DukeMTMC-reID https://github.com/sxzrt/DukeMTMC-reID_evaluation#download-dataset
CUHK03 http://www.ee.cuhk.edu.hk/~xgwang/CUHK_identification.html
1.4 评价指标
Rank1:首位命中率
mAP:平均精度均值
CMC:累计匹配曲线
参考:https://zhuanlan.zhihu.com/p/40514536
https://blog.csdn.net/qq_38451119/article/details/83000061
1.5 实现思路
a.检索图经过网络抽取图片特征(Feature) ;
b.底库里的所有图片全部抽取图片特征(Feature) ;
c.将检索图与地库图的特征计算距离(例如欧式距离) ;
d.根据计算距离进行排序,排序越靠前表示是相似率越高。
1.6 具体方案
| 方案 | 性能 | 对应论文 |
| 方案一:表征学习 基于SoftmaxLoss(分类损失)与 ContrastiveLoss(对比损失) |
Rank1: 79.51% mAP: 59.87% |
Z.Zheng,L.Zheng,andY.Yang. A discriminatively learned cnn embedding for person re-identification. arXiv preprint arXiv:1611.05666, 2016. |
| 方案二:度量学习 基于Triplet Loss(三元损失) |
Rank1: 84.92% mAP: 69.14% |
A.Hermans, L. Beyer, and B. Leibe. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, 2017. F. Schroff, D. Kalenichenko, and J. Philbin. FaceNet: A Unified Embedding for Face Recognition and Clustering. In CVPR, 2015. 1, 2, 3, 5 |
| 方案三:局部特征学习 3.1 基于局部区域调整 |
Rank1: 80.31% mAP: 57.53% |
L. Zhao, X. Li, J. Wang, and Y. Zhuang. 2017. Deeply-learned part-aligned representations for person re-identication. In CVPR. |
| 3.2 基于姿态估计局部特征调整 | Rank1: 84.14% mAP: 63.41% |
C. Su, J. Li, S. Zhang, J. Xing, W. Gao, and Q. Tian. 2017. Pose-driven Deep Convolutional Model for Person Re-identication. In CVPR. |
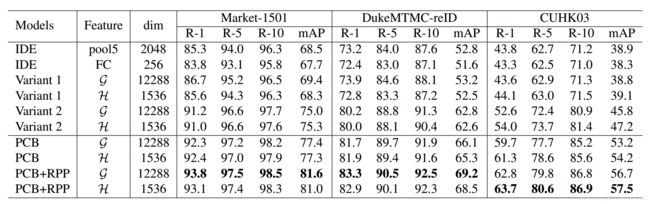
| 3.3 PCB | Rank1: 93.8% mAP:81.6% | Y. Sun, L. Zheng, Y. Yang, Q. Tian, and S. Wang. Beyond part models: Person retrieval with refined part pooling. arXiv preprint arXiv:1711.09349, 2017. |
第二阶段:复现算法
2.1 PCB的骨干网络
选取上述的PCB方案,搭建网络,训练模型。
PCB使用修改版的ResNet-50作为骨干网,下图是ResNet不同层数的网络结构,
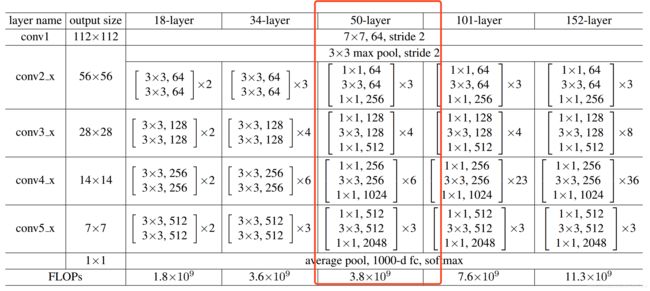
图片来自ResNet论文: Deep Residual Learning for Image Recognition
ResNet论文中指出,Downsampling is performed by conv3 1, conv4 1, and conv5 1 with a stride of 2.
所以,原始的ResNet-50 的下采样倍数为2^5 = 32倍,即输入的图像到输出的特征图缩小了32倍。
而PCB论文中指出,输入尺度为384x128(高比宽为3:1),经过骨干网络后,输出的特征图尺度为24x8,
所以下采样比例为16,因此,ResNet-50中 conv5_1的stride需要由2改为1.
2.2 PCB的流程
结合下图,介绍PCB的流程:
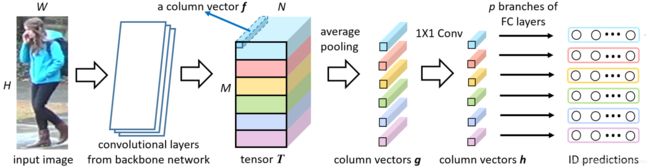
1.输入图像,尺度为 高384 x 宽128 x 通道3,送入修改后的ResNet-50,输出特征图T,尺度为 高24 x 宽8 x 通道2048
2.将T在高的维度上等分为6份,分别执行平均池化,得到向量g,尺度为 6 x 1 x 1 x 2048
3.对向量g执行1x1卷积,得到向量h,尺度为6 x 1 x 1 x 256
4.对每个向量h送入 256 x 751 全连接层的分类训练
疑问:得到6个分类向量后,行人分类是怎么处理的?
参考论文中的这么一段:

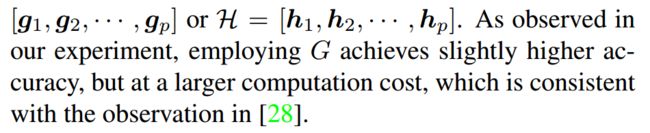
2.3 PCB的细节
训练阶段,输入图像,得到T、g、h,再经过全连接层得到6个1x751的向量,对这6个1x751的向量分别计算分类损失再累加。
测试阶段,输入图像,得到6个1x2048的g向量,然后对其进行拼接,得到一个1x12288的向量,(或者使用拼接后的h向量 1x1536) 用这个与特征库中的向量进行匹配,找到距离最近的作为检索结果。
用代码来解释最为直观:
参考项目:https://github.com/layumi/Person_reID_baseline_pytorch
项目的中文版解析:https://zhuanlan.zhihu.com/p/50387521
从train.py中的第215行可以看出,训练阶段,对6个全连接层的结果分别计算softmax,进行累加后,作为分类的预测值,
从第220行可以看出,对6个部分分别计算交叉熵损失,再将6个损失值累加,得到最终的loss
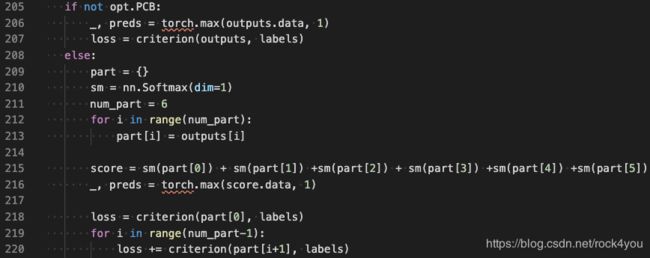
从test.py的第158行可以看出,提取特征时,取的是上述流程图中的g,即尺度为6x2048的特征向量
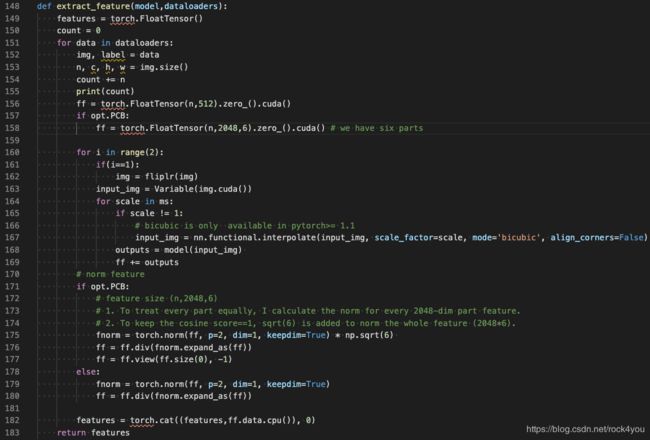
在实现细节上,代码中分别对6个分片除以它们的2范数,目的是降低不同维度上取值范围的差异性(可以理解为归一化)。
2.4 PCB-RPP
论文里还提出了PCB的改进策略:RPP - Refined Part Pooling
T中直接进行了6等分,但被强行分到同一个区域内的向量可能并不相似,特别是位于分界线两侧的那些向量。
RPP的目标就是对每个区域内的向量进行重新分配。通过计算f与g之间的余弦距离,找到与f最相近的g,将该 f 划分到对应的 g 区域内,划分结果如下图中右侧所示。
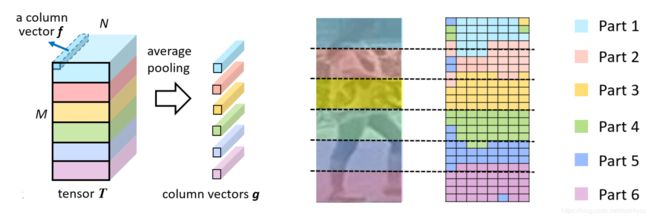
RPP通过一个线性层紧接着一个softmax激活层,对每个 f 向量进行区域分类。
得到分类之后的T,再对属于同一分区的f计算均值,得到6个分区的平均值向量g,后续结果与PCB流程相同。
RPP的流程如下:
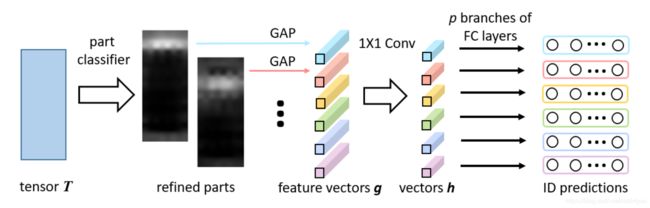
论文提供了两个变种的方案:
Variant 1. 将所有h向量平均,得到单个h向量,送入全连接层进行分类训练;测试阶段,将g或h进行拼接,再进行分类。
Variant 2. 网络结构不变,只是将全连接层进行权值共享。
以及IDE ( 论文 Person reidentification: Past, present and future中的方案,本文对其进行了相应的改进)
并给出了不同方案的测试结果:
2.5 算法复现
推荐一个网站:https://www.paperswithcode.com/
专门用于查找论文复现的项目代码,比如PCB的搜索结果:
PCB的训练过程已在百度AI Studio上使用PaddlePaddle进行复现,源码:
https://aistudio.baidu.com/aistudio/projectdetail/468702
项目仍在更新维护中,欢迎提出宝贵意见。
第三阶段:工程化落地
3.1 业务逻辑
基于PCB-RRP封闭环境下的ReID工程化落地的业务逻辑:
1.加载ResNet-50预训练网络模型,修改分类数目,在Market-1501数据集上继续训练网络;
2.对Market-1501数据集中的751个行人分别计算特征向量,存储备用;
3.获取一个行人的图片,提取特征向量,然后与751个特征进行比较,找到与之距离最小的1个或多个特征对应的原图作为备选结果。
其实上述的场景已经很接近于以图搜图了,只不过数据集是封闭的,而且量也不大。
虽然不是大规模的数据,但也可以借此机会感受一下以图搜图的完整流程。
3.2 Milvus
这里隆重介绍一款开源的特征向量相似度搜索引擎 Milvus https://www.milvus.io/cn/

3.3 以图搜图
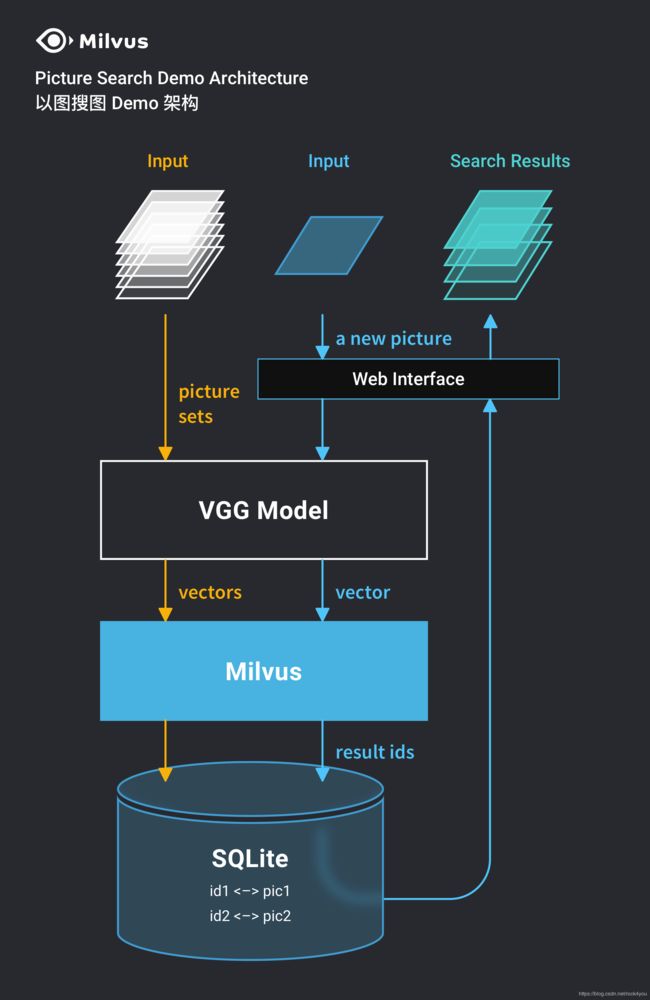
官方提供了【基于 Milvus 和 VGG 实现以图搜图】项目的源码:
https://github.com/milvus-io/bootcamp/blob/master/solutions/pic_search/README.md
内置了VGG网络用于提取图像特征,用户只需要提供训练集和待测试的图片即可,特征提取、匹配过程对用户完全透明。
架构如图所示:
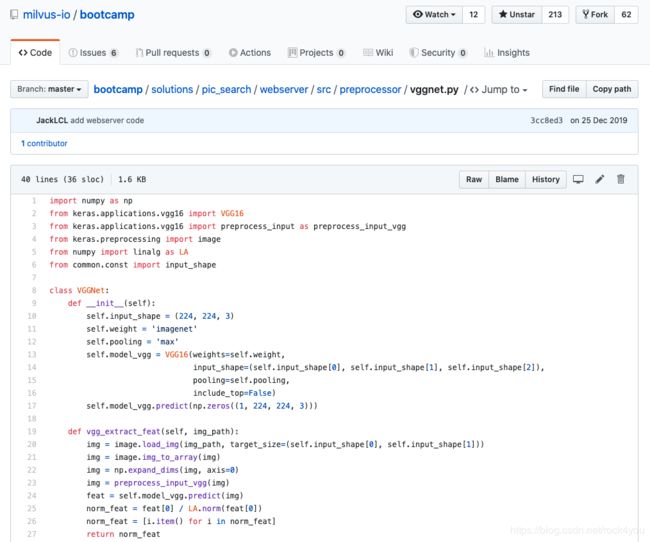
如需使用其他网络模型、修改图像resize后的尺寸,则需要修改源代码:
webserver / src / preprocessor/ vggnet.py
修改网络后,需要提供预训练模型文件,
位于webserver / data / models / 路径下:

可参考官网的博客:
【Milvus带你实现轻松搭建以图搜图系统】https://zilliz.blog.csdn.net/article/details/103884272
3.4 效果展示
本人使用Market-1501的bounding_box_test文件夹中19732张图片作为底库,使用query文件夹中的图片进行检索,效果如下:
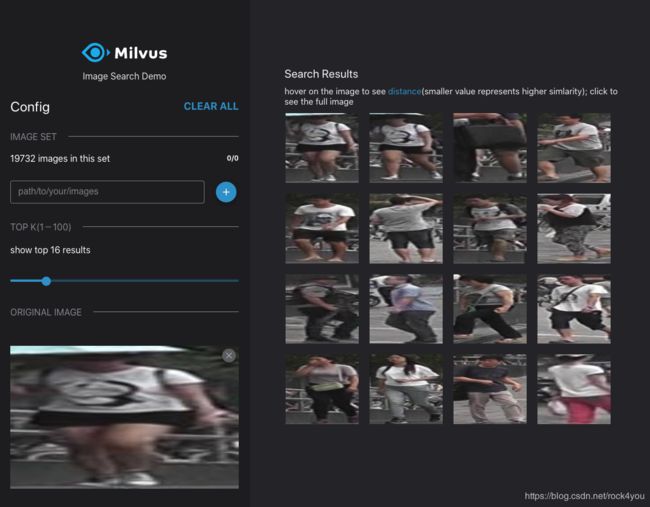
Milvus提供的以图搜图解决方案中,使用的骨干网络是VGG-16,图片需要resize为224*224再送入进行特征提取,展示框的宽高比是1 : 1,导致图像有点变形。
而Market-1501数据集中的图片都是细长条状的,因此目前默认环境还不太符合实际应用场景。
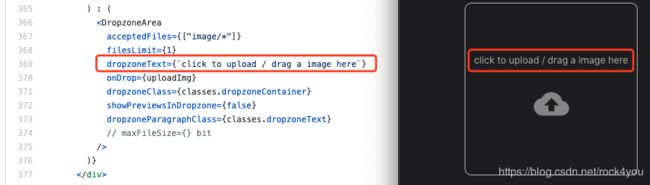
修改展示界面中图像的宽高比:
bootcamp/solutions/pic_search/webclient/src/containers/Setting.tsx
通过网页中的关键字找到对应的位置:
通过对应的容器名,找到对应的配置参数:

修改benchImage中的width和height,即可修改待检索图片的展示效果。
可以改为:
width: "auto",
height:"250px",
而第126行、第127行的像素值,是预览框的尺寸,这个跟最后的展示没有关系,不需要改。
搜索结果宽高比的修改:
bootcamp/solutions/pic_search/webclient/src/components/Gallary.tsx
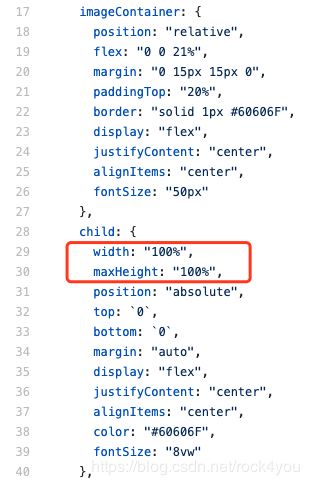
将child中的width和maxHeight分别改为:
width: "auto",
//maxHeight: "100%", 注释掉
height:"100%",
重新构建镜像:
# 构建镜像
$ docker build -t pic-search-webclient .效果如下:
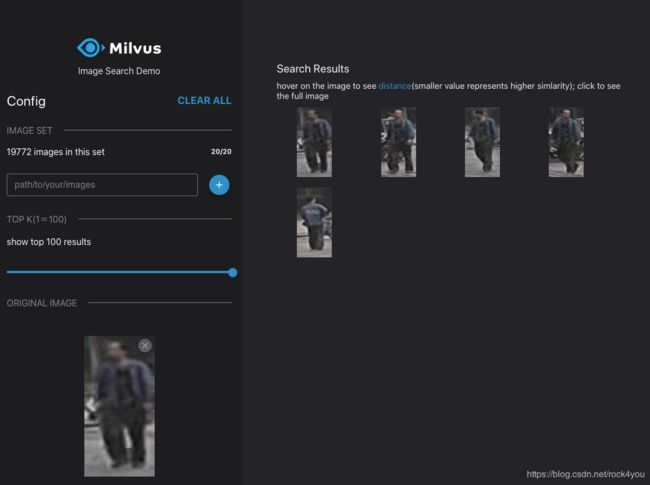
后续工作:在界面中显示搜索结果的图片名称、修改骨干网络的输入尺度、修改提取特征的骨干网络。
未完待续。
加入学习小组
关注公众号,回复 “组队”,加入免费学习小组
回复 “reid”,打包下载上述PPT和6篇论文。