【Paper Note】Deep Session Interest Network for Click-Through Rate Prediction论文详解

介绍
通常来讲,在用户的行为序列中,每个会话(Session)的行为是相似的,在不同的会话之间差异较大,阿里的这篇论文中,根据时间间隔来定义会话,将用户点击行为按照时间排序,如果两个行为的时间间隔大于30min则进行切分。如下图所示:

从图中可以观察,第一个会话中,用户点击的feed为裤子,第二个则是首饰,第三个是衣服,符合上面说的会话的特征。DSIN就是基于此进行用户行为建模。
DSIN模型的几点贡献:
- 会话内同质,会话间异质
- 在DSIN中使用了self-attention、bias embedding、Bi-LSTM,模型更能捕捉不同会话间的用户兴趣偏好
模型介绍
Base Model
Base Model是一个全连接网络。
特征主要由三部分:user特征、item特征,用户行为特征。user特征主要是性别、城市等,item特征主要是id,品牌等,用户行为特征主要是用户点击行为。此外,在代码中,稠密特征是加在模型的最后的,后面代码中会有说明。
embedding主要将稀疏特征编码成稠密向量。
Loss Function为negative log-likelihood function:
(1) L = − 1 N ∑ ( x , y ) ∈ D ( y l o g p ( x ) + ( 1 − y ) l o g ( 1 − p ( x ) ) ) L=-\frac{1}{N}\sum_{(x,y)\in D}{(y\ log\ p(x)+(1-y)\ log(1-p(x)))} \tag{1} L=−N1(x,y)∈D∑(y log p(x)+(1−y) log(1−p(x)))(1)
模型
模型总体架构如下:
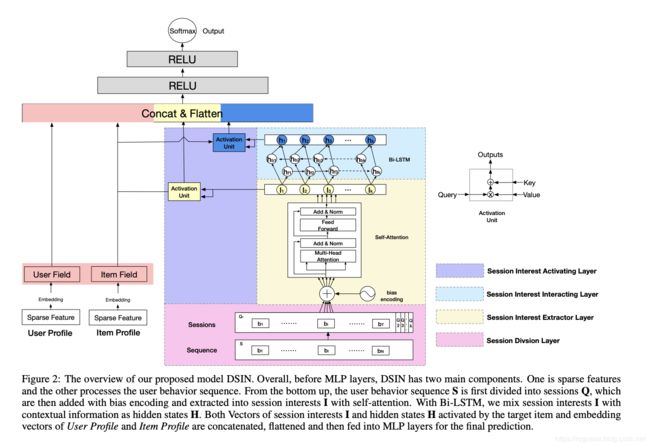
全连接之前,主要由以下两部分:左边user特征和item特征的向量表示,生成embedding向量;右边是对用户行为处理部分,该部分主要分为四层:
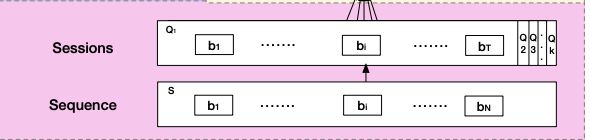
(1)Session Division Layer
对用户的历史行为序列进行切分,按照时间排序,时间间隔大于30min则进行切分。论文中将用户行为序列S切分成K个会话Q,第k个会话为: Q k = [ b 1 ; b 2 ; ⋯ ; b i ; ⋯ ; b T ] Q_k=[b_1;b_2;\cdots;b_i;\cdots;b_T] Qk=[b1;b2;⋯;bi;⋯;bT],其中, T T T为会话长度, b i b_i bi是会话中第i个行为,并且, b i ∈ R d b_i\in R^d bi∈Rd, Q k ∈ R T ∗ d Q_k\in R^{T*d} Qk∈RT∗d,所以 Q ∈ R K ∗ T ∗ d Q\in R^{K*T*d} Q∈RK∗T∗d
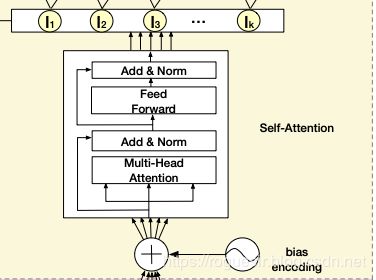
(2)Session Interest Extractor Layer
论文中对每个会话进行Transformer处理,可通过代码得知:
# Session Interest Extractor Layer
Self_Attention = Transformer(att_embedding_size,
att_head_num,
dropout_rate=0,
use_layer_norm=False,
use_positional_encoding=(not bias_encoding), # bias_encoding=False
seed=seed,
supports_masking=True,
blinding=True)
在Transformer过程中,进行了positional_encoding处理,也就是论文中说的Bias Embedding,定义如下:
(2) B E ( k , t , c ) = w k K + w t T + w c C BE_{(k,t,c)}=w^K_k+w^T_t+w^C_c \tag{2} BE(k,t,c)=wkK+wtT+wcC(2)
B E ∈ R K ∗ T ∗ d BE\in R^{K * T * d} BE∈RK∗T∗d,和Q的维度相同。 B E ( k , t , c ) BE_{(k,t,c)} BE(k,t,c)表示第k个session中,第t个物品的embedding向量的第c个位置的偏置项,也就是说,每个会话、会话中的每个物品有偏置项外,每个物品对应的embedding的每个位置,都加入了偏置项。所以加入偏置项后,Q变为:
(3) Q = Q + B E Q=Q+BE \tag{3} Q=Q+BE(3)
随后进行Transformer处理,输出为用户的兴趣向量:
(4) I k = A v g ( I k Q ) I_k=Avg(I^Q_k) \tag{4} Ik=Avg(IkQ)(4)
(3)Session Interest Interacting Layer
兴趣交互层使用Bi-LSTM,具体的计算流程如下:
(5) i t = σ ( W x i I t + W h i h t − 1 + W c i c t − 1 + b i ) i_t=\sigma(W_{xi}I_t+W_{hi}h_{t-1}+W_{ci}c_{t-1}+b_i) \tag{5} it=σ(WxiIt+Whiht−1+Wcict−1+bi)(5) (6) f t = σ ( W x f I t + W h f h t − 1 + W c f c t − 1 + b f ) f_t=\sigma(W_{xf}I_t+W_{hf}h_{t-1}+W_{cf}c_{t-1}+b_f) \tag{6} ft=σ(WxfIt+Whfht−1+Wcfct−1+bf)(6) (7) c t = f t c t − 1 + i t t a n h ( W x c I t + W h c h t − 1 + b c ) c_t=f_tc_{t-1}+i_t\ tanh(W_{xc}I_t+W_{hc}h_{t-1}+b_c) \tag{7} ct=ftct−1+it tanh(WxcIt+Whcht−1+bc)(7) (8) o t = σ ( W x o I t + W h o h t − 1 + W c o c t − 1 + b c ) o_t=\sigma(W_{xo}I_t+W_{ho}h_{t-1}+W_{co}c_{t-1}+b_c) \tag{8} ot=σ(WxoIt+Whoht−1+Wcoct−1+bc)(8) (9) h t = o t t a n h ( c t ) h_t=o_t\ tanh(c_t) \tag{9} ht=ot tanh(ct)(9)
每个时刻的hidden state为前向传播和反向传播的hidden state的和。

(4)Session Interest Activating Layer
激活单元使用注意力机制:
(10) a k I = e x p ( I k W I X I ) ∑ k K e x p ( I k W I X I ) a^I_k=\frac{exp(I_kW^IX^I)}{\sum^K_k exp(I_kW^IX^I)} \tag{10} akI=∑kKexp(IkWIXI)exp(IkWIXI)(10) (11) U I = ∑ k K a k I I k U^I=\sum^K_k{a^I_kI_k} \tag{11} UI=k∑KakIIk(11) (12) a k H = e x p ( H k W H X I ) ∑ k K e x p ( H k W H X I ) a^H_k=\frac{exp(H_kW^HX^I)}{\sum^K_k exp(H_kW^HX^I)} \tag{12} akH=∑kKexp(HkWHXI)exp(HkWHXI)(12) (13) U H = ∑ k K a k H H k U^H=\sum^K_k{a^H_kH_k} \tag{13} UH=k∑KakHHk(13)

代码
代码部分主要介绍模型主体结构,训练脚本不做说明。GitHub地址:https://github.com/shenweichen/DSIN
# coding: utf-8
"""
Author:
Weichen Shen,[email protected]
Reference:
[1] Feng Y, Lv F, Shen W, et al. Deep Session Interest Network for Click-Through Rate Prediction[J]. arXiv preprint arXiv:1905.06482, 2019.(https://arxiv.org/abs/1905.06482)
"""
from collections import OrderedDict
from tensorflow.python.keras.initializers import RandomNormal
from tensorflow.python.keras.layers import (Concatenate, Dense, Embedding,
Flatten, Input)
from tensorflow.python.keras.models import Model
from tensorflow.python.keras.regularizers import l2
from deepctr.input_embedding import (create_singlefeat_inputdict,
get_embedding_vec_list, get_inputs_list)
from deepctr.layers.core import DNN, PredictionLayer
from deepctr.layers.sequence import (AttentionSequencePoolingLayer, BiasEncoding,
BiLSTM, Transformer)
from deepctr.layers.utils import NoMask, concat_fun
from deepctr.utils import check_feature_config_dict
def DSIN(feature_dim_dict, sess_feature_list, embedding_size=8, sess_max_count=5, sess_len_max=10, bias_encoding=False,
att_embedding_size=1, att_head_num=8, dnn_hidden_units=(200, 80), dnn_activation='sigmoid', dnn_dropout=0,
dnn_use_bn=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, init_std=0.0001, seed=1024, task='binary',
):
"""Instantiates the Deep Session Interest Network architecture.
:param feature_dim_dict: dict,to indicate sparse field (**now only support sparse feature**)like {'sparse':{'field_1':4,'field_2':3,'field_3':2},'dense':[]}
:param sess_feature_list: list,to indicate session feature sparse field (**now only support sparse feature**),must be a subset of ``feature_dim_dict["sparse"]``
:param embedding_size: positive integer,sparse feature embedding_size.
:param sess_max_count: positive int, to indicate the max number of sessions
:param sess_len_max: positive int, to indicate the max length of each session
:param bias_encoding: bool. Whether use bias encoding or postional encoding
:param att_embedding_size: positive int, the embedding size of each attention head
:param att_head_num: positive int, the number of attention head
:param dnn_hidden_units: list,list of positive integer or empty list, the layer number and units in each layer of deep net
:param dnn_activation: Activation function to use in deep net
:param dnn_dropout: float in [0,1), the probability we will drop out a given DNN coordinate.
:param dnn_use_bn: bool. Whether use BatchNormalization before activation or not in deep net
:param l2_reg_dnn: float. L2 regularizer strength applied to DNN
:param l2_reg_embedding: float. L2 regularizer strength applied to embedding vector
:param init_std: float,to use as the initialize std of embedding vector
:param seed: integer ,to use as random seed.
:param task: str, ``"binary"`` for binary logloss or ``"regression"`` for regression loss
:return: A Keras model instance.
"""
check_feature_config_dict(feature_dim_dict)
if (att_embedding_size * att_head_num != len(sess_feature_list) * embedding_size):
raise ValueError(
"len(session_feature_lsit) * embedding_size must equal to att_embedding_size * att_head_num ,got %d * %d != %d *%d" % (
len(sess_feature_list), embedding_size, att_embedding_size, att_head_num))
sparse_input, dense_input, user_behavior_input_dict, _, user_sess_length = get_input(feature_dim_dict, sess_feature_list, sess_max_count, sess_len_max)
# 生成User Field和Item Field
sparse_embedding_dict = {feat.name: Embedding(feat.dimension,
embedding_size,
embeddings_initializer=RandomNormal(mean=0.0,
stddev=init_std,
seed=seed),
embeddings_regularizer=l2(l2_reg_embedding),
name='sparse_emb_' + str(i) + '-' + feat.name,
mask_zero=(feat.name in sess_feature_list)) for i, feat in enumerate(feature_dim_dict["sparse"])}
query_emb_list = get_embedding_vec_list(sparse_embedding_dict,
sparse_input,
feature_dim_dict["sparse"],
sess_feature_list,
sess_feature_list)
# concat User Field和Item Field
query_emb = concat_fun(query_emb_list)
deep_input_emb_list = get_embedding_vec_list(sparse_embedding_dict,
sparse_input,
feature_dim_dict["sparse"],
mask_feat_list=sess_feature_list)
deep_input_emb = concat_fun(deep_input_emb_list)
deep_input_emb = Flatten()(NoMask()(deep_input_emb))
# Session Divsion Layer
tr_input = sess_interest_division(sparse_embedding_dict,
user_behavior_input_dict,
feature_dim_dict['sparse'],
sess_feature_list,
sess_max_count,
bias_encoding=bias_encoding)
# Session Interest Extractor Layer
Self_Attention = Transformer(att_embedding_size,
att_head_num,
dropout_rate=0,
use_layer_norm=False,
use_positional_encoding=(not bias_encoding), # bias_encoding=False
seed=seed,
supports_masking=True,
blinding=True)
sess_fea = sess_interest_extractor(tr_input,
sess_max_count,
Self_Attention)
# Session Interest Interacting Layer
lstm_outputs = BiLSTM(len(sess_feature_list) * embedding_size,
layers=2,
res_layers=0,
dropout_rate=0.2, )(sess_fea)
# Session Interest Activating Layer
# 黄色Activation Unit
interest_attention_layer = AttentionSequencePoolingLayer(att_hidden_units=(64, 16),
weight_normalization=True,
supports_masking=False)([query_emb, sess_fea, user_sess_length])
# 蓝色Activation Unit
lstm_attention_layer = AttentionSequencePoolingLayer(att_hidden_units=(64, 16),
weight_normalization=True)([query_emb, lstm_outputs, user_sess_length])
deep_input_emb = Concatenate()([deep_input_emb, Flatten()(interest_attention_layer), Flatten()(lstm_attention_layer)])
# 如果有dense输入,和上面两部分一起concat,输入到DNN中
if len(dense_input) > 0:
deep_input_emb = Concatenate()(
[deep_input_emb] + list(dense_input.values()))
output = DNN(dnn_hidden_units,
dnn_activation,
l2_reg_dnn,
dnn_dropout,
dnn_use_bn,
seed)(deep_input_emb)
output = Dense(1, use_bias=False, activation=None)(output)
output = PredictionLayer(task)(output)
sess_input_list = []
# sess_input_length_list = []
for i in range(sess_max_count):
sess_name = "sess_" + str(i)
sess_input_list.extend(get_inputs_list([user_behavior_input_dict[sess_name]]))
# sess_input_length_list.append(user_behavior_length_dict[sess_name])
model_input_list = get_inputs_list([sparse_input, dense_input]) + sess_input_list + [user_sess_length]
model = Model(inputs=model_input_list, outputs=output)
return model
def get_input(feature_dim_dict, seq_feature_list, sess_max_count, seq_max_len):
sparse_input, dense_input = create_singlefeat_inputdict(feature_dim_dict)
user_behavior_input = {}
for idx in range(sess_max_count):
sess_input = OrderedDict()
for i, feat in enumerate(seq_feature_list):
sess_input[feat] = Input(
shape=(seq_max_len,), name='seq_' + str(idx) + str(i) + '-' + feat)
user_behavior_input["sess_" + str(idx)] = sess_input
user_behavior_length = {"sess_" + str(idx): Input(shape=(1,), name='seq_length' + str(idx)) for idx in
range(sess_max_count)}
user_sess_length = Input(shape=(1,), name='sess_length')
return sparse_input, dense_input, user_behavior_input, user_behavior_length, user_sess_length
def sess_interest_division(sparse_embedding_dict, user_behavior_input_dict, sparse_fg_list, sess_feture_list,
sess_max_count,
bias_encoding=True):
tr_input = []
for i in range(sess_max_count):
sess_name = "sess_" + str(i)
keys_emb_list = get_embedding_vec_list(sparse_embedding_dict,
user_behavior_input_dict[sess_name],
sparse_fg_list,
sess_feture_list,
sess_feture_list)
# [sparse_embedding_dict[feat](user_behavior_input_dict[sess_name][feat]) for feat in
# sess_feture_list]
keys_emb = concat_fun(keys_emb_list)
tr_input.append(keys_emb)
if bias_encoding:
tr_input = BiasEncoding(sess_max_count)(tr_input)
return tr_input
def sess_interest_extractor(tr_input, sess_max_count, TR):
tr_out = []
for i in range(sess_max_count):
tr_out.append(TR(
[tr_input[i], tr_input[i]]))
sess_fea = concat_fun(tr_out, axis=1)
return sess_fea
- 更新时间:2019-07-31