Patents_groupby机制
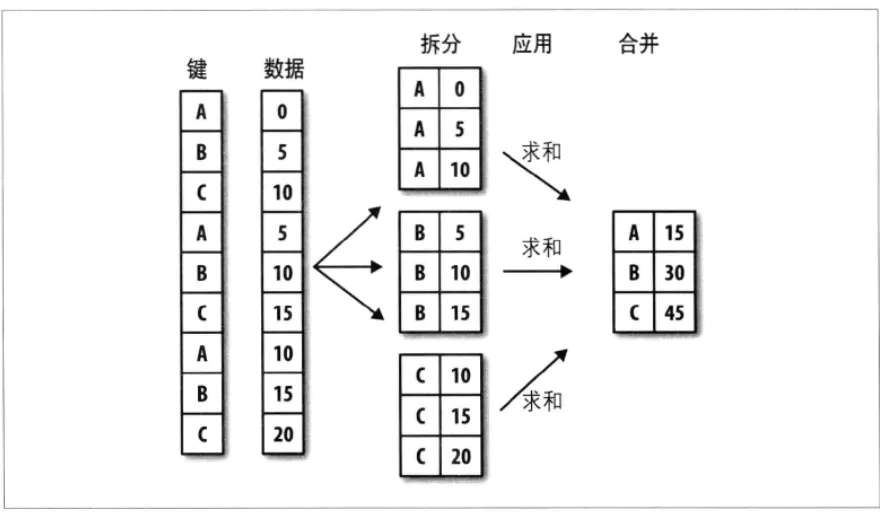
1.使用列名分组
df = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],
'key2':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
group_1=df.groupby(['key1','key2'])
print(group_1.sum())
'''
#由于key2中并不是数值,自动过滤了
data1 data2
key1 key2
a one 0.120658 1.776958
two 0.708023 -0.334745
b one 0.336527 -0.118483
two -1.195948 -1.084212
'''
#只需要统计一列,[['data1']]是为了返回DataDataFrame格式
group_2=df.groupby('key1')[['data1']]
print(group_2.sum())
'''
data1
key1
a -3.510479
b 0.327874
'''
#禁用分组键作为索引
group_1=df.groupby('key1',as_index=False)
print(group_1.mean())
'''
key1 data1 data2
0 a 0.215868 0.887776
1 b -0.013590 -2.059145
'''2.使用字典分组
people=pd.DataFrame(np.random.randn(25).reshape(5,5),columns=['a','b','c','d','e']
,index=['Joe','Steve','Wes','Jim','Travis'])
#添加几个NA值
people.loc[2:3,['b','c']]=np.nan
mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'}
by_column=people.groupby(mapping,axis=1)
print(by_column.sum())
'''
blue red
Joe -0.504558 2.111179
Steve -1.658838 0.130956
Wes 1.004845 1.742293
Jim -2.551048 -1.502194
Travis 1.854355 0.171491
'''3.使用Series分组
people=pd.DataFrame(np.random.randn(25).reshape(5,5),columns=['a','b','c','d','e']
,index=['Joe','Steve','Wes','Jim','Travis'])
map_series=pd.Series(list('abaab'),index=['a','b','c','d','e'])
by_column=people.groupby(map_series,axis=1)
print(by_column.count())
'''
a b
Joe 3 2
Steve 3 2
Wes 3 2
Jim 3 2
Travis 3 2
'''4.使用函数分组
#不得不说pandas强大....
people=pd.DataFrame(np.random.randn(25).reshape(5,5),columns=['a','b','c','d','e']
,index=['Joe','Steve','Wes','Jim','Travis'])
map_series=pd.Series(list('abaab'),index=['a','b','c','d','e'])
print(by_column.min())
'''
a b c d e
J -1.005321 -0.718634 0.949499 0.121992 0.281395
S -0.331975 0.387535 -0.024841 -1.244947 0.228626
T -1.627892 -0.190549 2.365620 -1.013034 -0.907791
W 0.685558 0.569147 -0.485205 1.094103 -2.196524
'''5.层级分组
'''
level:层次索引的层级。从0开始分别对应第一层等索引,默认为-1,则代表最里面一层索引。
'''
people=pd.DataFrame(np.random.randn(25).reshape(5,5),columns=[['Joe','Steve','Wes','Jim','Travis'],['boy','boy','girl','girl','boy']]
,index=['Joe','Steve','Wes','Jim','Travis'])
people.columns.names=['name','sex']
print(people.groupby(level='sex',axis=1).min())
'''
sex boy girl
Joe 0.720471 0.097515
Steve -0.811630 0.263458
Wes -1.879113 -0.775714
Jim -1.631855 -0.945603
Travis -1.221499 -1.234002
'''6.遍历
'''
groupby支持迭代,生成的是元组序列
'''
df = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],
'key2':['one', 'two', 'one', 'two', 'one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
for i,n in df.groupby('key1'):
print(i)
print(n)
'''
a
key1 key2 data1 data2
0 a one -0.462239 2.618347
1 a two -0.546438 1.615818
4 a one 1.117225 -1.525680
b
key1 key2 data1 data2
2 b one 1.565555 0.813002
3 b two -0.803730 1.082145
'''
pieces=dict(list(df.groupby('key1')))
print(pieces['a'])
'''
key1 key2 data1 data2
0 a one -0.579428 -0.870761
1 a two 0.378817 -0.913764
4 a one 0.546169 0.290938
'''7.聚合
7.1优化的groupby方法
count:分组中非nan的个数
sum:非nan的累和
mean:非nan的均值
std,var:标准差与方差
min,max:非nan的最小值与最大值
prod:非nan的乘积
first,last:非nan的第一个值和最后一个值7.2逐列与多函数应用
def PeakToPeak(arr):
return arr.max() - arr.min()
#数据集:https://github.com/kojoidrissa/pydata-book
tips = pd.read_csv('tips.csv')
tips['tip_pct'] = tips['tip'] / tips['total_bill']
grouped = tips.groupby(['sex','smoker'])
grouped_pct = grouped['tip_pct'].agg(['mean','std',PeakToPeak])
print(grouped_pct)
'''
mean std PeakToPeak
sex smoker
Female No 0.156921 0.036421 0.195876
Yes 0.182150 0.071595 0.360233
Male No 0.160669 0.041849 0.220186
Yes 0.152771 0.090588 0.674707
'''
'''
计算多个列
'''
grouped_pct = grouped['tip_pct','total_bill'].agg(['mean','std','count'])
print(grouped_pct)
'''
tip_pct total_bill
mean std count mean std count
sex smoker
Female No 0.156921 0.036421 54 18.105185 7.286455 54
Yes 0.182150 0.071595 33 17.977879 9.189751 33
Male No 0.160669 0.041849 97 19.791237 8.726566 97
Yes 0.152771 0.090588 60 22.284500 9.911845 60
'''