Apache DolphinScheduler 使用常见问题总结(持续更新中)
DolphinScheduler 使用常见问题总结
- 说明
- 使用注意事项
- 安装包与安装目录
- 日志查看目录
- 开发环境常见问题
- API启动端口是8080不是12345
- 找不到mysql驱动
- worker 执行失败报NPE空指针
- 调度部署常见问题
- ubuntu 部署报错 source: not found
- 访问API服务报错404
- 调度使用常见问题
- 系统初始化登录失败
- 监控页面Master Worker 页面一直都在努力加载中或者查询无数据
- 工作流手动运行成功,但是任务实例页面没有数据
- 任务实例状态为提交成功,但一直不运行
- 文件上传失败
- SQL查询成功,任务实例结果却失败
- SQL插入数据任务执行失败
- load or availablePhysicalMemorySize(G) is too high
- zookeeper监控状态异常
- 创建租户失败
- Master和Worker异常停止
- Data truncation: Data too long for column 'app_link' at row 1
说明
文章中常见问题是在使用过程中发现的,如果文章没有你遇到的问题,请到github上提交issue。
官网地址
github issue地址
使用注意事项
安装包与安装目录
安装包:是下载的的源文件,只有在安装时候才会用到,相安装好调度可以删除该目录。
安装目录:运行install.sh后调度安装的目录,对调度管理都在安装目录下操作,比如 启停服务,、配置、查看日志等等。
官网文档中的描述如下(配置在install.sh中),**记住**任何操作都在安装目录下操作。
#将DS安装到哪个目录,如: /opt/soft/dolphinscheduler,不同于现在的目录
installPath="/opt/soft/dolphinscheduler"
日志查看目录
假设安装调度时候安装配置为 installPath="/opt/soft/dolphinscheduler",那么日志目录就在
/opt/soft/dolphinscheduler/logs 下
查看worker 日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-worker.log
查看master日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-master.log
查看api 日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-api-server.log
查看告警alert日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-alert.log
查看日志服务logger日志
tail -f /opt/soft/dolphinscheduler/logs/dolphinscheduler-logger-server-huaweiyun.out
huaweiyun为hostname,自行修改成你本地的
开发环境常见问题
API启动端口是8080不是12345
在初始化环境中api默认配置12345,
解决办法
编辑运行配置,增加如下配置
-Dserver-api-server -Dspring.profiles.active=api

找不到mysql驱动
由于DolphinScheduler 默认使用的postgresql,默认没有引入mysql驱动依赖。需要手动修改pom。
解决办法:
找到根目录下pom.xml的
mysql
mysql-connector-java
${mysql.connector.version}
test
去掉 < scope>test< /scope> 就ok
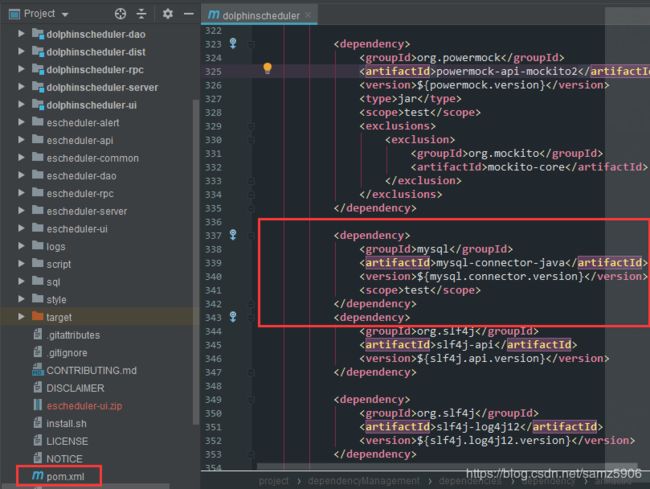
重新 import maven依赖。
worker 执行失败报NPE空指针
解决办法:
在WorkServer vm options 添加如下参数
-Dspring.profiles.active=worker -Dlogging.config=“dolphinscheduler-server/src/main/resources/logback-worker.xml”

调度部署常见问题
ubuntu 部署报错 source: not found

解决办法
可以百度google 关键词 ubuntu source: not found 里面有解决方案
访问API服务报错404

解决办法
上面请求少了工程名称,完整地址是 http://ip:12345/dolphinscheduler/
API默认端口12235
调度使用常见问题
系统初始化登录失败
一般这个错就是密码记错了,调度初始密码如下,注意拷贝不要有空格
账号: admin
密码: dolphinscheduler123
监控页面Master Worker 页面一直都在努力加载中或者查询无数据
通过命令jps,能看到WorkerServer和MasterServer进程。有可能的原因zk挂掉了。
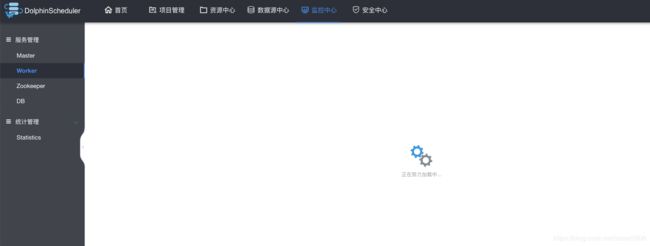
解决办法
查看zk是否启动。如果没有启动就把zk服务启动好。再监控页面看看Master Worker 状态
工作流手动运行成功,但是任务实例页面没有数据
这个问题因素比较多,先假设 zk,worker master 都启动成功情况下
通过查看worker日志,发现有日志 load or availablePhysicalMemorySize(G) is too high,问题同后面的问题load or availablePhysicalMemorySize(G) is too high。解决办法参考该问题。
任务实例状态为提交成功,但一直不运行
这个问题因素比较多,先分析当前情况就是在worker日志文件dolphinscheduler-worker.log 中一直打印如下日志consume tasks: [],there still have 1 tasks need to be executed,任务数没有减少。这种情况可能是任务关联的Worker分组配置的ip和Worker服务ip不一致。导致任务不能执行。
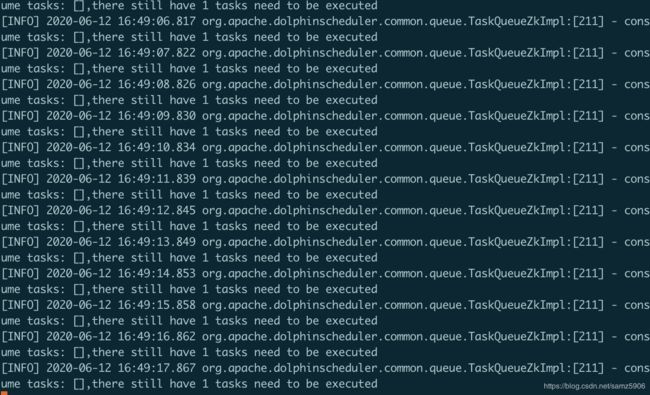
解决办法:
进入安全中心->Worker分支管理,修改分组IP,与Worker服务的ip一致。

文件上传失败
假设前提文件存储服务都已配置好,上传出现如下问题Nginx:413 Request Entity Too Large。原因是Nginx上传文件限制。
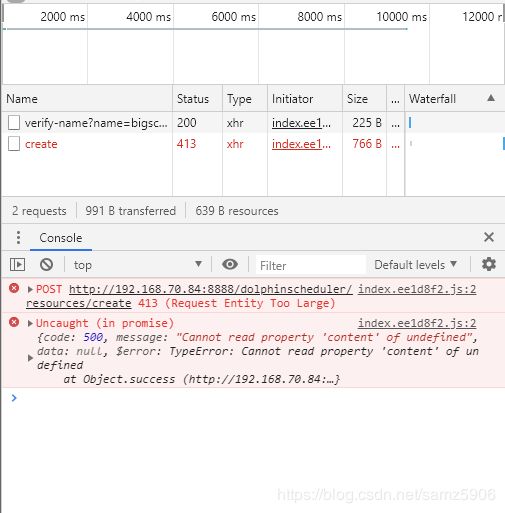
解决办法:
修改/etc/nginx/nginx.conf.增加上传文件大小限制,在 http{} 段中增大nginx上传文件大小限制
client_max_body_size 200M
重启ngnix
ps:如果说明不详细,可以百度谷歌关键词 413 nginx
SQL查询成功,任务实例结果却失败
失败日志如下,原因是SQL查询会将结果将通过邮件发送,日志报错是没有配置邮件服务

解决办法
配置邮件服务配置文件为conf/alert.properties
配置样例如下,163邮箱配置
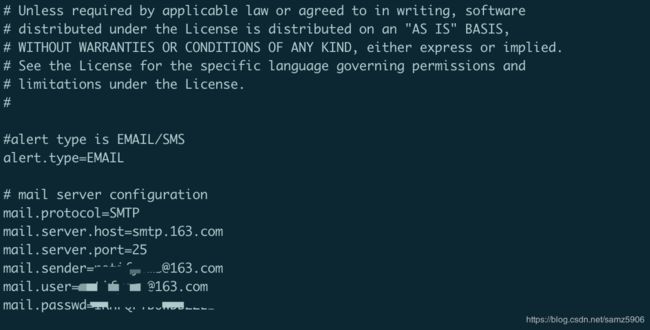
邮箱详情配置可以参考这篇
SQL插入数据任务执行失败
[ERROR] 2020-06-05 10:20:07.756 - [taskAppId=TASK-9-493-494]:[336] - Can not issue data manipulation statements with executeQuery().
java.sql.SQLException: Can not issue data manipulation statements with executeQuery().
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:1084)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:987)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:973)
at com.mysql.jdbc.SQLError.createSQLException(SQLError.java:918)
at com.mysql.jdbc.StatementImpl.checkForDml(StatementImpl.java:501)
at com.mysql.jdbc.PreparedStatement.executeQuery(PreparedStatement.java:2150)
at org.apache.dolphinscheduler.server.worker.task.sql.SqlTask.executeFuncAndSql(SqlTask.java:295)
at org.apache.dolphinscheduler.server.worker.task.sql.SqlTask.handle(SqlTask.java:176)
at org.apache.dolphinscheduler.server.worker.runner.TaskScheduleThread.run(TaskScheduleThread.java:142)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
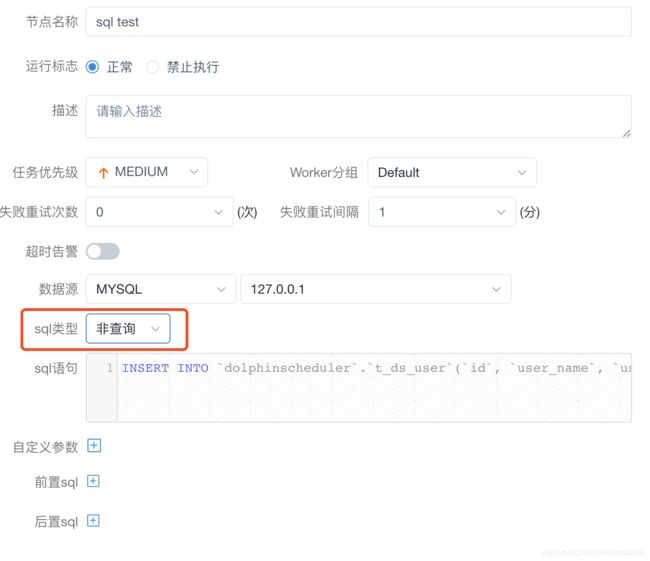
解决办法:
报错原因是sql类型为查询执行非查询的事情, 解决办法是更新任务,将sql类型改为非查询
load or availablePhysicalMemorySize(G) is too high
worker后台日志一直出现如下日志,原因服务器内存或者CPU已经不够用(由于调度启动默认堆大小为1G,如果5个服务全部启动,就要消耗5G内存)。这是worker的自我保护机制,不会接新的任务,等现在的任务运行完或CPU、内存富余的时候再继续接新任务
![]()
解决办法
1 如果是有其他程序正在执行(消耗内存大),可以等待其他任务执行完成,再观察worker是否还有容量不够日志。
2 如果是土豪,就直接扩容内存
3 如果物理机内存不没有5G,有下面两种处理方式
- 可以先关闭一些服务,比如直接kill alert,logger等。
- 可以调整启动参数,修改配置文件 bin/dolphinscheduler-daemon.sh,修改-Xms 值改小点
export DOLPHINSCHEDULER_OPTS="-server -Xmx16g -Xms1g -Xss512k -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70"
源码参考
zookeeper监控状态异常
zk启动正常,Master Worker 启动正常。但是zk 节点自检状态异常,这是由于获取zk的FourLetterWord失败

解决办法
首先执行命令,localhost是服务地址
echo ruok|nc localhost 2181
如果出现如下提示,就需要修改配置zoo.cfg配置
ruok is not executed because it is not in the whitelist.
增加如下配置在zoo.cfg中
4lw.commands.whitelist=*
重启zk
如果没有nc命令需要先安装yum install nc
源码参考
创建租户失败
创建租户需要使用HDF,一般错误都发生操作HDFS时候。
可能的错误有没有配置hdfs、hdfs操作没权限等。
比如下面是没权限提示

解决办法
遇到这问题是先看api日志,根据日志错误提示做出修改,
反正是首先要确保你的HDFS已经配置好。(目前主流是hdfs类型,其他类型还没尝试)
ps: hdfs配置文件修改参考这个issue
Master和Worker异常停止
原因
Master和Worker要上报心跳给zookeeper,如果在指定时间内没有上报心跳,Master和Worker机会自动停止
就会出现如下日志
[INFO] 2020-04-30 06:48:28.032 org.apache.dolphinscheduler.server.master.MasterServer:[180] - master server is stopping ..., cause : i was judged to death, release resources and stop myself
[INFO] 2020-04-30 06:48:29.425 org.apache.dolphinscheduler.server.master.runner.MasterSchedulerThread:[143] - master server stopped...
[INFO] 2020-04-30 06:48:31.033 org.apache.dolphinscheduler.server.master.MasterServer:[197] - heartbeat service stopped
所以如果zookeeper失联(挂了),Master和Worker也就挂了。
解决办法
1 确保zookeeper服务能正常访问
2 可以修改zookeeper超时配置
在1.2版本中超时是300ms。可以改大点
配置文件为 conf/zookeeper.properties,根据实际情况自行修改
参考issue
Data truncation: Data too long for column ‘app_link’ at row 1
原因是app_link 字段太长了
解决办法
1) 1.3版本之前 t_ds_task_instance.app_link长度255。可以修改字段长度,官方脚本
ALTER TABLE t_ds_task_instance ALTER COLUMN app_link type text
2) 可以升级最新版本,已经解决改问题,
参考issue