首先来学习用下TermQuery,这是最简单的一个Query实现,即查询索引文档中是否包含了指定的Term,Lucene官方API注释里是这样说的:
public class TermQuery
extends Query
A Query that matches documents containing a term. This may be combined with other terms with a BooleanQuery.
那什么又是Term呢?还是看看官方给的解释吧
public final class Term
extends Object
implements Comparable
A Term represents a word from text. This is the unit of search. It is composed of two elements, the text of the word, as a string, and the name of the field that the text occurred in. Note that terms may represent more than words from text fields, but also things like dates, email addresses, urls, etc.
一个Term表示着一个来自文本中的一个单词(因为老外眼里只有单词,没有中文,在中文里word可以理解为一个词语),它是一个搜索单元,它有两部分组成,单词文本和域的名称,后面着重提醒了我们,term不仅仅是文本中单词,还可以是日期,email地址,url链接等等。一句话,Term就是分词过后的一个个词组。
使用的时候new TermQuery(Term term)即可,Term对象的构造器有两个参数,fieldName和fieldValue,如:
new Term("title","Java");即表示在title域里查询包含Java的,示例代码如下:
Query query = new TermQuery(new Term(fieldName,queryString));
当然你也可以通过QueryParser类来创建我们的Query对象,如:
QueryParser parser = new QueryParser(fieldName, new AnsjAnalyzer());
Query query = parser.parse(queryString);但两者还是有点小小区别的,QueryParser会经过分词器,会使用分词器把我们的queryString(用户输入的查询关键字)进行分词,我们都知道分词器一般都会先把文本先全部转成小写然后去掉停用词等等一系列操作,而TermQuery则不会,而是直接根据用户提供的fieldValue去分词后的Term里查找的,我们知道分词后索引里存储的Term的value肯定都是小写的,如果我们提供的fieldVlue是大写的,肯定是查询不到的,这是大家比较容易忽略的,举个例子吧,比如你的文本里包含了“I服了U”这个网络词汇的,默认肯定是不会把它当成一个词语,如果使用了ansj分词器并把这个词语配置到自定义词典里,如:
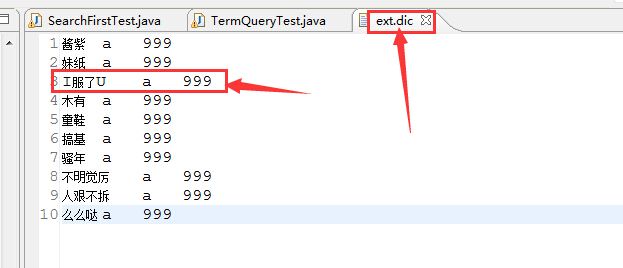
那么分词后我们索引里的term中存储的应该是i服了u,而不是I服了U,所以如果你们使用I服了U作为搜索关键字来搜索,是搜不到任何结果的,这时你就蒙圈了,我不是已经配置了自定义词典了吗?为什么找不到?为了避免你们犯这种错误,特此提醒,TermQuery不会对你提供的fieldValue做任何处理,而QueryParser会,这也是为什么QueryParser构建的时候需要用户提供Analyzer对象而TermQuery不需要的原因。
TermQuery使用起来很简单,使用时候该注意的问题我也说过了,就说这么多,打完收工!希望对你们学习Lucene有所帮助。
如果你还有什么问题请加我Q-Q:7-3-6-0-3-1-3-0-5,
或者加裙![]() 一起交流学习!
一起交流学习!