ELF文件格式与动态链接/静态链接与动态库/静态库 (Linux下 可执行文件的格式)
ELF文件格式
在Linux下,可执行文件/动态库文件/目标文件(可重定向文件)都是同一种文件格式,我们把它称之为ELF文件格式。
虽然它们三个都是ELF文件格式但都各有不同:
可执行文件没有section header table 。
目标文件没有program header table。
动态库文件俩个 header table 都有,因为链接器在链接的时候需要section header table 来查看目标文件各个 section 的信息然后对各个目标文件进行链接,而加载器在加载可执行程序的时候需要program header table ,它需要根据这个表把相应的段加载到相应的虚拟内存(虚拟地址空间)中。
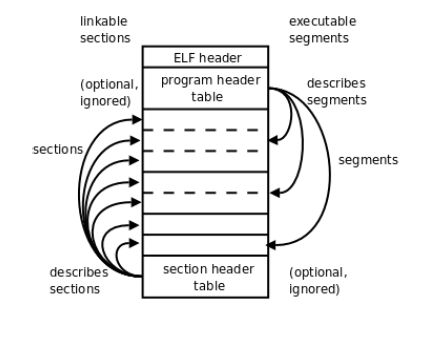
这个图中俩个header表的位置在实际中不一定这么放,只是为了好看这么画的。
目标文件的ELF格式组成
max.s 文件下述讨论的列子
.section .data
data_items: #These are the data items
.long 3,67,34,222,45,75,54,34,44,33,22,11,66,0
.section .text
.globl _start
_start:
movl $0, %edi # move 0 into the index register
movl data_items(,%edi,4), %eax # load the first byte of
data
movl %eax, %ebx # since this is the first item,
%eax is
# the biggest
start_loop: # start loop
cmpl $0, %eax # check to see if we've hit the
end
je loop_exit
incl %edi # load next value
movl data_items(,%edi,4), %eax
cmpl %ebx, %eax # compare values
jle start_loop
movl %eax, %ebx # move the value as the largest
jmp start_loop # jump to loop beginning
loop_exit:
movl $1, %eax #1 is the _exit() syscall
int $0x80
找一个最大值,把它当中main函数的返回值1.ELF header
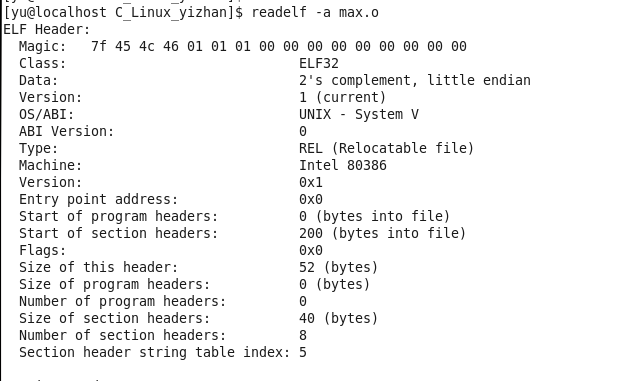
从上面我们可以看到该ELF文件的大概属性,是什么操作系统,还有是什么处理器架构。从 start of section headers 可以看出section 头表在目标文件的起始地址,从 size of section headers 可以看出来目标文件中每一个section的大小,接着这个字段的下面的字段说了该目标文件共有多少 section。再接着的字段说了,section header table 在目标文件的相对位置。
program headers 地址为0,说明没有那么表明这个ELF文件是个 .o文件。
2.section header table
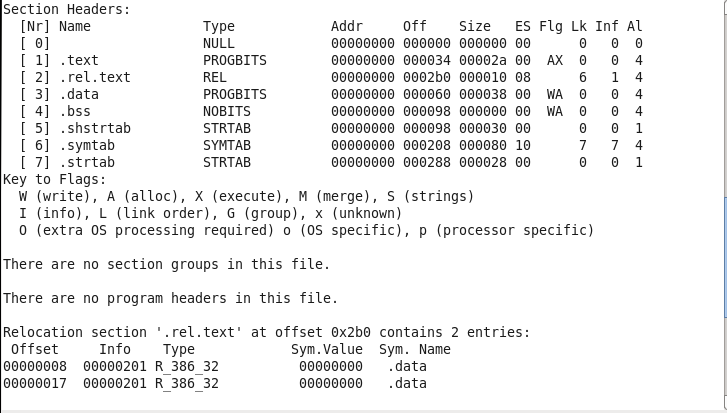
这个是 section header table ,里面详细说明了各个节的信息。我们可以看到 data , text这俩个节都是在汇编中已经有的,其他的6个节都是汇编器加的。addr那一列表明了这些节在虚拟地址空间的位置全为0,没问题因为现在还没被链接,off/size 表明了相应节在ELF文件(.o) 中的位置和长度(大小)。data段 大小 0x38, 没问题的在汇编文件中定义了14个全局变量,刚好56字节对应0x38.
bss 段大小为0,也没问题的,bss段记录未初始化的全局变量,我们没有定义。
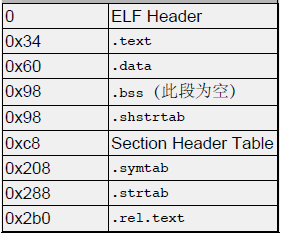
根据ELF Header 的信息可以画出各个节在ELF文件布局。上面显示了节头表中共有8个 section Header , 每个section Header 记录了相应 section 对应的信息 , 与每个节之后被加载到内存中的所对应的权限。
3.strtab/shstrtab
接下来用hexdump把目标文件的内容打印出来。


对照着上面的图,可以看到0x98 shstrtab(section header str table) 对应的内容都是每个section 名字的ASCII码形式。
strtab 对应文件地址的0x288中,这个表中保存的是我们 .c 文件中全局变量/函数/源文件的名字。
4.rel.text / symtab
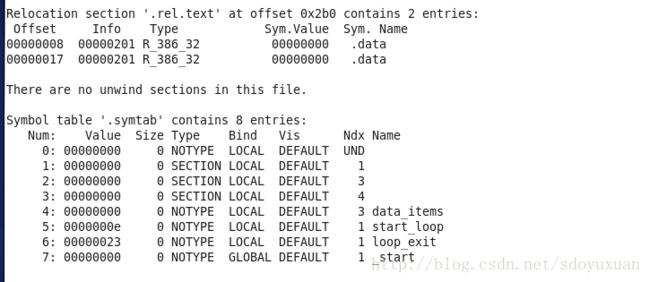
rel.text
ret.text 节记录了该目标文件中,有那些位置需要链接器进行重定向。
symbol table
符号表中记录了,每一个全局符号(即源文件中的函数名/全局变量名)所处于那个section。并且显示出了每一个符号的bind 绑定属性,这个属性在链接器链接的时候有用,local属性的符号立马进行解析绑定,而GLOBAL的却不会。直到遇到一个强状态的GLOBAL属性的符号才会进行绑定,具体是否是强状态,看该全局变量是否是已初始化过的。
可执行文件的ELF格式
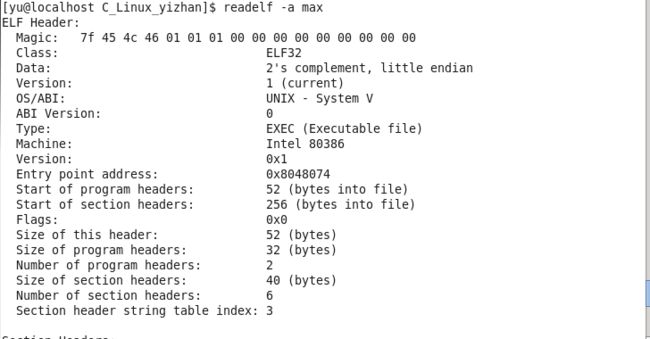
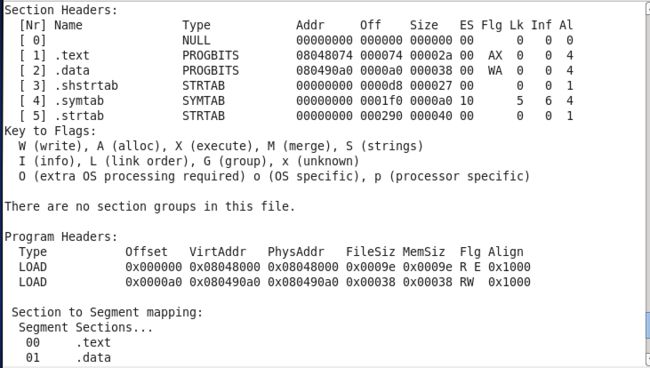
把上面的 max.o 文件进行链接生成一个可执行程序后,我们再用readelf 读取它的信息如上图所示。
多了俩个 program headers ,少了俩个 section header。
少了俩个节头,那俩个一个是bss一个是rel.text , rel.text 在链接的时候被使用完就丢弃了, bss 没使用也被丢弃了。
多了俩个 program headers ,如上每一个program Header记录一个数据段,共俩个在这个列子中。一个数据段从 0x08048000 开始 , 属性只读/可执行/对齐数4k。另一个大家自己看。
根据上面的信息我画出来了 可执行文件的格式图
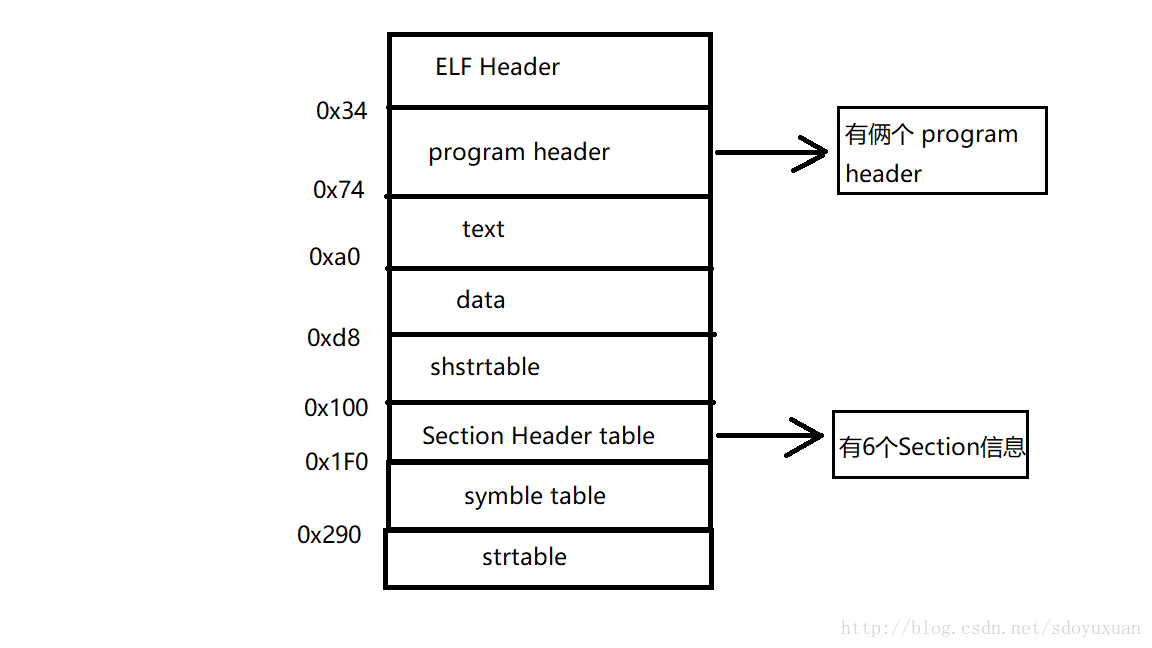
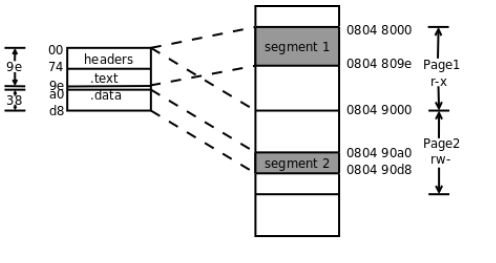
最后加载器根据, program Header 中的信息,把相应段加载到了虚拟地址空间对应的物理内存中。在目标文件和可执行文件中,可以看出来目标文件中所有的符号地址在链接的过程中都被替换成了确切的虚拟地址。
总结下各个Header 的意义
Section Header table :保存了各个 Section Header的描述信息,在目标文件/可执行文件的所述位置与权限信息。
text :记录了目标文件/可执行文件的代码(二进制指令)
data :记录了目标文件/可执行文件的全局变量的数据
shstrtable : 记录了所有Section的名字(以文本方式记录)
strtable : 记录了全局变量/函数的名字/源文件的名字(以文本形式)
symbol table : 记录了各个全局符号(变量名/函数名)所属那个Section.
rel.text.table :记录了链接时需要的重定向信息(即把相应的代码/数据链接到何处.
bss : 记录了所属bss段的大小,并没有记录真实的数据。(bss段为未初始化全局变量的数据段)
ELF Header : 记录了 ELF文件的一些属性信息。
program Header table : 记录了 program Header 的信息。
program Header :记录了把那些Section合并成了同一个 Segment,它被用于加载器,加载到内存时使用。
所有的 Section 的Header都被记录到了 Section Header table 中。(Section 与SectionHeader 俩个东西)
段中的虚拟地址
加载首先分为三种方式,第一种绝对加载,第二种可重定位加载,第三种动态运行时加载。
第一种方式,提供给加载器的可执行文件的所有地址都是物理地址,这种方式很多缺点,首先程序员得知道分配到那个物理地址处,其次一个地方修改,所有地方都要修改。
第二种方式,可执行文件中的地址都是从0开始的,当被加载到物理内存中,对起每个地址 加上起始物理内存的地址即可。缺点不方便换入换出,无法使用虚拟内存。
第三种方式,动态运行时加载,即所有内存都写成虚拟地址,当确切的要访问那个虚拟地址的时候,由MMU和页表对其解释成真正的物理地址,方便换入换出,可见在我的Linux下使用的是,动态运行时加载。(换入/换出指的是 页面置换,这个是虚存机制,为了能使同一时间执行更多的进程,加入的一个概念,把阻塞态的进程的内存页中的信息写到硬盘上,然后等需要加载时,再加载到内存中,在linux中 swap区就是用来页面置换的)
静态链接
静态链接就是,在链接阶段,让链接编辑器把目标文件所用到的函数/符号在静态库文件中找到相应的 .o 文件进行链接。(链接器一般都是先找是否有 相应名的动态库文件,没有才链接 静态库文件的这点需要注意)
静态库文件其实就是对一堆 . o 文件的一种打包。
生成静态库指令
ar -rc libxxx.a xxx.o xxx.o
使用静态库文件
gcc -l xxx -L ./ -I xxx.h main.c -o a.out -static
-l(小写L) 指定库名字 -L 指定库路径 -I 指定头文件
动态链接
动态链接,就是在运行的时候,当使用到动态库中的函数了,由运行时链接器把相应的动态库加载到地址空间的共享区中。在链接阶段,可执行文件并不链接动态库的内容。
gcc -shared -fPIC *.c -o XXXlib.so 生成动态库文件(使用gcc 直接使源文件编译生成elf格式的动态库文件)
gcc -lxxx -L ./ -I XXX.h -o a.out 使用动态库文件我们用ldd 指令去模拟运行可执行程序,会发现动态库 not found,那是因为动态库链接器找不到相应的动态库。动态链接器的搜索路径:
1. 首先去 环境 变量LD_LIBRARY_PATH 中查找
2. 然后没有去,/etc/ld.so.cache 动态链接器的缓存中文件查找,这个文件是由 /etc/ld.so.conf生成。如果我们要给动态链接器的配置文件加路径,直接把路径写到文件后, 再 ldconfig -v 即可。
3. 如果还没有,去/usr/lib 或 /lib 目录下查找,在64位平台下 还有 /usr/lib64 /lib64 这俩个目录。我们可以直接把动态库添加到这个目录
动态链接的过程(动态链接器)
首先第一次加载动态库的时候,jmp 指令会跳到该相应的符号段,由于动态库相应的文件没被加载到内存中,所以就执行了一个动态链接器的函数,最终由动态链接器把相应的动态库加载进来。以后再对动态库的函数调用时,就不再次加载了,jmp 指令后的地址处中所保存的函数地址就是刚被加载到内存中的函数地址。。(上面说的jmp 指令后的地址处所包含的地址意思是,jmp * 0xXXXXXXXX 这个是间接跳转,跳转的目标地址是后面这个地址空间中所保存的函数地址,0xXXXXXXXX就可以看出一个函数指针变量的地址,而它存储的内容那个函数地址正是我们想要执行的函数。其实在这里动态连接器调用了 dlopen 函数来加载的动态库)
in _dl_runtime_resolve () from /lib/ld-linux.so.2
就是进入了这个函数,大家可以自己测试下,我写的这个博客图片太多了,不想再放图片了dlopen 动态链接
用dlopen 函数就不用在使用前面所讲的,什么 LD_LIBRARY_PATH 啊什么的了。
1 #include使用 dlopen 的时候,编译的时候需要加 -ldl 选项。
动态链接/静态链接优缺点
优点
动态链接优点:
1.不占可执行文件大小,在内存中只有一份实例,多个进程可共享一个动态库,节省内存。
2.便于升级,如果需要升级动态库模块时,可执行文件不需改变,直接升级动态库文件即可。
静态链接优点
1.可移植性好,如果把可执行文件放到其他电脑上,不用再需要动态库文件了。
2.运行的时候不用再把相应的库文件链接到内存,效率高。
缺点
动态库
1.移植性不好,如果其他电脑上运行可执行程序,没有动态库的话,会发生 not found ,导致程序无法正常运行。并且它是运行时加载,效率可能会慢些。
静态库
1.由于在链接的时候,被链接编辑器和目标文件一起链接成可执行程序,结果就是造成可执行程序过大,并且如果在内存中有多个相同的可执行程序,那么静态库文件在内存中也存在多个实例,浪费空间。(因为多个相同的静态库文件的代码段被加载到了内存)
2. 不便于升级,因为需要重新链接可执行程序。
链接期
链接期,主要做了符号解析与符号重定向。
我们使用gcc链接程序的时候是有依赖关系的,链接器对于未解析的符号会保留先来,然后把当前 .o 文件丢弃,继续往后遍历去解析其他 .o 文件,如果找到了响应的符号,会对之前未解析的符号进行符号解析与绑定地址。
基于这个原理,所以链接的时候文件与文件之间也是有依赖关系的。
test.cc
void test()
{
}
main.cc
int main()
{
test();
}
gcc test.o main.o -o a.out
会包 未定义 test 函数就像上面的列子,所以基础的 .o 文件在链接的时候应该往前面放。
动态链接/静态链接图
链接加载图 可参考 操作系统 精神与设计原理 第七章的图
上面的例子,取自于 Linux c 一站式编程中的ELF文件和动态/静态链接。
参考
深入理解操作系统 第三版
操作系统精髓与设计原理 第八版
Linux C 一站式编程