detection proposals综述(What makes for effective detection proposals?)
本文地址:http://blog.csdn.net/shanglianlm/article/details/46786303
1 介绍(INTRODUCTION)
本文主要对最近的 proposal 检测方法做一个总结和评价。主要是下面这些方法。

2 Detection Proposal 方法(DETECTION PROPOSAL METHODS)
作者将 Detection Proposal 分为两类,grouping method (将图片分为碎片,最后聚合)和 window scoring method (对分成的大量窗口打分)。
2.1 分组 proposal 方法(Grouping proposal methods)
Grouping proposal methods尝试产生对应于目标的多个区域(可能重叠)。根据它们产生 proposal 的方式可以划分为三类:superpixels (SP),graph cut (GC) 和 edge contours (EC)。
• SelectiveSearch (SP) [15], [29]:通过贪婪地合并超像素来产生 proposals。这个方法没有学习的参数,合并超像素的特征和相似函数是手动设定的。它被 R-CNN 和 Fast R-CNN detectors [8], [16] 等最新的目标检测方法选用。
• RandomizedPrim’s (SP) [26]:使用类似与SelectiveSearch 的特征,但是使用了一个随机的超像素合并过程来学习所有的可能(probabilities)。此外,速度有了极大地提升。
• Rantalankila (SP) [27]:使用类似与SelectiveSearch 的策略,但使用了不同的特征。在后续阶段,产生的区域用作求解图切割的种子点(seeds )(类似于CPMC)。
• Chang (SP) [38]:结合 saliency 和 Objectness 在一个图模型中来合并超像素实现前景/背景(figure/background)分割。
• CPMC (GC) [13],[19]:避免初始的分割,使用几个不同的种子点(seeds )和位元(unaries )对像素直接进行图切割。生成的区域使用一个大的特征池来排序。
• Endres (GC) [14], [21]:从遮挡的边界建立一个分层(hierarchical )的分割,并且使用不同的种子点和参数来切割图产生区域。产生的 使用大量的线索和鼓励多样性的角度排序。
• Rigor (GC) [28]:是 CPMC 的一个改进,使用多个图切割和快速的边缘检测子来加快计算速度。
• Geodesic (EC) [22]:首先使用 [36] 对图片过分割。分类器用来为一个测地距离变换标定种子点。每个距离转换的水平集(Level sets)定义了(figure/ground)的分割。
• MCG (EC) [23]:基于 [36], 提出一个快速的用于计算多尺度(multi-scale)层次分割进程。使用边缘强度来合并区域,生成的目标假设(object hypotheses )使用类似于尺度,位置,形状和边缘强度的线索来排序。
2.2 窗口评分的 proposal 方法(Window scoring proposal methods)
Window scoring proposal methods 通过对每个候选的窗口根据它们包含目标的概率来打分来产生 proposals 。与 grouping approaches 比,这些方法值返回边界框(bounding boxes),因此速度更快。但是,除非它们的窗口采样密度很高,否则这些方法位置精度很低。
• Objectness [12], [24]:最为最早和最广泛的一种 proposal 方法。它通过选择一副图片中的显著性位置作为 proposal,接着通过颜色,边缘,位置,尺寸,和 superpixel straddling 等多个线索对这些 proposal 打分。
• Rahtu [25]:以 一个包含采样区域(单个,两个和三个超像素)和 多个随机采样的框的大的 proposal 池作为开始。采用类似于 Objectness 的打分策略,但是有些提高 ([40]添加了额外的 low-level features 和 强调了恰当调优的非最大抑制(properly tuned nonmaximum suppression)的重要性)。
• Bing† [18]:通过边缘训练一个简单的线性分类器,并且以一个滑动窗口的方式运行。使用充足的近似,获得一个非常快的类未知的检测子 (CUP中每帧 1ms)。CrackingBing [41]表明一个有很小影响和类似性能的分类器可以通过不用查看图片的方式来获得 (分类性能不是来自于学习而是几何学)。
• EdgeBoxes† EC [20] :基于目标边界估计(通过 structured decision forests [36], [42]获得)形成一个粗糙的滑动窗口模式作为开始,使用一个后续的 refinement 步骤来提高位置精度。不学习参数。作者提出通过调节滑动窗口模式的密度和和非最大抑制的阈值来调优方法用于不同的重叠阈值。
• Feng [43] :通过搜索显著性图片内容来找到 proposal ,提出了一种新的显著性度量,包括一个潜在的目标能被图片的剩余部分组成。它采用滑动窗口模式,并通过显著性线索对每个位置打分。
• Zhang [44] :提出在简单的梯度特征上训练一个级联的排序 SVMs。第一阶段对不同的尺度和长宽比(aspect ratio)训练不同的分类器;第二阶段对所有获得的proposals 排序。所有的 SVMs 使用结构性的输出,对含有更多目标重叠的窗口打分更高。因为级联在同样的类别上训练和测试,因此不太清楚它的泛化能力。
• RandomizedSeeds [45] :使用多个随机的 SEED 超像素映射图 对每个候选窗口打分。打分策略类似于 Objectness 的 superpixel straddling (没有额外添加的信息)。作者展示使用多个超像素映射(superpixel maps )可以明显地提高召回率。
2.3 其他 proposal 方法(Alternative proposal methods)
• ShapeSharing [47] :是一个无参的数据驱动的方法,通过匹配边转换目标形状从范例(exemplars)到测试图片。生成的区域使用图切割合并和提纯。
• Multibox [9], [48] :训练一个神经网络来直接回归一定数量的 proposals (不需要在图片上滑动网络)。每个 proposals 都有它自己的位置误差 。该方法在 ImageNet 表现出最好的结果。
2.4 Proposals VS 级联(Proposals versus cascades)
Proposals:使用图像特征产生候选窗口;
级联(cascades):使用一个快速但是不太精确的分类器抛弃大量不太好的 proposals 。
两者之间的主要差异是级联(cascades)要求在训练过程中一般化对象类别。
proposal 一般化对象类别的原因:1)一个主要的假设是对于足够大量的类别训练一个分类器对于一般化未知的类别是充足的(训练猫和狗后,可以一般化到其他动物)。2)分类器的判别能力经常是受限的,因此阻止分类器过拟合和学习所有目标共享的属性。
2.5 控制proposals的数量(Controlling the number of proposals)
Ranging from just a few ( ∼ 102 ) to a large number ( ∼ 105 )
3 Proposals 可重复性(PROPOSAL REPEATABILITY)
在检测 proposals(detection proposals)而不是所有滑动窗口上训练一个检测器修改了所有正负窗口的外观分布(appearance distribution)。本部分我们主要分析负窗口的分布( the distribution of negative windows):如果 proposal 不能一致地对包含部分或不含目标的相似图片产生窗口,分类器就不能对测试集中的负窗口进行评分(if the proposal method does not consistently propose windows on similar image content without objects or with partial objects, the classifier may have difficulty generating scores on negative windows on the test set)。一个极端的例子是训练数据集中只包含目标,而测试集中包含目标和负窗口,这样训练获得的分类器将不能区分目标和背景,因此在测试阶段会对负窗口给出无用的评分。因此,我们希望 proposals在背景上的一致性的外观分布
与检测器相关。
我们将 proposals 的这种对类似图片内容标定的属性为 proposals 方法的 repeatability 。直观上来说,proposals 应该对包含相同内容的有轻微差别的图片 repeatable 。
3.1 可重复性评估协议(Evaluation protocol for repeatability)
For matching we use the intersection over union (IoU) criterion。
Given the matching, we plot the recall for every IoU threshold and define the repeatability to be the area under this “recall versus IoU threshold” curve between IoU 0 and 1。
3.2 可重复性实验和结果(Repeatability experiments and results)

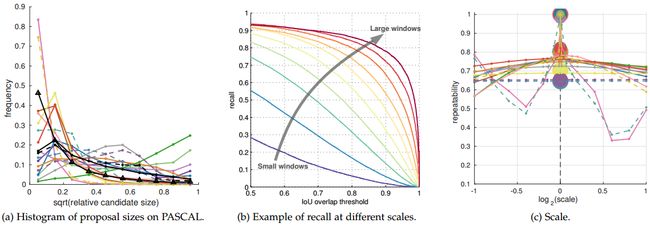
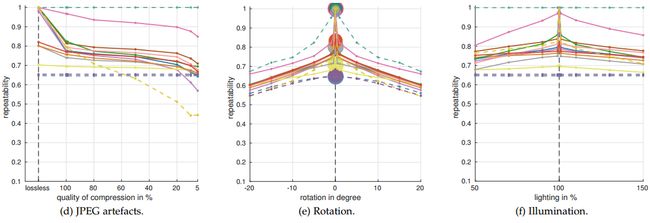
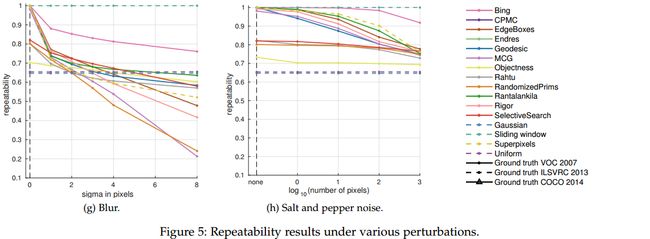
Small changes to an image cause noticeable differences in the set of detection proposals for all methods except Bing. The higher repeatability of Bing is explained by its sliding window pattern, which has been designed to cover almost all possible annotations with IoU = 0.5 (see also Cracking Bing [41]).
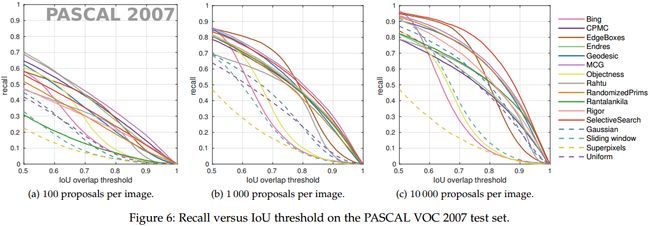
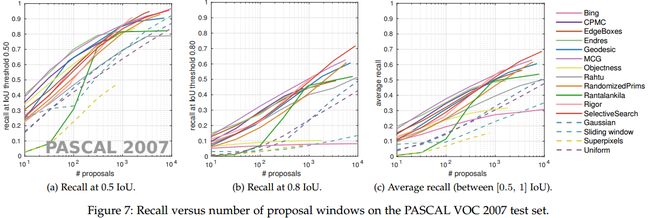
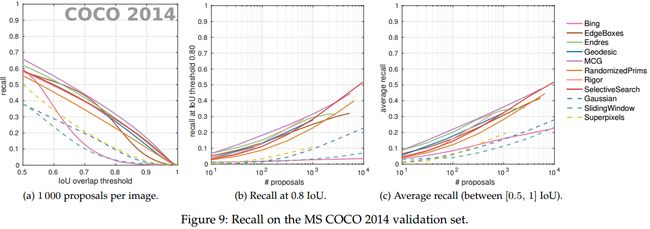
4 Proposals召回(PROPOSAL RECALL)
当使用 proposals 的检测方法时测试图片中的兴趣目标要求有一个好的覆盖,因为缺失的目标在后续分类阶段不能被恢复。因此通常使用召回率来评价 proposals 的质量。
4.1 召回评价协议(Evaluation protocol for recall)
4.2 召回结果(Recall results)

参考及延伸阅读材料
[9] C. Szegedy, S. Reed, D. Erhan, and D. Anguelov, “Scalable, highquality object detection,” arXiv:1412.1441, 2014.
[12] B. Alexe, T. Deselaers, and V. Ferrari, “What is an object?” in CVPR, 2010.
[13] J. Carreira and C. Sminchisescu, “Constrained parametric min-cuts for automatic object segmentation,” in CVPR, 2010.
[14] I. Endres and D. Hoiem, “Category independent object proposals,” in ECCV, 2010.
[15] K. van de Sande, J. Uijlings, T. Gevers, and A. Smeulders, “Segmentation as selective search for object recognition,” in ICCV, 2011.
[18] M.-M. Cheng, Z. Zhang, W.-Y. Lin, and P. H. S. Torr, “BING: Binarized normed gradients for objectness estimation at 300fps,” in CVPR, 2014.
[19] J. Carreira and C. Sminchisescu, “Cpmc: Automatic object segmentation using constrained parametric min-cuts.” PAMI, 2012.
[20] C. Zitnick and P. Dollár, “Edge boxes: Locating object proposals from edges,” in ECCV, 2014.
[21] I. Endres and D. Hoiem, “Category-independent object proposals with diverse ranking,” in PAMI, 2014.
[22] P. Krähenbühl and V. Koltun, “Geodesic object proposals,” in ECCV, 2014.
[23] P. Arbelaez, J. Pont-Tuset, J. Barron, F. Marqués, and J. Malik, “Multiscale combinatorial grouping,” in CVPR, 2014.
[24] B. Alexe, T. Deselares, and V. Ferrari, “Measuring the objectness of image windows,” PAMI, 2012.
[25] E. Rahtu, J. Kannala, and M. Blaschko, “Learning a category independent object detection cascade,” in ICCV, 2011.
[26] S. Manén, M. Guillaumin, and L. Van Gool, “Prime object proposals with randomized prim’s algorithm,” in ICCV, 2013.
[27] P. Rantalankila, J. Kannala, and E. Rahtu, “Generating object segmentation proposals using global and local search,” in CVPR, 2014.
[28] A. Humayun, F. Li, and J. M. Rehg, “Rigor: Recycling inference in graph cuts for generating object regions,” in CVPR, 2014.
[29] J. Uijlings, K. van de Sande, T. Gevers, and A. Smeulders, “Selective search for object recognition,” IJCV, 2013.
[36] P. Dollár and C. L. Zitnick, “Fast edge detection using structured forests,” PAMI, 2015.
[38] K.-Y. Chang, T.-L. Liu, H.-T. Chen, and S.-H. Lai, “Fusing generic objectness and visual saliency for salient object detection,” in ICCV, 2011.
[39] J. Lim, C. L. Zitnick, and P. Dollár, “Sketch tokens: A learned midlevel representation for contour and object detection,” in CVPR, 2013.
[40] M. Blaschko, J. Kannala, and E. Rahtu, “Non Maximal Suppression in Cascaded Ranking Models,” in Scandanavian Conference on Image Analysis, 2013.
[41] Q. Zhao, Z. Liu, and B. Yin, “Cracking BING and beyond,” in BMVC, 2014.
[42] P. Dollár and C. L. Zitnick, “Structured forests for fast edge detection,” in ICCV, 2013.
[43] J. Feng, Y. Wei, L. Tao, C. Zhang, and J. Sun, “Salient object detection by composition,” in ICCV, 2011.
[44] Z. Zhang, J. Warrell, and P. H. S. Torr, “Proposal generation for object detection using cascaded ranking svms,” in CVPR, 2011.
[45] M. Van Den Bergh, G. Roig, X. Boix, S. Manen, and L. Van Gool,“Online video seeds for temporal window objectness,” in ICCV, 2013.
[46] M. Van den Bergh, X. Boix, G. Roig, and L. Van Gool, “Seeds: Superpixels extracted via energy-driven sampling,” IJCV, 2014.
[47] J. Kim and K. Grauman, “Shape Sharing for Object Segmentation,” in ECCV, 2012.
[48] D. Erhan, C. Szegedy, A. Toshev, and D. Anguelov, “Scalable object detection using deep neural networks,” in CVPR, 2014.