自然语言处理(NLP):19 金融领域NLP竞赛——文本语义相似度
智能客服的本质,就是充分理解用户的意图,在知识体系中精准地找到与之相匹配的内容,回答用户问题或提供解决方案。问题相似度计算,是贯穿智能客服离线、在线和运营等几乎所有环节最核心的技术,广泛应用于搜索、推荐、对话等领域。
作者:走在前方
博客:https://wenjie.blog.csdn.net/
技术交流群: 访问博客首页,加入 “NLP技术交流群” ,祝共同进步。
主要涉及的内容
- 文本相似度任务介绍
- 背景
- NLP文本相似度应用场景(智能客服、知识图谱问答等。。。)
- 文本相似度解决方案
- 基准方法
- 词移距离
- Smooth Inverse Frequency
- 预训练编码器方法
- 基于bert 文本相似度
- 文本相似度模型
- 数据预处理
- 数据可视化
- 模型训练
其实我们应该认真学习每个NLP项目比赛,会给我们提供很多思路和解决方案,然后把这些思路应用到实际的工作中,同时也可以拓展自己的知识面。
语义相似度任务介绍
语义相似度是 NLP 领域很重要的一个任务,有非常大的应用价值。目前它常用于:
- 通过标注数据找寻新的相似未标注数据,从而扩充训练集
- 智能客服,计算客户提出的问题与知识库中问题的相似度
国内类似的几个比赛
- Kaggle Quora
- 天池 CIKM
- 蚂蚁金服
这种业务非常明确,就是给定一个句子q1和另一个句子q2,系统自动判断这两个句子的含义:
- 相同(label=1)
- 不同(label=0)
NLP文本相似度背景
智能客服的本质,就是充分理解用户的意图,在知识体系中精准地找到与之相匹配的内容,回答用户问题或提供解决方案。问题相似度计算,是贯穿智能客服离线、在线和运营等几乎所有环节最核心的技术,同时也是自然语言理解中最核心的问题之一,广泛应用于搜索、推荐、对话等领域。在问题相似度计算上的突破,能够促进整个 NLP 领域的蓬勃发展,推动通用人工智能的大跨步前进,给人类社会带来巨大的经济价值。
文本相似度任务描述
问题相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。
示例:
- “花呗如何还款” --“花呗怎么还款”:同义问句
- “花呗如何还款” – “我怎么还我的花被呢”:同义问句
- “花呗分期后逾期了如何还款”-- “花呗分期后逾期了哪里还款”:非同义问句
对于例子 a,比较简单的方法就可以判定同义;
对于例子 b,包含了错别字、同义词、词序变换等问题,两个句子乍一看并不类似,想正确判断比较有挑战;
对于例子 c,两句话很类似,仅仅有一处细微的差别 “如何”和“哪里”,就导致语义不一致。
数据均来自金融大脑的实际应用场景:
数据集中每一行就是一条样例。格式如下:
行号\t 句 1\t 句 2\t 标注,举例:1 花呗如何还款 花呗怎么还款 1
• 行号指当前问题对在训练集中的第几行;
• 句1和句2分别表示问题句对的两个句子;
• 标注指当前问题对的同义或不同义标注,同义为1,不同义为0。
语义相似度解决方案
2018年蚂蚁金服金融大脑赛题分享: https://github.com/ziweipolaris/atec2018-nlp
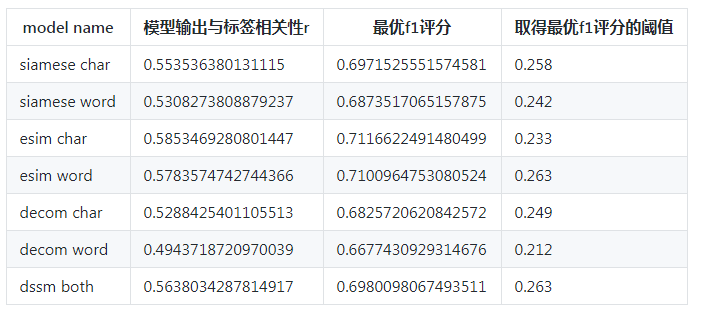
四种计算文本相似度的方法对比
代码可以参考:https://github.com/nlptown/nlp-notebooks/blob/master/Simple%20Sentence%20Similarity.ipynb
用于计算两句子间语义相似度的方法非常广泛,下面是常见的几种方法。
基准方法
估计两句子间语义相似度最简单的方法就是求句子中所有单词词嵌入的平均值,然后计算两句子词嵌入之间的余弦相似性。
词移距离
替代上述基准方法的其中一种有趣方法就是词移距离(Word Mover’s Distance)。词移距离使用两文本间的词嵌入,测量其中一文本中的单词在语义空间中移动到另一文本单词所需要的最短距离。
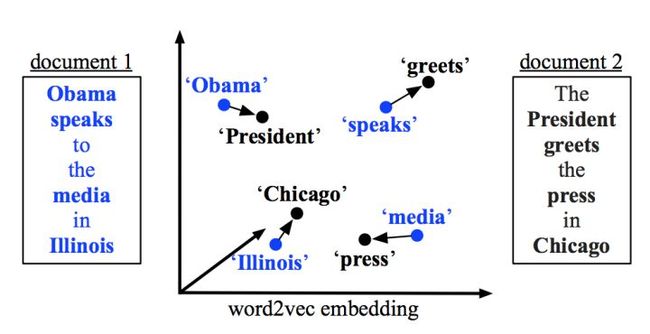
Smooth Inverse Frequency
从语义上来讲,求一句话中词嵌入的平均值似乎给与不相关的单词太多权重了。而Smooth Inverse Frequency试着用两种方法解决这一问题:
加权:就像上文用的TF-IDF,SIF取句中词嵌入的平均权重。每个词嵌入都由a/(a + p(w))进行加权,其中a的值经常被设置为0.01,而p(w)是词语在语料中预计出现的频率。常见元素删除:接下来,SIF计算了句子的嵌入中最重要的元素。然后它减去这些句子嵌入中的主要成分。这就可以删除与频率和句法有关的变量,他们和语义的联系不大。最后,SIF使一些不重要的词语的权重下降,例如but、just等,同时保留对语义贡献较大的信息。
预训练编码器
上述两种方法都有两个重要的特征。
- 作为简单的词袋方法,它们并不考虑单词的顺序。
- 它们使用的词嵌入是在一种无监督方法中学习到的。
前面方法存在的问题,由于不同的词语顺序会有不同的意思(例如“the dog bites the man”和“the man bites the dog”),我们想让句子的嵌入对这一变化有所反馈。另外,监督训练可以更直接地帮助句子嵌入学习到句意。
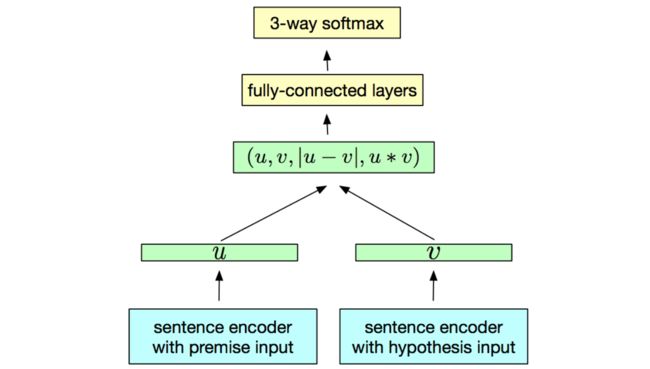
InferSent是由Facebook研发的预训练编码器,它是一个拥有最大池化的BiLSTM,在SNLI数据集上训练,该数据集含有57万英语句子对,所有句子都属于三个类别的其中一种:推导关系、矛盾关系、中立关系。
提供一种提示路(至于为什么是这样,大家只能效果进行尝试了)
句子1: 专为一个向量u
句子2: 转为一个向量v
最后把四个向量进行凭借,然后通过fc进行logits ,并通过softmax 获取每个标签类型的概率。如果大家了解BERT 两个句子相似度问题,发现BERT 之直接u和v里两个变量直接凭接一起。
用BERT做语义相似度匹配任务
这一类问题属于Sentence Pair Classification Task.
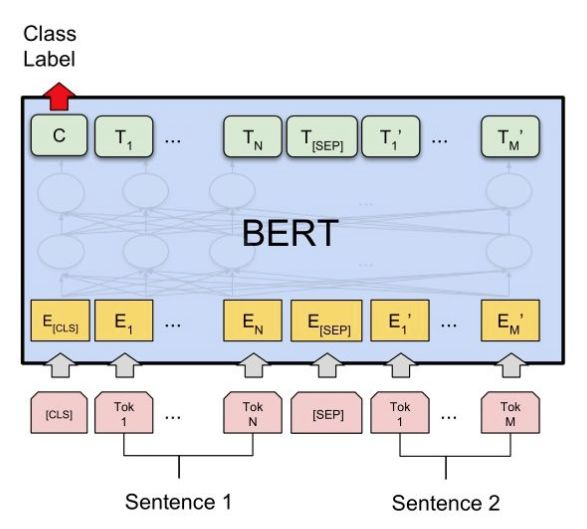
上图中,我们将输入送入BERT前,在首部加入[CLS],在两个句子之间加入[SEP]作为分隔。然后,取到BERT的输出(句子对的embedding),取[CLS]即可完成多分类任务/相似度计算任务。
数据预处理
- 原始预料数据

统一输入数据标准
- id: 表示句子唯一标识
- text_a:句子1
- text_b:句子2
- label:句子1和句子是否相关 (0-不同;1-相同)
| 0 我用花呗交的优拜押金 我***月***用花呗支付的小蓝单车押金 0 1 花呗有漏洞吗 花呗有***天宽限期吗 0 2 花呗可以在淘宝上使用吗 淘宝充红包的金额能和花呗叠加使用吗 0 3 花呗还款了,还显示要还款 我的花呗需要还款 0 4 我的花呗为什么不让用 我的支付宝花呗不能用 0 |
|----| -
- 数据离散化数据
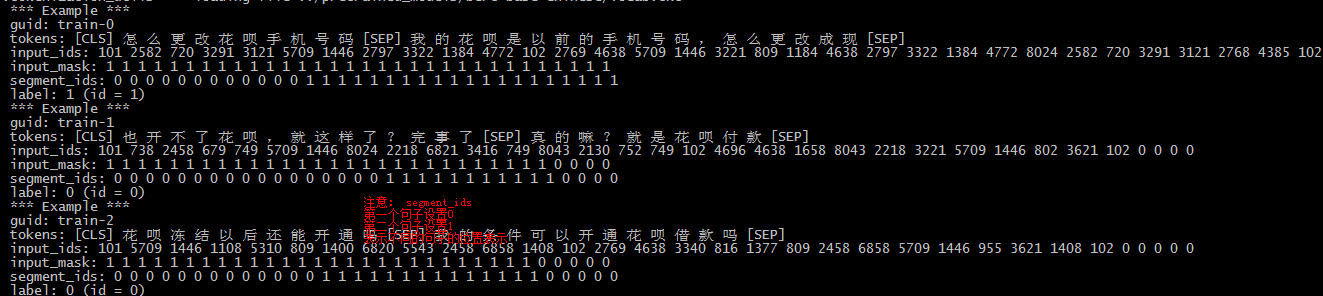
数据可视化分析
- 句子标签数量分布
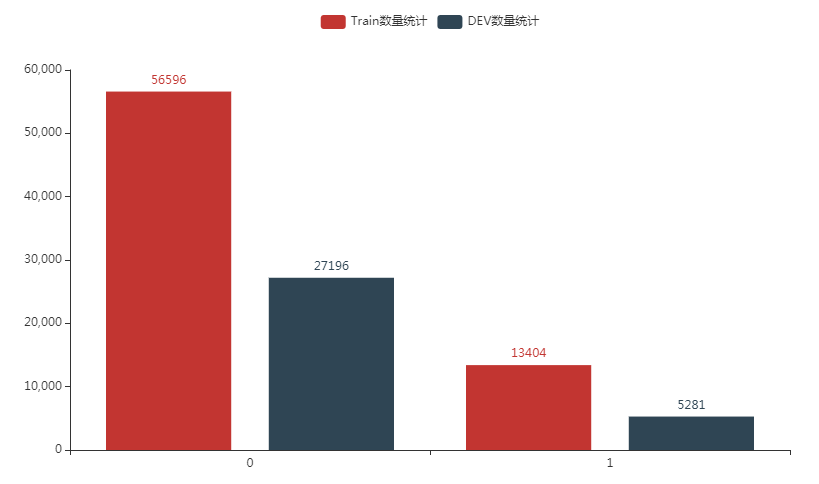
- 句子对长度


模型训练
上述数据处理完成后,后续的训练就非常简单了,直接调用训练方法就可以直接训练了。
python sim_main.py --data_dir ./data/ \
--task_name ATEC \
--num_train_epochs 2 \
--pre_train_model ../pretrained_models/bert-base-chinese \
--max_seq_length 64 \
--do_train \
--train_batch_size 128 \
--eval_batch_size 64 \
--gradient_accumulation_steps 4 \
--output ./ATEC_bert_zh_model/
- data_dir:训练预料数据
- pre_train_model : BERT 中文预训练的模型
- output :训练完成模型保持路径
- max_seq_length:表示bert模型输入句子最大的长度 (通过数据分析获得)
- train_batch_size、eval_batch_size: 批量进行数据的处理
- task_name:表示我们计算任务的名称,对应数据集加载方法
- num_train_epochs 训练的迭代次数
最后我们效果 acc = 0.836407
而针对后续效果进一步的提升就需要从数据下进行 下功夫了(从官方提供的预料数据上看,实际有错误的数据的)。最后我们在验证数据集合上的效果 acc = 0.836407 。 对于样本不均衡问题不建议使用acc 进行评价指标,可以考虑 f1-score. 这里不在进行尝试。我们会在NLPCC项目-知识图谱文本相似度环境进一步实验。
参考资料
[1]nlp竞赛2018
https://www.csdn.net/gather_26/MtTacg4sOTExNS1ibG9n.html#NLPCC_2013_16
[2]蚂蚁金融 NLP 竞赛——文本语义相似度赛题总结
https://zhuanlan.zhihu.com/p/51675979
[3]Top9 竞赛总结-NLP 语义相似度 第三届拍拍贷“魔镜杯”大赛
https://zhuanlan.zhihu.com/p/55610493
[4]ATEC2018 NLP 赛题 复赛 f1 = 0.7327
https://github.com/ziweipolaris/atec2018-nlp
[5]BERT 训练文本相似度
https://github.com/BonnieHuangxin/Bert_sentence_similarity