NumPy基础知识整理(一)
根据利用Python进行数据分析一书整理而成。
NumPy 是 Python 中高性能科学计算和数据分析的基础包。它是本书所介绍的几乎所有高级工具的构建基础。理解 NumPy 有助于理解Pandas。
一、ndarray: 一种多维数组对象
NumPy 最重要的一个特点就是其N维数组对象(ndarray,不产生歧义的情况下也可以称之为数组),该对象是一个快速而灵活的大数据集容器,可以利用这种数组对整块数据执行一些数学运算。
1. 创建 ndarray
# 以下命令均在python命令行中执行
import numpy as np # 约定俗成,请务必遵守
data1 = [1.0,2,3,4] # 简单列表
arr1 = np.array(data1)
data2 = [[1,2,3,4], [5,6,7,8]] # 嵌套列表
arr2 = np.array(data2)
arr2.ndim # 维数
arr2.shape # 形状
arr1.dtype # 数据类型
arr2.dtype
除 np.array 之外,还有一些函数可以创建 ndarray 对象。如下,
np.zeros(10)
np.zeros((2,3)) # 参数是一个元组
np.empty((2,3,2)) # 返回的值不是0,而是一些未初始化的垃圾值
np.ones((2,3))
np.arange(15) # 创建数组,是Python内置函数range()的数组版
下图列出了一些数组创建函数。

2. ndarray的数据类型
dtype(数据类型)是一个特殊的对象,它含有 ndarray 将一块内存解释为特定数据类型所需的信息。
arr1 = np.array([1,2,3], dtype=np.float64)
arr2 = np.array([1,2,3], dtype=np.int32)
arr1.dtype # 64代表64位(8字节),其他同理
arr2.dtype
# 可以通过 ndarray 的 astype 方法显示第转换dtype
arr = np.array([1,2,3,4,5])
arr.dtype # dtype('int64')
float_arr = arr.astype(np.float64)
float_arr.type # dtype('float64')
arr = np.array([1.0, 2.1, 3.1])
arr
arr.astype(np.int32) # 小数部分被舍去
# 如果某字符串数组表示的全是数字,也可以用astype将其转换为数值形式
numeric_strings = np.array(['1.25','2.50','10'], dtype=np.string_)
numeric_strings
numeric_strings.astype(np.float64) # 如果转换过程因为某种原因失败了,就会引发一个TypeError
# dtype 还有另外一个用法
int_arr = np.arange(5)
test_arr = np.array([.22, .270, .357], dtype=np.float64)
int_arr.astype(test_arr.dtype)
# 注意:调用astype无论如何都会创建出一个新的数组,即使新dtype跟老dtype相同也是如此
# 警告:浮点数(比如float64和float32)只能表示近似的分数值。在复杂斤算中,由于可能会积累一些浮点错误,因此比较曹祖只能在一定小数位内有效。
3. 数组与标量的计算
数组很重要,它使你不用编写循环即可对数据进行批量运算。这通常叫做矢量化。大小相等的数组之间的任何算数运算都会将运算应用到元素级。
arr = np.array([[1., 2., 3.],[4., 5., 6.]])
arr
arr * arr
arr + arr
1 / arr
arr ** 0.5
# 不同大小的数组之间的运算叫做广播(broadcasting)
4. 基本的索引和切片
Numpy数组的索引是一个内容丰富的主题,因为选取数据自己或单个元素的方式有很多。从表面上看,他跟Python列表的功能差不多。
arr = np.arange(10)
arr # array([0,1,2,3,4,5,6,7,8,9])
arr[5] # 5
arr[5:8] # array([5,6,7])
arr[5:8] = 12
arr # array([0,1,2,3,4,12,12,12,8,9])
# 跟列表最重要的区别在于,数组切片是原始数组的视图,这意味数据不会被复制,视图上的任何修改都会直接反映到源数组上
arr_slice = arr[5:8]
arr_slice[0] = 12345
arr # array([0,1,2,3,4,12345,12,12,8,9])
arr_slice[:] = 64
arr # array([0,1,2,3,4,64,64,64,8,9])
# 解释:因为NumPy的设计目的是处理大数据,如果NumPy坚持要将数据复制来复制去的话会产生何等的性能和内存问题。
# 注意:如果你想得到的是ndarray切片的一份副本而非视图,就要显示地进行复制操作,例如:arr[5:8].copy()
对于高维度数组,我们能做更多事情。在一个二维数组中,各索引位置的元素不再是标量而是一维数组。
arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2d[2] # array([7,8,9])
arr2d[0][2] # 3
arr2d[0, 2] # 3
arr2d[:2]
arr2d[:2, 1:] # array([[2,3],[5,6]])
arr2d[1, :2]
arr2d[2, 1:]
arr2d[:, 1:]
arr2d[:, 1:] = 0
arr2d
# 更高维度
arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
arr3d[0]
old_arr3d = arr3d[0].copy()
arr3d[0] = 42
arr3d
arr3d[0] = old_arr3d
arr3d
arr3d[0,1] # array([4,5,6])
arr3d[1,0] $ array([7,8,9])
下图说明了二维数组的索引方式。
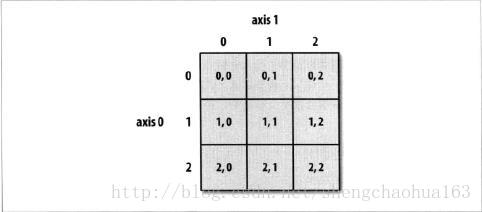
下图说明了二维数组的切片方式。

5. 布尔型索引
例子如下:
names = np.array(['Bob', 'Ben', 'Joe', 'Bob'])
data = np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])
names == 'Bob' # array([True,False,False,True])
data[names = 'Bob'] # array([[1,2,3],[10,11,12]]) # 此处布尔型数组的长度必须和索引的轴长度一致
data[names = 'Bob', 1:]
data[names = 'Bob', 2]
names != 'Bob' # array([False,True,True,False])
data[-(names = 'Bob')] # 用负号表示对条件进行否定
mask = (names == 'Bob') | (names == 'Joe') # 多个布尔条件,使用&,|等运算符即可
mask
data[mask]
# 通过布尔型数组设置值一种经常用到的手段。为了将data中的负值都设置为0。
data = np.array([[-1,-2], [1,2],[3,4],[5,6]])
data[data < 0] = 0
data
data[names != 'Joe'] = 7
data
6. 花式索引
花式索引(Fancy indexing)是一个NumPy术语,它指的是利用整数数组进行索引。假设我们有一个8*4数组:
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
arr
arr[[4,3,0,6]] # 以特定顺序选取子集,只需传入一个用于指定顺序的整数列表或ndarray即可
arr[[-3,-5,-7]] # 反向选取
arr = np.arange(32).reshape((8,4))
arr
arr[[1,5,7,2], [0,3,1,2]] # array([4,23,29,20]) 返回4个元素
arr[[1,5,7,2]][:,[0,3,1,2]] # 返回矩形区域的元素
arr[np.ix_([1,5,7,2],[0,3,1,2])] # np.ix_()函数,后面会讲到
# 注意:花式索引跟切片不一样,它总是将数据复制到新数组中
6. 数组转置和轴对换
转置(transpose)是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)。数组不仅有transpose方法,还有一个特殊的T属性。
arr = np.arange(15).reshape((3,5))
arr
arr.T # 进行轴对换
arr = np.random.randn(6,3)
arr
np.dot(arr.T, arr) # 矩阵乘法
# 高维数组的转置 transpose方法需要得到一个由轴编号组成的元组才能对这些轴进行转置
arr = np.arange(16).reshape((2,2,4))
arr
arr.transpose((1,0,2)) # 比较费脑子
arr
二. 通用函数:快速的元素级数组函数
通用函数(ufunc)是一种对ndarray中的数据执行元素级运算的函数。你可以将其看作简单函数(接收一个或多个标量值,并产生一个或多个标量值)的矢量化包装器。例如:
arr = np.arange(10)
# 一元ufunc
np.sqrt(arr)
np.exp(arr)
# 二元ufunc
x = np.random.randn(5)
y = np.random.randn(5)
x
y
np.maximum(x, y) # 取二者元素的最大值
一元ufunc和二元ufunc如下表:

