『数据挖掘十大算法 』笔记二:SVM-支持向量机
- 数据挖掘Top 10算法
- 支持向量机
- 线性可分支持向量机
- 函数间隔和几何间隔
- 间隔最大化
- 间隔最大化算法
- 支持向量和间隔边界
- 学习的对偶算法
- 线性可分支持向量机学习算法
- 线性支持向量机和软间隔最大化
- 线性支持向量机学习算法
- 非线性支持向量机和核函数
- 核技巧
- 非线性分类问题
- 核函数定义
- 核技巧在支持向量机中的应用
- 正定核
- 常用核函数
- 非线性支持向量机学习算法
- 核技巧
- 附录
- 算法分类
- 参考资料
- 相似算法
数据挖掘Top 10算法
C4.5, k-Means, SVM, Apriori, EM, PageRank, AdaBoost, kNN, Naive Bayes, and CART
支持向量机
支持向量机,英文为Support Vector Machine,是一种分类模型,属于监督式学习的方法,它的基本模型是定义在特征空间上的间隔最大的线性分类器,这一点是和感知机不同的地方(感知机基于误分类的损失函数,利用梯度下降法获得损失函数极小化的超平面)。
支持向量机利用核函数将输入从输入空间映射到特征空间,在特征空间里建立有一个最大间隔超平面。
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。
核函数表示将输入从输入空间映射到特征空间得到特征向量之间内积。通过核函数可以学习非线性支持向量机,等价于隐式地在高维的特征空间学习线性支持向量机。
线性可分支持向量机
既然线性可分,学习的目标为在特征空间中找到一个分离超平面,能够将实例分到不同的类。
给定线性可分训练数据集,通过间隔最大化求解相应的凸二次规划问题学习得到分离超平面为
相应的分类决策函数为
即为线性可分支持向量机。
间隔最大化相应的间隔分为函数间隔和几何间隔。
函数间隔和几何间隔
函数间隔:对于给定的训练数据集T和超平面(w,b),定义超平面(w,b)关于样本点 (xi,yi) 的函数间隔为
当超平面并未改变,只是成比例改变w和b的时候,函数间隔也会发生变化,如变成2w和2b,超平面未变函数间隔却变成了2倍,所以需要对法向量w加一些约束,如规范化,||w||=1,是的间隔确定,变成了几何间隔。
函数间隔:对于给定的训练数据集T和超平面(w,b),定义超平面(w,b)关于样本点 (xi,yi) 的几何间隔为
定义超平面(w,b)关于训练数据集T的函数间隔为超平面(w,b)关于T中所有样本点 (xi,yi) 的几何间隔最小值,即
超平面(w,b)关于样本点 (xi,yi) 的几何间隔一般是实例点到超平面的带符号距离,样本点被超平面正确分类时就是实例点到超平面的距离。
间隔最大化
将问题表示为下面约束最优化问题:
约束条件表示超平面(w,b)关于每个样本点 (xi,yi) 的几何间隔至少是 Υ
等价于下面约束最优化问题:
函数间隔取值并不影响最优化问题的解,所以取 Υ=1^ ,将其带入最优化问题,而最大化 1||w|| 和最小化 12||w||2 等价,于是转化为一个凸二次规划问题:
间隔最大化算法
输入:线性可分数据集 T={(x1,y1),(x2,y2),···,(xN,yN)} ,其中, xi∈χ=Rn,yi∈γ={−1,+1}, i=1,2,···,N ;
输出:最大间隔超平面和分类决策函数;
构造并求解约束最优化问题:
minw,b12||w||2s.t. yi(w∗xi+b)−1≥0, i=1,2,···,N求得最优解 w∗,b∗
由此得到超平面:
w∗∗x+b∗=0分类决策函数:
f(x)=sign(ω∗+b)
支持向量和间隔边界
线性可分的情况下,训练数据集的样本点与分离超平面距离最近的样本点的实例称为支持向量(support vector),支持向量是使得约束条件等号成立的点,即
如图, H1,H2 就是支持向量。
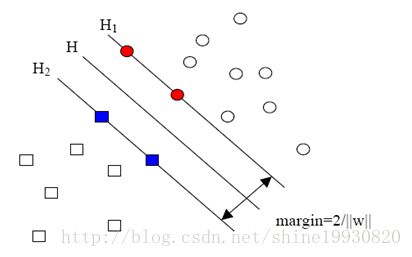
支持向量在确定分离超平面中起着决定性作用,所以这种分类模型称为支持向量机。
学习的对偶算法
应用拉格朗日对偶性,通过求解对偶问题得到原始问题的最优解,就是线性可分支持向量机的对偶算法,有点在于:
- 对偶问题更容易求解。
- 方便引入核函数,进而推广到非线性问题求解。
定义拉格朗日函数:
原始问题的对偶问题是极大极小问题:
首先求 minw,bL(w,b,α) :
将拉格朗日函数对 w,b 求偏导数并令其等于零,获得极值点。
∇wL(w,b,α)=w−∑i=1Nαiyixi=01.19∇bl(w,b,α)=∑i=1Nαiyi=01.20然后回带到1.18式,得到:
minw,bL(w,b,α)=−12∑i=1N∑j=1Nαiαjyiyj(xi∗xj)+∑i=1Nαi求 minw,bL(w,b,α) 对 α 的极大:
maxα(−12∑i=1N∑j=1Nαiαjyiyj(xi∗xj)+∑i=1Nαi)s.t. ∑i=1Nαiyi=0α≥0, i=1,2,...,N
线性可分支持向量机学习算法
输入:线性可分数据集 T={(x1,y1),(x2,y2),···,(xN,yN)},其中,xi∈χ=Rn,yi∈γ={−1,+1}, i=1,2,···,N .
输出:最大间隔超平面和分类决策函数;
构造并求解约束最优化问题:
minα(12∑i=1N∑j=1Nαiαjyiyj(xi∗xj)−∑i=1Nαi)s.t. ∑i=1Nαiyi=0α≥0, i=1,2,...,N求得最优解 α∗=(α∗1,α∗2,...α∗N)T
计算:
w∗=∑i=1Nα∗iyixi并选择 α∗i 的一个正分量 α∗j≥0 (其实这个点就是一个支持向量),计算:
b=yi−∑i=1Nα∗iyi(xi∗xj)由此得到超平面:
w∗∗x+b∗=0分类决策函数:
f(x)=sign(ω∗+b)
线性支持向量机和软间隔最大化
线性支持向量机区别于线性可分支持向量机,在于面对的是线性不可分的数据,修改硬间隔最大化,变为软间隔最大化。其实一般实际数据都是线性不可分的,因为总会有随机噪声存在。
线性不可分意味着样本点不能满足函数间隔大于1的约束条件,因此在每个样本点引进一个松弛变量 ξi≥0 ,使得约束条件为:
因此目标函数也发生变化,线性不可分支持向量机学习问题变成如下凸二次优化问题:
其中C是调和间隔最大化和误分类点的个数两者的系数,C比较大时对误分类的惩罚增大。
线性支持向量机学习算法
输入:线性可分数据集 T={(x1,y1),(x2,y2),···,(xN,yN)} ,其中, xi∈χ=Rn,yi∈γ={−1,+1}, i=1,2,···,N ;
输出:最大间隔超平面和分类决策函数;
选择惩罚项参数 C≥0 ,构造并求解凸二次规划问题:
minα(12∑i=1N∑j=1Nαiαjyiyj(xi∗xj)−∑i=1Nαi)s.t. ∑i=1Nαiyi=00≤α≤C, i=1,2,...,N求得最优解 α∗=(α∗1,α∗2,...α∗N)T
计算:
w∗=∑i=1Nα∗iyixi并选择 α∗i 的一个正分量 C≥α∗j≥0 (其实这个点就是一个支持向量),计算:
b=yi−∑i=1Nα∗iyi(xi∗xj)由此得到超平面:
w∗∗x+b∗=0分类决策函数:
f(x)=sign(ω∗+b)
步骤2中,由于原始问题对b的解并不唯一,所以实际计算时选取在所有符合条件的样本点上的平均值。
非线性支持向量机和核函数
核技巧
非线性分类问题
对于给定的训练数据集 T={(x1,y1),(x2,y2),···,(xN,yN)} ,其中, xi∈χ=Rn,yi∈γ={−1,+1}, i=1,2,···,N 。如果能用 Rn 中单的一个超曲面将正负样例正确分开,则称这个问题为非线性可分问题。
非线性问题难以求解,所以进行一个非线性变换,将非线性问题变换为线性问题,通过解变换后的线性问题的方法求解原来的非线性问题。
核技巧的基本思想就是通过一个非线性变换将输入空间对应一个特征空间,使得在输入空间中的超曲面模型对应特征空间中的超平面模型,这样分类问题的学习就可以通过在特征空间中求解线性支持向量机完成。
核函数定义
核函数: 设 χ 是输入空间(欧式空间),设 H 为特征空间(希尔伯特空间),如果存在一个从 χ 到 H 的映射:
使得对所有的 x,z∈χ ,函数 K(x,z) 满足条件:
则称 K(x,z) 为核函数, ϕ(x) 为映射函数,式中 ϕ(x)∗ϕ(x) 为内积。
核技巧的思想在于学习预测中只定义核函数 K(x,z) ,而显式地定义函数映射。因为通常直接计算核函数 K(x,z) 比较容易,而通过 ϕ(x),ϕ(z) 计算 K(x,z) 并不容易。
核技巧在支持向量机中的应用
在支持向量机对偶问题中,目标函数和决策函数都涉及输入实例之间的内积形式,在对偶问题中目标函数 xi∗xj 可以用核函数 K(xi,xj)=ϕ(xi)∗ϕ(xj) 代替。目标函数变为:
分类决策函数变为:
正定核
不用构造 ϕ(x) 能否直接判断给定函数 K(x,z) 是否是核函数?或者说满足核函数需要什么条件呢?
首先为什么要是正定核:当 K(x,z) 是正定核函数时,这是一个凸二次规划问题,解释存在的。
正定核函数(正定核)的充要条件:设 K:χ×χ→R 是对称函数,则 K(x,z) 为正定核函数的充要条件是对任意 xi∈χ,i=1,2,...,m, K(x,z) 对应的Gram矩阵:
是半正定矩阵。
常用核函数
多项式核函数。
K(x,z)=(x∗z+1)p
对应的支持向量机是一个p次多项式分类器,再次情况下,分类决策函数为:
f(x)=sign(∑i=1Nsα∗iyi(xi∗x+1)p+b∗)高斯核函数。
K(x,z)=exp(−||x−z||22σ2)对应的支持向量机是高斯径向基函数分类器,分类决策函数为:
f(x)=sign(∑i=1Nsα∗iyiexp(−||x−z||22σ2)+b∗)字符串核函数。
核函数不仅可以定义在欧式空间,还可以定义在离散数据集合熵,比如字符串核是定义在字符串集合上的核函数。字符串核函数在文本分类、信息检索、生物信息学方面都有应用。
非线性支持向量机学习算法
输入:训练数据集 T={(x1,y1),(x2,y2),···,(xN,yN)} ,其中, xi∈χ=Rn,yi∈γ={−1,+1}, i=1,2,···,N ;
输出:分类决策函数;
选取适当的核函数 K(x,z) 和适当的参数C,构造并求解最优化问题:
minα(12∑i=1N∑j=1NαiαjyiyjK(xi,xj)−∑i=1Nαi)s.t. ∑i=1Nαiyi=0C≥α≥0, i=1,2,...,N求得最优解 α∗=(α∗1,α∗2,...α∗N)T
选择 α∗i 的一个正分量 α∗j≥0 (其实这个点就是一个支持向量),计算:
b=yi−∑i=1Nα∗iyiK(xi,xj)构造分类决策函数:
f(x)=sign(∑i=1Nsα∗iyiK(xi,x)+b∗)
当 K(x,z) 是正定核函数时,这是一个凸二次规划问题,解释存在的。
附录
算法分类
机器学习算法按照学习方式分为监督学习、非监督学习、半监督学习、强化学习
监督学习:从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。训练集中的目标是由人标注的。
非监督式学习:与监督学习相比,训练集没有人为标注的结果。常见的非监督式学习算法有聚类。
半监督式学习:输入数据部分被标识,部分没有被标识,介于监督式学习与非监督式学习之间。常见的半监督式学习算法有支持向量机。
强化学习:在这种学习模式下,输入数据作为对模型的反馈,不像监督模型那样,输入数据仅仅是作为一个检查模型对错的方式,在强化学习下,输入数据直接反馈到模型,模型必须对此立刻作出调整。常见的强化学习算法有时间差学习。
按照算法类似性分为决策树学习、回归、聚类、人工神经网络
决策树:根据数据的属性采用树状结构建立决策模型。决策树模型常常用来解决分类和回归问题。常见的算法包括 CART (Classification And Regression Tree)、ID3、C4.5、随机森林 (Random Forest) 等。
回归算法:试图采用对误差的衡量来探索变量之间的关系的一类算法。常见的回归算法包括最小二乘法 (Least Square)、逻辑回归 (Logistic Regression)、逐步式回归 (Stepwise Regression) 等。
聚类算法:通常按照中心点或者分层的方式对输入数据进行归并。所有的聚类算法都试图找到数据的内在结构,以便按照最大的共同点将数据进行归类。常见的聚类算法包括 K-Means 算法以及期望最大化算法 (Expectation Maximization) 等。
人工神经网络:模拟生物神经网络,是一类模式匹配算法。通常用于解决分类和回归问题。人工神经网络算法包括感知器神经网络 (Perceptron Neural Network) 、反向传递 (Back Propagation) 和深度学习等。
CSDN博客:http://blog.csdn.net/shine19930820/article/details/62892088
参考资料
《统计学习方法》
《The Elements of Statistical Learning 》
《Machine Learning A Probabilistic Perspective》
Top 10 algorithms in data mining
相似算法:
- 『数据挖掘十大算法 』笔记一:决策树
- 『数据挖掘十大算法 』笔记二:SVM-支持向量机
- 『数据挖掘十大算法 』笔记三:K-means