python爬虫实战(六) 天猫(淘宝)评论爬取与分析实战
目录
- 一、天猫(淘宝)爬取地址对比
- 二、防爬技巧
- 三、数据分析
一、天猫(淘宝)爬取地址对比
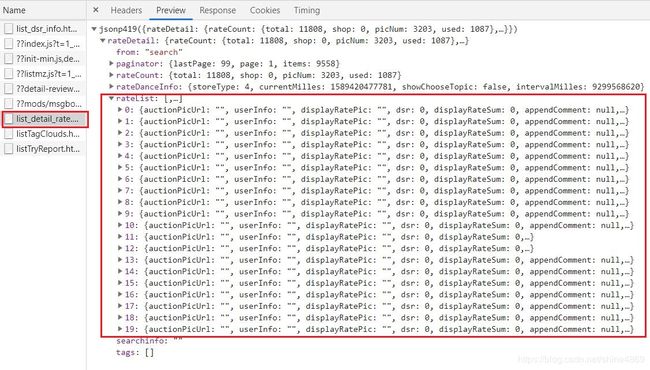
天猫评论抓包json数据如下,在list_detail_rate中,一页二十个用户信息:
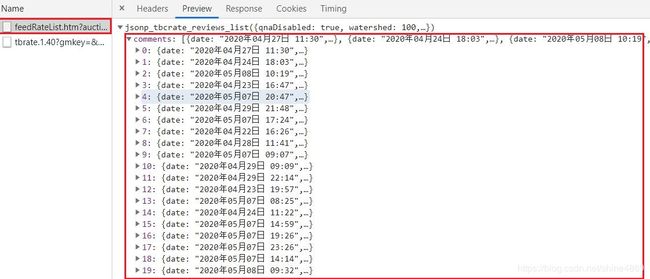
淘宝评论抓包的json数据如下,同样是一页二十个,不过是在feedRateList中
两者的爬取过程基本相同,在此以天猫为例,爬取的内容是口罩的评论。
二、防爬技巧
1.请求头一定设置完全!!
先前,因为请求头设置的参数不完全,导致爬到数据要么为空,要么就被返回一个不知名的URL。故一定要把请求头该有的参数都添加上
基本参数设置如下:
headers = {
'cookie':'你的cookie',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.6.77f65d5c5Awoik&id=613110434906&skuId=4352166796016&areaId=500100&user_id=2206943654630&cat_id=2&is_b=1&rn=74e1dcbd42307c1199e6fb4d70c6ae1b',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9'
}
其中,cookie,user-agent,referer是必须要添加的,accept-encoding和accept-language可视情况添加。
2.尽量设置随机用户代理或cookie
用户代理(User-agent)一般好找,这里提供一些:
"Opera/9.80 (X11; Linux i686; Ubuntu/14.10) Presto/2.12.388 Version/12.16",
"Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Windows NT 6.0) Presto/2.12.388 Version/12.14",
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
cookie因涉及到个人隐私问题,有条件地可以多找一些。
3.尽量减少调试代码的次数
这些大型的商务网站,经不起你一次次地去调试代码。一旦你的IP超过它设置的访问次数,它就会立马禁用的。所以,在执行代码前,务必要检查语法错误和可能出现的编码错误。
此外,根据上面分析的结果,评论数据都是封装在json数据下,但是直接去用json模块解析会报jsonDecodeError。原因在于:在json字符串外面有个json419,需要去除后再解析。
或者,可直接用正则去提取所需部分信息。
这里使用地是正则提取:
爬取代码:
import re
import requests
import random
import time
import os
import pandas as pd
os.chdir('C:/Users/dell/Desktop')
df=[]
head=[
"Mozilla/5.0 (Windows NT 6.0; rv:2.0) Gecko/20100101 Firefox/4.0 Opera 12.14",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14",
"Opera/12.80 (Windows NT 5.1; U; en) Presto/2.10.289 Version/12.02",
"Opera/9.80 (Windows NT 6.1; U; es-ES) Presto/2.9.181 Version/12.00",
"Opera/9.80 (Windows NT 5.1; U; zh-sg) Presto/2.9.181 Version/12.00",
]
headers = {
'cookie':'你的cookie',
'user-agent': random.choice(head),
'referer': 'https://detail.tmall.com/item.htm?spm=a220m.1000858.1000725.6.77f65d5c5Awoik&id=613110434906&skuId=4352166796016&areaId=500100&user_id=2206943654630&cat_id=2&is_b=1&rn=74e1dcbd42307c1199e6fb4d70c6ae1b',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9'
}
url_left='https://rate.tmall.com/list_detail_rate.htm?itemId=613110434906&spuId=1537276390&sellerId=2206943654630&order=3¤tPage='
url_right='append=0&content=1&tagId=&posi=&picture=&groupId=&ua=098%23E1hvAvvUvbpvUvCkvvvvvjiPn2cp1jEbnLqvzjivPmP91j3vn2cy1jE2PFchljimiQhvCvvvpZpPvpvhvv2MMQhCvvOv9hCvvvvEvpCWvWLp6C0yHd8rjC6sQa7tnCpO4Z7xfXeK5dUfUz7Q%2Bu6wd56bS4ZAhC97EcqhaXTAdXyaWXxrV8TJh7ERD70fdigOfvc6gEKX5CO07fyCvm9vvhCvvvvvvvvvpigvvvHivvCVB9vv9LvvvhXVvvmCjvvvByOvvUhwkphvC9hvpyPwg8yCvv9vvhhsphWAC2yCvvpvvhCv&needFold=0&_ksTS=1589419995635_415&callback=jsonp416'
def get_html(url,header):
r=requests.get(url,headers=header)
if r.status_code==200:
return r.text
else:
print('网络连接异常')
def get_item(num):
user_name=[]
item_type=[]
rate_content=[]
rate_date=[]
for page in range(1,num):
url=url_left+str(page)+url_right
try:
text=get_html(url,headers)
user_name.extend(re.findall('"displayUserNick":"(.*?)"',text))
item_type.extend(re.findall('"auctionSku":"(.*?)"',text))
rate_content.extend(re.findall('"rateContent":"(.*?)"',text))
rate_date.extend(re.findall('"rateDate":"(.*?)"',text))
print("第{}页爬取完毕".format(page))
time.sleep(2+random.randint(1,3))
except:
print("未爬取数据")
for i in range(len(user_name)):
df.append([user_name[i],rate_date[i],item_type[i],rate_content[i]])
print('共{}条商品信息写入完毕'.format(len(user_name)))
df1=pd.DataFrame(df,columns=['user_name','rate_date','item_type','rate_content'])
df1.to_csv('taobao_item.csv',index=False,encoding='gb18030')
if __name__=='__main__':
num=51
get_item(num)
爬取数据结果如下:

不难看出,我爬取的是50页,理论上应该返回1000条数据。实际上只有640条数据,也就是在33页之后应该就被识别出来,然后返回空数据。所以,如果想要爬取尽可能多的数据,可以多找一些可用的IP和cookie。
三、数据分析
1.查找爬取评论的时间分布
A.按天数对原数据集进行重采样
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['kaiti']
plt.style.use('ggplot')
%config InlineBackend.figure_format='svg' #转为矢量图更清晰
data=pd.read_csv('taobao_item.csv',encoding='gb18030',
parse_dates=['rate_date'],
infer_datetime_format=True,
index_col='rate_date')
data['count']=1
df=data['count'].resample('D').sum().to_frame()
df.index=df.index.map(lambda x : str(x.month)+'月'+str(x.day)+'日')
plt.figure(figsize=(10,5))
plt.plot(df.index,df['count'],alpha=0.7,marker='o',label='评论次数')
plt.title('爬取评论的时间分布情况')
plt.xlabel('时间')
plt.ylabel('评论次数')
plt.legend(loc='best')
plt.xticks(df.index,rotation=90)
plt.show()
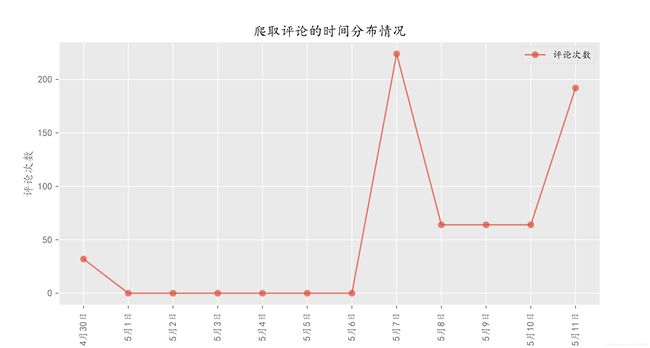
爬取的评论大多都是5月7日和5月11日的数据
B.按小时对原数据进行重采样
df=data['count'].resample('H').sum().to_frame()
df.index=df.index.map(lambda x:str(x).split(' ')[1])
df_new=df.reset_index().groupby('rate_date').agg({'count':np.sum})
plt.figure(figsize=(10,5))
plt.plot(df_new.index,df_new['count'],alpha=0.7,marker='o',label='评论次数')
plt.title('爬取评论的按小时分布情况')
plt.xlabel('时间')
plt.ylabel('评论次数')
plt.legend(loc='best')
plt.xticks(df_new.index,rotation=90)
plt.show()
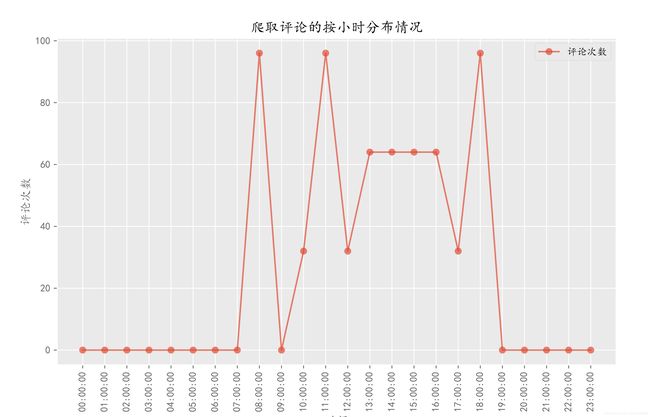
从小时分布来看,用户在最喜欢在早上8:00-9:00,11:00-12:00以及晚上18:00-19:00期间购买口罩
2.购买口罩的种类分布
data['item_type']=data['item_type'].map(lambda x : re.search('.*(【.*?】)',x).group(1)
if re.search('.*(【.*?】)',x) is not None else '单只购买')
data=data.replace({'【5只】':'【白色5只】','【10只】':'【白色10只】','【20只】':'【白色20只】'})
mask_type=data['item_type'].value_counts().to_frame()
mask_type.index=mask_type.index.map(lambda x : x.strip('【】') if '【' in x else x)
plt.pie(mask_type['item_type'],
labels=mask_type.index,
startangle=90,
shadow=False,
colors=['#34314c','#47b8e0','#ffc952','#ff7473'],
textprops={'fontsize': 12, 'color': 'w'},
autopct='%1.1f%%',
counterclock = False
)
plt.title('用户购买各类口罩占比分布')
plt.axis('equal')
plt.tight_layout()
plt.legend(loc='upper right',frameon=False)
plt.show()
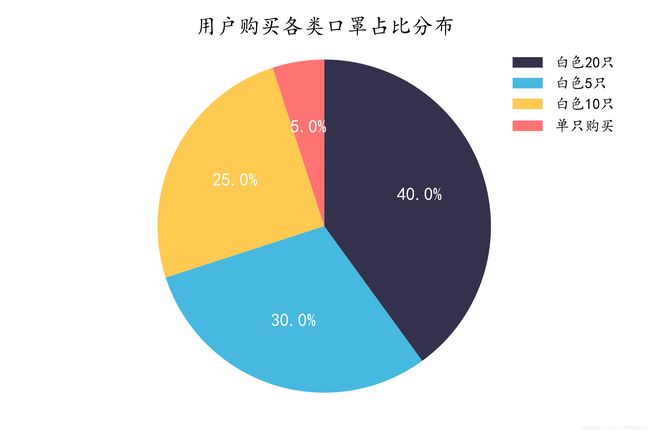
3.评论高频词分布
import csv
import jieba
from itertools import islice
csv_file=open('C:/Users/dell/Desktop/taobao_item.csv',encoding='gb18030')
csv_reader_lines = csv.reader(csv_file)
stopwords=[line.strip() for line in open('C:/Users/dell/Desktop/stopwords.txt','r',encoding='utf-8').readlines()]
comment={}
for line in islice(csv_reader_lines,1,None):
poss=jieba.cut(line[3])
for word in poss:
if word in stopwords or len(word)<2:
continue
if comment.get(word) is None:
comment[word]=0
else:
comment[word]+=1
comment=dict(sorted(comment.items(),key=lambda x:x[1],reverse=True))
count=1
comment_count=[]
for key,value in comment.items():
comment_count.append([key,value])
count+=1
if count==11:
break
comment_count=pd.DataFrame(comment_count,columns=['words','counts'])
plt.figure(figsize=(10,6))
plt.bar(comment_count['words'],comment_count['counts'],alpha=0.7,label='次数')
for name,count in zip(comment_count.index,comment_count['counts']):
plt.text(name,count+5,count,ha='center',va='bottom')
plt.title('评论高频词分布情况')
plt.xlabel('高频词')
plt.ylabel('次数')
plt.legend(loc='upper right')
plt.show()
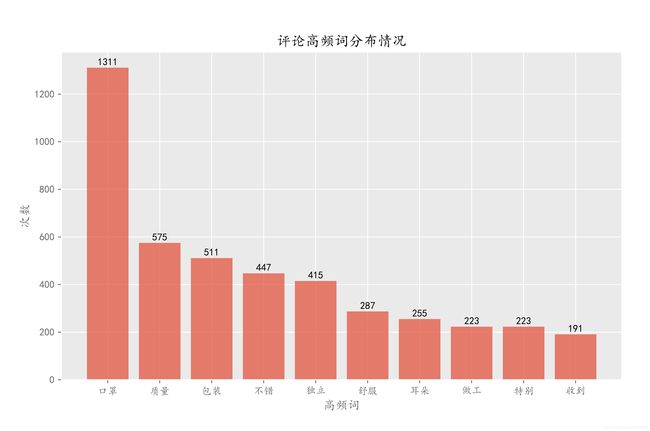
口罩、质量、包装等词汇出现频率较高
以上就是本次分享的全部内容~