Scrapy爬取淘宝网数据的尝试
因为想学习数据库,想要获取较大量的数据,第一个想到的自然就是淘宝。。。。其中有大量的商品信息,淘宝网反爬措施还是比较多,特别是详情页面还有恶心的动态内容
该例子中使用Scrapy框架中的基础爬虫(CrawlSpider还有点没搞清楚= = b)
先贴上整体代码
import scrapy
import re
import csv
import pymongo
from tmail.items import TmailItem
class WeisuenSpider(scrapy.Spider):
name = 'weisuen'
start_url = 'https://s.taobao.com/search?q=%E5%B8%BD%E5%AD%90&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.50862.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170817&s=300'
detail_urls=[]
data=[]
client=pymongo.MongoClient("localhost",27017)
db=client.taobao
db=db.items
def start_requests(self):
for i in range(30):#爬31页数据差不多了
url=self.start_url+'&s='+str(i*44)
yield scrapy.FormRequest(url=url,callback=self.parse)
def url_decode(self,temp):
while '\\' in temp:
index=temp.find('\\')
st=temp[index:index+7]
temp=temp.replace(st,'')
index=temp.find('id')
temp=temp[:index+2]+'='+temp[index+2:]
index=temp.find('ns')
temp=temp[:index]+'&'+'ns='+temp[index+2:]
index=temp.find('abbucket')
temp='https:'+temp[:index]+'&'+'abbucket='+temp[index+8:]
return temp
def parse(self, response):
item=response.xpath('//script/text()').extract()
pat='"raw_title":"(.*?)","pic_url".*?,"detail_url":"(.*?)","view_price":"(.*?)"'
urls=re.findall(pat,str(item))
urls.pop(0)
row={}.fromkeys(['name','price','link'])
for url in urls:#解析url并放入数组中
weburl=self.url_decode(temp=url[1])
item=TmailItem()
item['name']=url[0]
item['link']=weburl
item['price']=url[2]
row['name']=item['name']
row['price']=item['price']
row['link']=item['link']
self.db.insert(row)
row={}.fromkeys(['name','price','link'])
self.detail_urls.append(weburl)
self.data.append(item)
return item
for item in self.detail_urls:#这个可以抓取评论等更多相关信息
yield scrapy.FormRequest(url=item,callback=self.detail)
def detail(self,response):
print(response.url)
#首先判断url来自天猫还是淘宝
if 'tmall' in str(response.url):
pass
else:
passitems.py中定义3个属性:name,price,link
起始网页为淘宝的搜索地址,关键字我设置为“帽子”,当然修改关键字就只需要修改一下url中的q=后面的值就可以了
因为该类型商品信息量很大,有很多页所以重写start_requests(self)方法,获取前31页的内容
首先
name = 'weisuen'
start_url = 'https://s.taobao.com/search?q=%E5%B8%BD%E5%AD%90&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.50862.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170817&s=300'
detail_urls=[]
data=[]
client=pymongo.MongoClient("localhost",27017)
db=client.taobao
db=db.items
def start_requests(self):
for i in range(30):#爬31页数据差不多了
url=self.start_url+'&s='+str(i*44)
yield scrapy.FormRequest(url=url,callback=self.parse)
def parse(self, response):
item=response.xpath('//script/text()').extract()
pat='"raw_title":"(.*?)","pic_url".*?,"detail_url":"(.*?)","view_price":"(.*?)"'
urls=re.findall(pat,str(item))
urls.pop(0)
row={}.fromkeys(['name','price','link'])
for url in urls:#解析url并放入数组中
weburl=self.url_decode(temp=url[1])
item=TmailItem()
item['name']=url[0]
item['link']=weburl
item['price']=url[2]
row['name']=item['name']
row['price']=item['price']
row['link']=item['link']
self.db.insert(row)
row={}.fromkeys(['name','price','link'])
self.detail_urls.append(weburl)
self.data.append(item)
return item
for item in self.detail_urls:#这个可以抓取评论等更多相关信息
yield scrapy.FormRequest(url=item,callback=self.detail)在回调函数中对获取的网页数据进行解析,这里遇到的麻烦就是response.text会报错‘GBK xxxxx’因为淘宝网页不仅仅由UTF-8编码还有其他编码格式所以这样解码就会出现问题,我这里采取的是先使用xpath获取所有相关类容,再使用正则表达式对相关信息进行提取。其中每件商品的url都有动态类容需要去掉,这个使用了一个url_decode()方法去掉其中的动态类容。解码方法代码如下:
def url_decode(self,temp):
while '\\' in temp:
index=temp.find('\\')
st=temp[index:index+7]
temp=temp.replace(st,'')
index=temp.find('id')
temp=temp[:index+2]+'='+temp[index+2:]
index=temp.find('ns')
temp=temp[:index]+'&'+'ns='+temp[index+2:]
index=temp.find('abbucket')
temp='https:'+temp[:index]+'&'+'abbucket='+temp[index+8:]
return temp最后返回的url是可以直接打开的,在回调函数parse中将相关类容写入了数据库中,为了便于扩展,parse中生成了对于详情页面的请求,可以之后进行评论,评分等相关信息的抓取
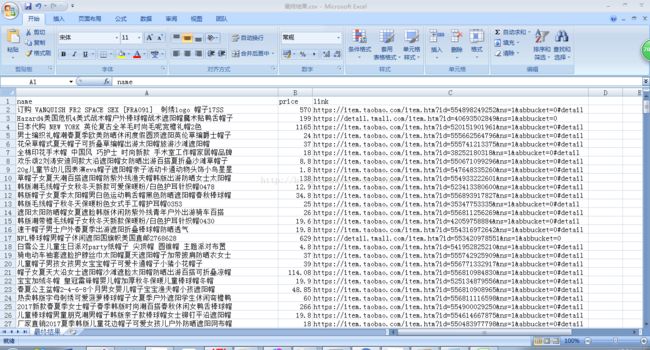
数据库内容:
之前生成的CSV文件