python3的文件操作
一、读写文件
1.
1.对文件进行操作我们需要用到open模块。
(1)open模块的用法:open(name(文件名,最好用绝对路径)[mode(以什么模式打开),buffering(缓存)]) 他返回的是一个文件对象。
(2)mode 模式:
1.r: 以只读模式打开 只能读,不能写,必须打开一个存在的文件,如果文件不存在会报错。
2.w:以写模式打开 如果文件不存在则创建,如果文件存在,会覆盖文件内容。所以要小心使用写模式。
3.a:以追加模式打开 如果文件存在,会在文件最后追加内容。如果文件不存在也会创建。
4.r+:以读写模式打开
5.w+: 以读写模式打开,和w模式类似。慎用。
6.a+ :以读写模式打开,和a模式类似。
7.rb : 以二进制读模式打开
8.wb: 以二进制写模式打开 和w模式类似
9.ab:以二进制追加模式打开 和a模式类似
10rb+: 以二进制读写模式打开 和r+模式类似
11.wb+:以二进制读写模式打开 和w+类似
12.ab+:以二进制读写模式打开 和a+类似
小例子:
filename = input("输入你要的文件名: ")
fd = open(filename, 'w') #以写入模式打开文件,写入模式需要注意的是,每次写入都会把文件内容情况。要注意使用这种模式。
while 1: #使用while 1的形式 效率最高。
conttext = input("输入文件的内容(输入EOF结束写入): ")
if conttext == 'EOF':
fd.close() #输入EOF就退出写入,关闭文件
break
else: #写入文件内容
fd.write(conttext)
fd.write('\n') #写入换行,不然会写在一行上。 写入的数据必须是字符串
fdread = open(filename) #打开文件,默认是读模式。
print("###############开始######################")
readconttxt = fdread.read() #把读到的文件内容放到变量里打印
print(readconttxt)
print("###############结束######################")
二、文件方法
1.文件常用方法:
readline()方法: 读一行内容,返回字符串。
文件内容有5行,使用readline 只读取一行

ENCODING = "utf-8" #定义文件的字符编码。
with codecs.open('1.log', encoding=ENCODING) as fd: #使用codecs模块来防止文件乱码。
print(fd.readline())

readlines()方法:读多行内容,并且返回的是一个list 列表,每一行的内容为一个元素
print(fd.readlines())

read()方法:对文件从头读到尾
fd.read() 返回字符串。
print(fd.read())

Python3 没有了next方法了
write方法:写入文件,这个方法不是是只读模式打开。
写入的东西,必须是字符串其他都不接受,会报错。
.name函数返回文件名
print(fd.name)

.endoding函数 查看文件编码格式
print(fd.endoding)

.mode 查看文件打开模式
print(fd.mode)

使用with codecs.open() as fd 这种方式来操作文件,是最好的
3.Python2的乱码问题。
Python3 的编码问题 改进的特别好。Python2 就有很多问题。
目前使用支持的编码格式有3个:utf-8 gbk gb-2312
python 2的默认编码格式就是ASCII,所以不支持中文
print(sys.getdefaultencoding())
需要识别中文的话 要在文件的头部增加# -*- coding: UTF-8 -*-
print(sys.getdefaultencoding())
print("文件编码")
使用Python2来运行这个段代码会出现乱码

如果指定格式就不会可以在字符串前加一个u来表示安装uft-8编码来存放。
print(sys.getdefaultencoding())
print(u"文件编码")
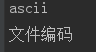
还可以使用解码方式来正确显示中文
a = "文件编码"
print(a.decode("utf-8"))
python 会自动的先将字符串解码为unicode ,然后在编码成gbk,因为解码是Python自动进行的,我们没有指明解码方式,Python 就会使用sys.defaultencoding指明的方式来解码。
还可以用这种方式:
s = "中文"
print(s.decode("utf-8").encode("gbk"))
先解码utf-8 在编码gbk,就可以显示了
四、
Python对passwd文件进行排序
四、Python对passwd文件进行排序
import codecs
filename = "passwd"
sortfilename = "sortpasswd.txt"
fileconttext = []
sortuid = []
with codecs.open(sortfilename, 'w') as fd: #对排序后的passwd,写入到新的文件中
with codecs.open(filename) as f: #读取文件
fileconttext += f.readlines() # 追加到列表里
for line in fileconttext: #遍历列表
sortuid.append(int(line.split(":")[2])) #取出下标2的第三列数字,必须转出int型才可以正确排序
sortuid.sort() #对数字进行排序,写在循环外得到一个完整的序列
for uid in sortuid: #遍历sortuid 得到数字和原本对比。
for line in fileconttext: #遍历源文件 与排序后的数字对比
if str(uid) == line.split(":")[2]: #得到的int型,与str 不能对比,所以转换成str 来对比
fd.write(line) #写入新文件。