【CCF大数据与计算智能大赛】互联网新闻情感分析(使用LSTM完成中文文本多分类任务)
使用LSTM完成文本多分类任务
这只是把keras的教程用于实战的练手项目,对于真正希望打出好的比赛成绩必须要用到各种(bert等)预训练模型
赛题地址:
https://www.datafountain.cn/competitions/350
代码源于keras作者的《Deep Learning with Python"》
https://nbviewer.jupyter.org/github/fchollet/deep-learning-with-python-notebooks/blob/master/3.5-classifying-movie-reviews.ipynb
原书中使用的IMDB 的数据做二分类问题,而这个赛题下需要做的是三分类问题,读入的是中文数据,需要对代码进行一些修改和添加
数据集解析
官方给出的数据集文件共三个
Train_DataSet.csv
Test_DataSet.csv
Train_DataSet_Label.csv
训练集共id,title,content三列,存储了ID,新闻标题,新闻内容三种内容

我们需要读入数据集
import pandas as pd
train_df = pd.read_csv('Train_DataSet.csv', header=0)
test_df = pd.read_csv('Test_DataSet.csv', header=0)
train_lable = pd.read_csv('Train_DataSet_Label.csv', header=0)
print(train_df.shape,test_df.shape,train_lable)
#变量转换为字符型
train_df['title'] = train_df['title'].astype(str)
train_df['content'] = train_df['content'].astype(str)
test_df['title'] = test_df['title'].astype(str)
test_df['content'] = test_df['content'].astype(str)
#拼接标题和内容
#Phrase_list = train_df['title'].astype(str)
Phrase_list = train_df['title'].str.cat(train_df['content'],sep= '-')
X_test = test_df['title'].str.cat(test_df['content'],sep= '-')
print(Phrase_list)
然后对中文进行分词
jieba分词
import jieba
import pandas as pd
train_df = pd.read_csv('Train_DataSet.csv', header=0)
test_df = pd.read_csv('Test_DataSet.csv', header=0)
train_lable = pd.read_csv('Train_DataSet_Label.csv', header=0)
print(train_df.shape,test_df.shape,train_lable)
#变量转换为字符型
train_df['title'] = train_df['title'].astype(str)
train_df['content'] = train_df['content'].astype(str)
test_df['title'] = test_df['title'].astype(str)
test_df['content'] = test_df['content'].astype(str)
#拼接标题和内容
#Phrase_list = train_df['title'].astype(str)
Phrase_list = train_df['title'].str.cat(train_df['content'],sep= '-')
X_test = test_df['title'].str.cat(test_df['content'],sep= '-')
print(Phrase_list)
Phrase_list1 = []
X_test1 = []
k = 0
for i in Phrase_list:
seg_list = jieba.cut(i, cut_all=True)
seg_list = " ".join(seg_list)
Phrase_list1.append(seg_list)
k = k+ 1
print(k,'/',len(Phrase_list),'-----------------------------------------')
k=0
for i in X_test:
seg_list = jieba.cut(i, cut_all=True)
seg_list = " ".join(seg_list)
X_test1.append(seg_list)
k = k+ 1
print(k,'/',len(X_test),'-----------------------------------------')
k=0
Phrase_list1 = pd.Series(Phrase_list1)
X_test1 = pd.Series(X_test1)
GloVe训练词向量
中文词训练可以参考这篇博文
https://blog.csdn.net/weixin_37947156/article/details/83145778
简而言之,把title和content的内容分词后,写成一个txt文件
从GitHub下载GloVe代码,https://github.com/stanfordnlp/GloVe
将语料txt放入到Glove的主文件夹下。注释掉
将语料corpus.txt放入到Glove的主文件夹下。
修改bash 打开demo.sh,修改相应的内容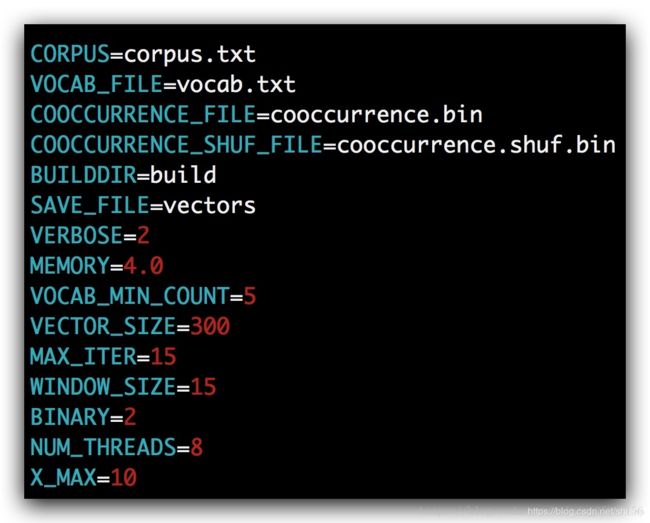
因为demo默认是下载网上的语料来训练的,因此如果要训练自己的语料,需要注释掉 修改参数设置,将CORPUS设置成语料的名字 执行bash文件
得到了词表文件,vocab.txt
将vocab.txt复制到工程下
keras搭建LSTM分类
glove_dir = r'D:\CCF互联网新闻情感分析\glove.6B\vocab.txt'
#加载词表文件
embeddings_index = { }
f = open(glove_dir,encoding='UTF-8')
for line in f:
values = line.split()
word = values[0]
coefs = np.asanyarray(values[1:],dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
embedding_dim = 300
embedding_matrix = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < max_words:
if embedding_vector is not None:
# Words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
########################################
from keras.models import Sequential
from keras.layers import Flatten, Dense, Embedding,SimpleRNN
from keras.layers import LSTM
from keras.layers import GRU
max_features = max_words
model = Sequential()
model.add(Embedding(max_features,300))
model.add(LSTM(64,return_sequences=True))
model.add(LSTM(32,activation='relu',
dropout=0.1,
))
model.add(Dense(3,activation='softmax'))#三分类问题,此处需要换成3,并使用激活函数softmax
#######################################################################
model.layers[0].set_weights([embedding_matrix])
model.layers[0].trainable = False
##########################################################################
model.compile(optimizer='rmsprop', loss = 'categorical_crossentropy',metrics=['acc'])
#损失函数改为
history = model.fit(x_train, y_train,
epochs=37,
batch_size=128,
validation_split=0.1
)
预测结果
from keras.models import load_model
model.save('LSTM_model.h5') # creates a HDF5 file 'my_model.h5'
del model # deletes the existing model
# returns a compiled model
# identical to the previous one
model = load_model('LSTM_model.h5')
y = model.predict_classes(X_test)
print(y)
#将标签和预测结果组合并写入csv文件。
ID = test_df['id']
def write_preds(ID , fname):
pd.DataFrame({"PhraseId": ID, "Sentiment": y}).to_csv(fname, index=False, header=True)
#sentiment-analysis-on-movie-reviews
write_preds(ID , "CCF-LSTMkeras.csv")
#绘制结果
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc,'bo',label = 'Training acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('Taining and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss,'bo',label = 'Training loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('Taining and validation accuracy')
plt.legend()
plt.show()
将找到过拟合之前的epochs,所得结果提交CCF-LSTMkeras.csv,完成!