Kafka 与消息队列的快速比较
本文译自: A super quick comparison between kafka and Message Queues
本文旨在对 Kafka 与消息队列之间进行一个快速比较, 以及为何应该使用 Kafka.
Kafka 起初是由 Linkedin 发展而来. 总的看来, 它有点像一个消息队列系统, 并做了一些调整使其能够支持发布/订阅, 在多个服务器上进行扩展, 对消息进行重放 (或者说, “重复消费”).
当你想要采用响应式编程 (reactive programming) 而非命令式编程 (imperative programming) 时, 下面注意以下一些点:
响应式编程与命令式编程的不同之处
命令式编程, 其实我们开始学习编程时的编程类型就是命令式编程. 当一个事件发生时, 代码里就会对该事件进行通知. 比如说, 用户点击一个按钮时, 你就会在代码中处理该事件. 或许是想要保存记录到一个数据库中, 调用另一个服务, 发送文件, 或是所有的这些操作. 这里的关键点在于, 事件直接与具体发生的动作相关联.
响应式编程允许你对发生的事件进行响应, 而这通常是以流 (stream) 的形式. 多个关注点可以订阅同一个事件, 并且无论在其他作用域中发生了什么, 仅仅让事件作用于自己的域 (domain) 中. 换句话说, 它允许松散耦合的代码, 能够轻松扩展更多功能. 在不同堆栈中编码的各种大型下行系统都可能受到一个事件, 甚至是一些在云端某处运行的无状态函数的影响。
从消息队列到 Kafka
为了理解 Kafka 能够给整个架构带来什么, 让我们先从消息队列谈起. 因为我们会谈到消息队列的一些不足, 并且看到 Kafka 是如何应对这些缺点.
一个消息队列允许多个订阅者从队列尾部抓取一个或是多个消息. 在拉取消息时, 消息队列通常允许进行某种级别的事务处理,以确保在删除消息之前, 所需的操作已经得到执行。
并非所有的队列系统都具有相同的功能,但是一旦消息被处理后,它就会被从队列中删除。仔细想一下,它非常类似于命令式编程,当事件发生时,原始系统就决定了在下游系统中应该执行的某个操作。
即使你可以在队列上对多个消费者进行扩展,但它们都包含相同的功能,这仅仅是为了并行加载和处理消息,换句话说,它不允许你基于同一事件启动多个独立操作。队列消息的所有处理程序 (processor) 都将在同一问题域 (problem domain) 中执行相同类型的逻辑 (same logic)。这也意味着队列中的消息实际上是命令 (command) (适用于命令式编程),而不是一个事件(event) (适用于响应式编程)。
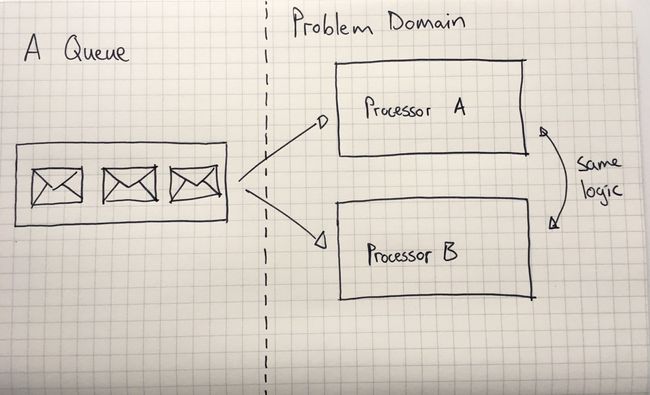
(使用队列时, 对于队列中的每个消息你会在同一个域中执行同样的逻辑.)
不同的是,Kafka 则将消息(message)/事件(event)发布到主题(topic),并会将它们进行持久化。当消费者接收到消息/事件后,它们不会被删除。这允许您重放消息,但更重要的是,它允许大量的消费者基于相同的消息/事件处理(不同的)逻辑。
这样一来, 虽然仍然可以在同一个域中进行扩展来并行处理,但实际更重要的是,你可以添加不同类型的消费者,让它们基于相同的事件执行不同的逻辑 (different logic)。换句话说,在 Kafka 中,您可以采用一个响应式的发布/订阅架构。
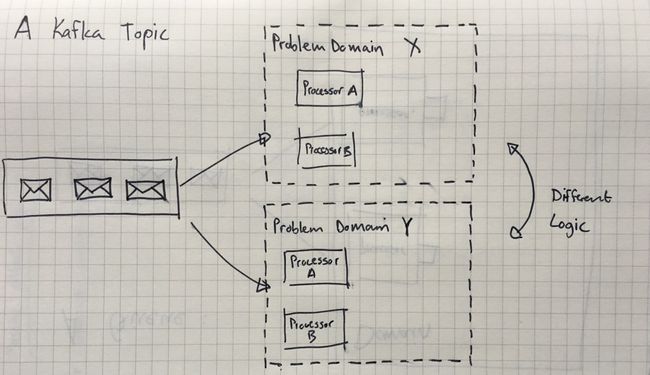
(使用 Kafka, 可以基于同一个事件在不同的系统上执行不同的逻辑.)
由于 Kafka 信息保留和消费者组 (consumer group) 的概念, 这是完全可能的。Kafka 的消费者组在向某个话题询问信息时,会向 Kafka 告知自己的身份。consumer group 消费完消息以后, Kafka 将会记录每个 consumer group 消费信息的偏移量 (offset),以便它不会重复消费。
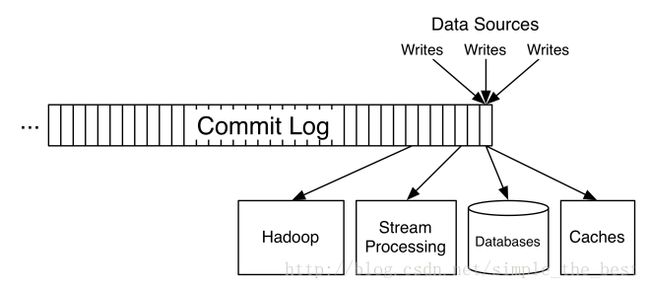
(Hadoop, Stream Processing, Databases 等 consumer group 有着各自的 offset1)
实际情况要复杂得多,因为有一大堆的配置选项可以用来控制细节,但我们并不需要完全了解这些选项, 也可以在高层次地理解 Kafka 的工作机制。
总结
对于 Kafka 来说,还有很多内容,例如它如何管理扩展(分区(partitions))、为了可靠消息传递的配置选项等,但我希望这篇文章足够让您了解为什么考虑使用 Kafka 而不是消息队列。
推荐一个关于 kafka 的系列文章: http://www.jasongj.com/tags/Kafka/
- https://www.confluent.io/blog/stream-data-platform-1/ ↩