python正则表达式和装饰器基础
'''
^(.*)=(.*)$
'\1':'\2',
'''
aaa=12121
type=haha
dfafd=232llambd
fda=33ads
python正则表达式
f = open(str(i)+'.jpg', "wb")
使用二进制写方式打开文件,保存图片,不然图片会马赛克。
正则表达式是:使用单个字符串 来描述 匹配 一系列 符合 某个句法规则的 字符串
正则表达式通常被用来检索、替换那些匹配某个模式的文本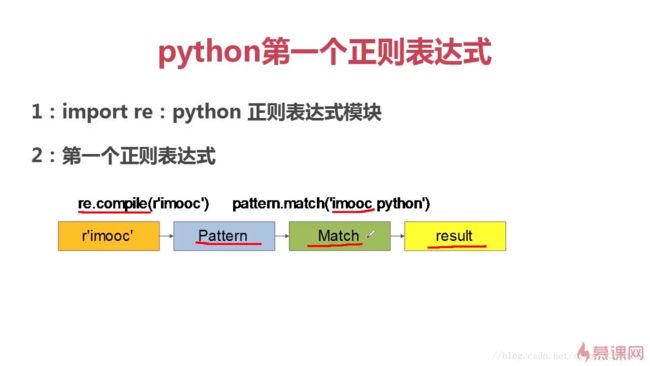
import re
str = "imooc python learning"
pa = re.compile(r"imooc") #生成对象,r表示原字符串,不需要转义
print(type(pa)) #查看定义的规则类型
result_match = pa.match(str) #匹配目标
result = result_match.group() #保存匹配结果
正则表达式中的小括号是代表分组的意思。如果过后面出现了了\1就是代表匹配的内容与第一个小括号内的东西一样
R3=re.match(r'<([\w]+>)[\w]+Python')
\1 其实就是([\w]+>)
re模块的方法:
search,findall,sub,split#coding:utf-8
import urllib.request
req = urllib.request.urlopen('https://www.imooc.com/course/list')
buf = req.read()
buf = buf.decode('utf-8')
import re
urlInfo = re.findall(r'//img.+?\.jpg', buf)
D = {}
for url in urlInfo:
D[url] = url
i = 1
for (url,v) in D.items():
#print(url,i)
f = open('E:\\Eclipse-py\\imooc\\src\\regular\\images\\'+str(i)+'.jpg', 'wb+')
req = urllib.request.urlopen('https:'+url)
buf = req.read()
#buf = buf.encode('utf-8')
f.write(buf)
f.close()
i += 1Python 装饰器
装饰器是什么
严格来说,装饰器只是语法糖,装饰器是可调用的对象,可以像常规的可调用对象那样调用,特殊的地方是装饰器的参数是一个函数。
装饰器的存在是为了适用两个场景,一个是增强被装饰函数的行为,另一个是代码重用。
函数作用域LEGB原则:L>E>G>B
L:local函数内部作用域
E:enclosing函数内部与内嵌函数之间(闭包)
G:global全局作用域
B:build-in内置作用域
闭包:其实就是内部的函数调用外界的变量,外界的变量变了,内部的变量也就变了,弄得这么高深,还什么属性属性的
闭包作用:1.封装 2.代码复用什么是闭包
定义:闭包是一个能够访问其他函数作用域的函数。
下面来解析一下这句话:
- 首先,闭包是一个函数;
- 其次,这个函数不仅能访问自己的作用域,更为关键的是它还能访问其他函数的作用域。
换句话说,如果一个函数能访问其他函数作用域中的变量,那么这个函数就叫做“闭包”。
对函数和执行函数理解
def foo():
print('foohahah')
foo #表示是函数
print(foo)
foo() #表示执行foo函数
#### 第二波 ####
def foo():
print('foo')
foo = lambda x: x + 1 #函数被赋予了新变量
print(foo) #表示函数
print(foo(1)) #表示执行函数结果:
foohahah
2
- 封闭:已实现的功能代码块
- 开放:对扩展开发 #闭包可以很好的解决上诉问题
@装饰器
单独以f1为例:
def w1(func): #装饰器代码
def inner():
# 验证1
# 验证2
func()
return inner
@w1 #最先执行@w1 等价于 w1(f1)
def f1():
print('f1')
python解释器就会从上到下解释代码,步骤如下:
- def w1(func): ==>将w1函数加载到内存
- @w1
没错, 从表面上看解释器仅仅会解释这两句代码,因为函数在 没有被调用之前其内部代码不会被执行。
从表面上看解释器着实会执行这两句,但是 @w1 这一句代码里却有大文章, @函数名 是python的一种语法糖。
上例@w1内部会执行一下操作:
执行w1函数
执行w1函数 ,并将 @w1 下面的函数作为w1函数的参数,即:@w1 等价于 w1(f1) 所以,内部就会去执行:
def inner(): #验证 1 #验证 2 f1() # func是参数,此时 func 等于 f1 return inner# 返回的 inner,inner代表的是函数,非执行函数 ,其实就是将原来的 f1 函数塞进另外一个函数中
w1的返回值
将执行完的w1函数返回值 赋值 给@w1下面的函数的函数名f1 即将w1的返回值再重新赋值给 f1,即:
新f1 = def inner(): #返回新的f1 #验证 1 #验证 2 #有验证 原来f1() #原来函数也执行了 return inner #返回变量函数,新f1的值,还验证了所以,以后业务部门想要执行 f1 函数时,就会执行 新f1 函数,在新f1 函数内部先执行验证,再执行原来的f1函数,然后将原来f1 函数的返回值返回给了业务调用者。
如此一来, 即执行了验证的功能,又执行了原来f1函数的内容,并将原f1函数返回值 返回给业务调用着
类似例子:
def guess_win(func):
def rooftop_status():
print('天台已满,请排队!')
# result = func()
# return result
func()
return rooftop_status
@guess_win
def german_team():
print('德国必胜!')
german_team()上面的例子中我们在压德国队赢的时候,原本的 german_team() 函数只是输出德国必胜,但在使用装饰器(guess_win)后,它的功能多了一项:输出「天台已满,请排队!」。这就是一个简单的装饰器,实现了「增强被装饰函数的行为」。
一个良好的装饰器必须要遵守两个原则:
-
1 不能修改被装饰函数的代码
-
2 不能修改被装饰函数的调用方式
想要很好的理解装饰器,那下面的两个内容需要你先有所认知。
-
1 函数名可以赋值给变量,就是不加括号滴
-
2 高阶函数
def func(name):
print('我是{}!慌的一逼!'.format(name))
func('梅西')
y = func
print(y) #函数就是变量,这里,打印y是内存地址
y('勒夫')
y = func 表明了:函数名可以赋值给变量,并且不影响调用。
高阶函数
高阶函数满足如下的两个条件中的任意一个:a.可以接收函数名作为实参;b.返回值中可以包含函数名。
在 Python 标准库中的 map 和 filter 等函数就是高阶函数。
编写高阶函数,就是让函数的参数能够接收别的函数。
l = [1, 2, 4]
r = map(lambda x: x*3, l) #又有函数,又有变量
for i in r:
print('当前天台人数:', i)自定义一个能返回函数的函数,也是高阶函数:
def f(l):
return map(lambda x: x *5, l)
a = f(l)
for i in a:
print('当前天台人数:', i)
t=[1,2,3] #先定义,再使用
def f(l):
return map(lambda x: x *5, l)
a = f(t) #类似range函数
for i in a:
print('当前天台人数:', i)
处理返回值的装饰器:
def guess_win(func):
def rooftop_status():
result = func()
print('天台已满,请排队!')
return result
return rooftop_status
@guess_win
def german_team():
print('德国必胜!')
return '赢了会所嫩模!输了下海干活!' #返回值给函数的,print给屏幕的
x = german_team()
print(x)德国必胜!
天台已满,请排队!
赢了会所嫩模!输了下海干活!
处理参数的装饰器:
def guess_win(func):
def rooftop_status(*args, **kwargs):
result = func(*args, **kwargs)
print('天台已满,请排队!')
return result
return rooftop_status
@guess_win
def german_team(arg):
print('{}必胜!'.format(arg))
return '赢了会所嫩模!输了下海干活!'
x = german_team('德国')
y = german_team('西班牙')
print(x)
总结
装饰器的本质是函数,其参数是另一个函数(被装饰的函数)。装饰器通常会额外处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用对象。行为良好的装饰器可以重用,以减少代码量。