Bert改进模型汇总(5)
目录
DistillBert:a distilled version of BERT: smaller, faster, cheaper and lighter
TinyBert:: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING
Reference
DistillBert:a distilled version of BERT: smaller, faster, cheaper and lighter
论文地址 https://arxiv.org/abs/1909.10351
从应用落地的角度来说,bert虽然效果好,但有一个短板就是预训练模型太大,预测时间在平均在300ms以上(一条数据),无法满足业务需求。知识蒸馏是在较低成本下有效提升预测速度的方法。
关于知识蒸馏可以看下这篇文章 https://blog.csdn.net/nature553863/article/details/80568658
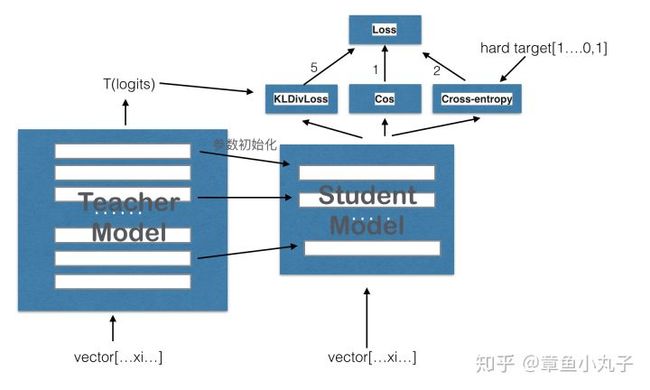
DistillBert是在bert的基础上用知识蒸馏技术训练出来的小型化bert。整体上来说这篇论文还是非常简单的,只是引入了知识蒸馏技术来训练一个小的bert。具体做法如下:
1)给定原始的bert-base作为teacher网络。
2)在bert-base的基础上将网络层数减半(也就是从原来的12层减少到6层)。
3)利用teacher的软标签和teacher的隐层参数来训练student网络。
训练时的损失函数定义为三种损失函数的线性和,三种损失函数分别为:
1)![]() 。这是teacher网络softmax层输出的概率分布和student网络softmax层输出的概率分布的交叉熵(注:MLM任务的输出)。
。这是teacher网络softmax层输出的概率分布和student网络softmax层输出的概率分布的交叉熵(注:MLM任务的输出)。
2)![]() 。这是student网络softmax层输出的概率分布和真实的one-hot标签的交叉熵
。这是student网络softmax层输出的概率分布和真实的one-hot标签的交叉熵
3)![]() 。这是student网络隐层输出和teacher网络隐层输出的余弦相似度值,在上面我们说student的网络层数只有6层,teacher网络的层数有12层,因此个人认为这里在计算该损失的时候是用student的第1层对应teacher的第2层,student的第2层对应teacher的第4层,以此类推。
。这是student网络隐层输出和teacher网络隐层输出的余弦相似度值,在上面我们说student的网络层数只有6层,teacher网络的层数有12层,因此个人认为这里在计算该损失的时候是用student的第1层对应teacher的第2层,student的第2层对应teacher的第4层,以此类推。
整体计算公式为:
Loss= 5.0*Lce+2.0* Lmlm+1.0* Lcos
TinyBert:: DISTILLING BERT FOR NATURAL LANGUAGE UNDERSTANDING
论文地址 https://arxiv.org/abs/1909.10351
TinyBert也是采用了知识蒸馏的方法来压缩模型的,只是在设计上较distillBert做了更多的工作,作者提出了两个点:针对Transformer结构的知识蒸馏和针对pre-training和fine-tuning两阶段的知识蒸馏。
作者在这里构造了四类损失函数来对模型中各层的参数进行约束来训练模型,具体模型结构如下:
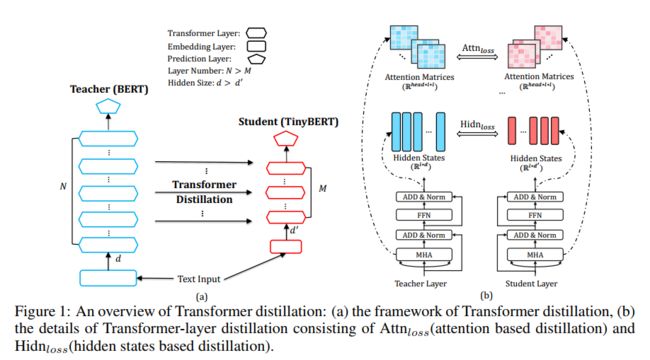
作者构造了四类损失,分别针对embedding layer,attention 权重矩阵,隐层输出,predict layer。可以将这个统一到一个损失函数中:

针对上面四层具体的损失函数表达式如下:

以上四种损失函数是作者针对transformer提出的知识蒸馏方法。除此之外作者认为除了对pre-training蒸馏之外,在fine-tuning时也利用teacher的知识来训练模型可以取得在下游任务更好的效果。因此作者提出了两阶段知识蒸馏,如下图所示:

本质上就是在pre-training蒸馏一个general TinyBERT,然后再在general TinyBERT的基础上利用task-bert上再蒸馏出fine-tuned TinyBERT。
Reference
语义表示模型新方向《DistillBert》
NLP中的预训练语言模型(四)—— 小型化bert(DistillBert, ALBERT, TINYBERT)