大货车燃油盗窃案件管控应用详述
1、项目业务介绍
盗窃大货车燃油基本是深夜凌晨在高速服务区、出入口和路边等地作案。 由于夜间监控模糊,监控被大货车遮挡,同时嫌疑人故意绕开有监控的路 段,导致作案车辆监控抓拍线索非常少。因此,在侦查大货车燃油盗窃案 件时,常常会遇到作案车辆发现难,行车轨迹研判难这到两个难题。
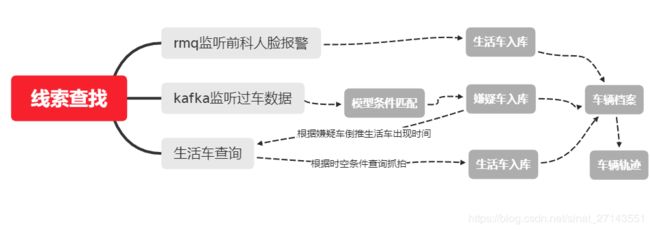
为此我们开发了几种找车的方法:
1、 其次是模型找盗油车,我们根据民警积累的经验开发了一套计算模型,是一些车辆、人员的时空、外观特性信息,每天kafka监听后台大数据过车数据,通过过车数据和业务模型的条件匹配过滤出嫌疑车辆。再以 车辆线索和案件匹配,给用户提供了一种新的、高效的研判思路。
2、 接下来是人脸找相关车,结合用户经验,案件中有大量前科人员作案,这 里主要利用 rabbitMQ监听盗油前科等嫌疑人员人脸名单库布控报警,找出这些人 员出现的地点还有驾乘的车辆信息,为案件提供线索。
4、 最后是规律找生活车,盗油人员的生活规律一般是驾驶生活车辆到盗油车 存放地并驾驶盗油车作案,作案回到盗油车存放点后又驾驶生活车辆回到 居住地。利用该盗油车及生活交替出现的规律,找出盗油人员的生活车辆。通过http接口调用查询车辆轨迹,然后再利 用盗油车和生活车出行轨迹的规律进行分析研判,对明确嫌疑人的身份和 落脚区域起到很大帮助。
2、项目架构
开发使用的技术栈:
spring boot 开发框架、consul注册中心,feign服务调用与项目其他组件通信,ribbon后端负载均衡,postgresql 数据库、kafka 和 rabbit MQ 消息监听,mybatis 数据接入层框架,redis 缓存,xxl-job定时任务,sharding-jdbc分库分表。
部署架构:
Java Web做集群部署,最直接需要注意的应该就是缓存类的共享以及定时任务等的冲突。缓存共享比如session共享、项目中用到的内存缓存等,需要在所有集群内都可以共享到。然后就是一些只需要一个节点执行成功,其他节点不需要重复执行的业务,如定时任务等。
本应用方案为:nginx代理+前端负载均衡;部署两台服务器;kafka,rmq,redis,数据库也都是集群部署;定时任务使用xxl-job,其調度中心集群部署保证高可用。
3、项目亮点
(1)与用户深度沟通,得出细致的业务模型。
(2)创造性的提出利用生活车和盗油车轨迹规律进行案件分析研判的思路。两种车轨迹交点很有可能为落脚点。
4、项目遇到的问题
4.1 kafka 0.10.2.0 消息堆积、重复消费
前提:部署了两台服务器。
问题出现现象:
1.其他订阅的消费者组均能够正常消费,只有本应用出现堆积
2.日志中发现,本应用的两台服务器都在消费
3.日志中还发现,搜索同一车牌号,有很多重复消费日志。
4.查看应用消费日志发现,该类有大量异常日志,是一个数据库异常,因为车牌+过车时间是唯一索引,因此在添加相同车牌时间数据的时候报错了。
5、kafka消费端日志报commitException:
08-09 11:01:11 131 pool-7-thread-3 ERROR [] -
commit failed
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.sendOffsetCommitRequest(ConsumerCoordinator.java:713) ~[MsgAgent-jar-with-dependencies.jar:na]
at org.apache.kafka.clients.consumer.internals.ConsumerCoordinator.commitOffsetsSync(ConsumerCoordinator.java:596) ~[MsgAgent-jar-with-dependencies.jar:na]
at org.apache.kafka.clients.consumer.KafkaConsumer.commitSync(KafkaConsumer.java:1218) ~[MsgAgent-jar-with-dependencies.jar:na]
at com.today.eventbus.common.MsgConsumer.run(MsgConsumer.java:121) ~[MsgAgent-jar-with-dependencies.jar:na]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) [na:1.8.0_161]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) [na:1.8.0_161]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_161]这个错误的意思是,消费者在处理完一批poll的消息后,在同步提交偏移量给broker时报的错。初步分析日志是由于当前消费者线程消费的分区已经被broker给回收了,因为kafka认为这个消费者死了,那么为什么呢?
查阅资料分析推测:
因为一个group只能有一台消费,两台出现消费是否因为出现连接出现问题,重新负载均衡了。
一条记录被循环消费,应该是因为本地提交消费位移失败,才回出现。
这里就涉及到问题是消费者在创建时会有一个属性max.poll.interval.ms,默认为300s,
该属性意思为kafka消费者在每一轮poll()调用之间的最大延迟,消费者在获取更多记录之前可以空闲的时间量的上限。如果此超时时间期满之前poll()没有被再次调用,则消费者被视为失败,并且分组将重新平衡,以便将分区重新分配给别的成员。
public void start(KafkaConsumer consumer, String metadata) {
try {
while (true) {
ConsumerRecords records = consumer.poll(Duration.ofSeconds(2));
if (records != null && !records.isEmpty()) {
log.info("---poll msg success from {} -----", metadata);
process(records);
consumer.commitAsync();
}
}
} catch (Throwable e) {
log.error("consumer exception", e);
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}kafka的偏移量(offset)是由消费者进行管理的,偏移量有两种,拉取偏移量(position)与提交偏移量(committed)。拉取偏移量代表当前消费者分区消费进度。每次消息消费后,需要提交偏移量。在提交偏移量时,kafka会使用拉取偏移量的值作为分区的提交偏移量发送给协调者。
如果没有提交偏移量,下一次消费者重新与broker连接后,会从当前消费者group已提交到broker的偏移量处开始消费。
所以,问题就在这里,当我们处理消息时间太长时,已经被broker剔除,提交偏移量又会报错。所以拉取偏移量没有提交到broker,分区又rebalance。下一次重新分配分区时,消费者会从最新的已提交偏移量处开始消费。这里就出现了重复消费的问题。
问题出现原因:
项目上线时max.poll.interval.ms的配置为300秒,max.poll.records是500
(1)这次问题出现的原因为随着项目推进和成熟,平台接入的抓拍机数量增多,项目初期抓拍机数量为220台,每天抓拍量200-250万之间,峰值抓拍数量为90条/s。条件判断加入库按0.2s计算,由于一批数据一般是500以内,耗时100秒,所以没出现问题。
(2)之后抓拍机数量扩充到5100台,每天抓拍量达到3500万,峰值抓拍数量为1400条/s。消费者线程处理能力赶不上消息的生产能力。消息就像滚雪球一样越来越多,出现消息堆积现象。因此修改max.poll.records为1500, 导致消息一次性poll()到的消息达到1500条,一批数据消费时间为300秒,从而可能会超出max.poll.interval.ms。导致消费者组重平衡,因此连接到另外一台消费服务器,然而另外一台服务器也出现超时,又进行Rebalance...如此循环,才出现了两台服务器都进行消费,并且一直重复消费。
解决办法:
(1)增大max.poll.interval.ms时间为600s,防范峰值流量。
(2) max.poll.records默认是500,减少该值也能解决这个问题,但是会造成消息堆积。
(3)批量入库,缩短单批次消息处理时间。
之前是每条记录走两次查询是否是被盗车和套牌车接口,入库一次
现在被盗车和套牌车信息放入redis缓存并定时更新,一批次消息统一入库一次。
(4)增加消费者线程数量
每台服务器开启2个消费者线程。一共两台服务器、4个消费者线程,同时增加两个分区使分区数量等于消费者数量。
(5)另外,发现平台的kafka broker和consumer client版本不一致也会导致性能下降:Producer、Consumer 和 Broker 的版本是相同的,它们之间的通信可以享受 Zero Copy 的快速通道;相反,一个低版本的 Consumer 程序想要与 Producer、Broker 交互的话,就只能依靠 JVM 堆中转一下,丢掉了快捷通道,就只能走慢速通道了。因此,在优化 Broker 这一层时,你只要保持服务器端和客户端版本的一致,就能获得很多性能收益了。
效果:
省去了绝大部分接口调用和数据库读写阻塞时间,处理一批记录耗时700-800ms,单个消费者平均每秒处理700条数据。3个消费者实例即能够抵御当前流量冲击。
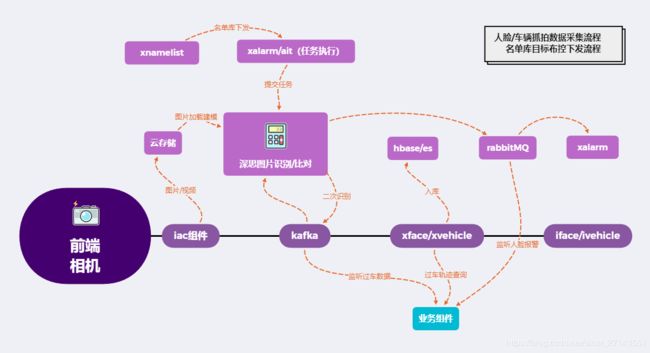
流程:人脸/车辆抓拍数据获取流程、名单库布控流程
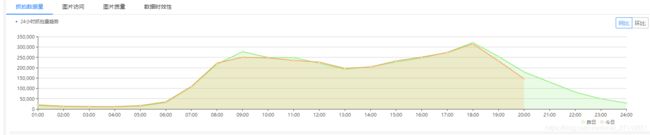
过车抓拍量统计:
(1)项目刚投入使用时:

(2)项目成熟时