Storm解读之路(二、基本 Java-API 篇)
写这些东西其实本质上是记录因工作接触 Storm 之后的学习进度,既然是工作,当然要敲代码,所以这一篇就分享下基本 Java-API 吧。
首先看下面的图(画图不行见谅),这是 Storm API 使用中最基本的接口和抽象类关系。
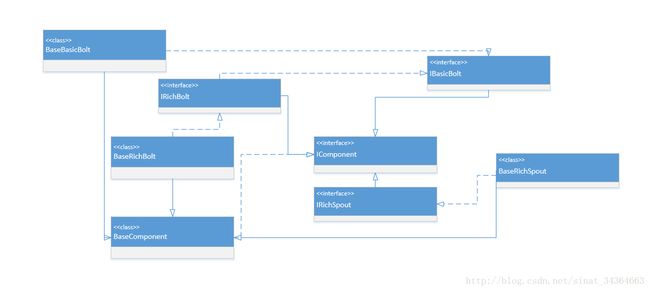
OK,这里我们可以清楚的看到,IComponent 是 API 核心接口,那么其是怎么的构成呢?
public interface IComponent extends Serializable {
/**
* @param declarer this is used to declare output stream ids, output fields, and whether or not each output stream is a direct stream
*/
void declareOutputFields(OutputFieldsDeclarer declarer);
Map getComponentConfiguration();
}
这两个方法很简单,declareOutputFields 是申明 topology 中流的输出模式(具体讲 Stream 模式的时候再说),而 getComponentConfiguration 是获取 Storm 配置信息的。
其实在 Visio 图中是有两个基础接口我没画出来的,分别是 ISpout 和 Ibolt,为什么呢?因为我们可以理解为 IRichSpout 和 IRichBolt 就是两者与 IComponent 的合体(继承)。接着一个个来,先说 Spout:
void open(Map conf, TopologyContext context, SpoutOutputCollector collector);
//Spout 终止的时候调用(不保证一定被调用)
void close();
//Spout 激活的时候调用
void activate();
//Spout 失活(可能重新激活)时调用,调用此方法时不会调用 nextTuple
void deactivate();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);简单容易理解的方法在这里就不提了(做了注释),说一下比较重要的方法。
先说 open,当 Spout 初始化的那时候调用,一共接收了三个对象,一个配置对象、一个 Topology 上下文对象,还有一个 输出控制器对象。重点提一下 SpoutOutputCollector 这个类,这个是控制整个 Spout 关于元组传输的类,很重要,主要关注下面几个方法:
List<Integer> emit(String streamId, List<Object> tuple, Object messageId);
void emitDirect(int taskId, String streamId, List<Object> tuple, Object messageId);
long getPendingCount();前两个方法,都是将 tuple 提交到 stream 中去的,区别在于后者是定向提交的。其可以传递参数
int taskId, String streamId, List<Object> tuple, Object messageId前三个参数分别的意义就是字面上意思(论取名的规范性),而 messageId 是作锚定所用(之后谈)的。
然后说下 nextTuple 方法,这是个 non-blocking 的方法,也就是说当没有 tuple 来 emit 的时候,其是立即返回的(非阻塞的)。好像 Storm 是在 0.8.1 版本之后 emit 空的话 nextTuple 就默认 sleep 1秒钟(可配置,SleepSpoutWaitStrategy 接口),主要为了 cpu 资源的合理分配。总之你的 topology 活着(除了某些特例情况),你的 nextTuple 方法就是不断被调用的,一直请求 tuple,一般我们也在这里调用 SpoutOutputCollector 对象的 emit 方法发送数据。
最后说下 ack、fail 方法,连带 messageId 一起提。讲之前先说下,Storm Spout 的 nextTuple、ack、fail 好像是一个线程的,所以才设计为非阻塞模式,具体底层我也看不了,哎(据说 JStorm 是分了多线程的)。所以可以根据实际情况把 nextTuple 的业务线程单出来。OK,回归正题,ack 方法是 Storm 锚定机制,要说简单点的话可以这要讲:Spout emit 一个 tuple,如果携带了 messageId(别告诉我你忘记这东西了),这个 tuple 的传递过程就将被追踪,一直到其发送成功或者失败调用 fail 方法。关于 fail 方法,默认是 tuple 失败后重新进入 queue,重发。具体的重发配置我还没研究,有研究的朋友可以交流下,另外 getPendingCount 方法我也没搞懂什么作用,懂的朋友一样欢迎指教,开源万岁!
Spout 讲完接着咱说 Bolt,老样子,先看看源码
void prepare(Map stormConf, TopologyContext context, OutputCollector collector);
void execute(Tuple input);
//Bolt 终止时调用(不保证一定被调用)
void cleanup();
同 Spout,cleanup 就不解释了,这里说说 prepare 和 execute。先说 prepare 方法:
这是 Bolt 的初始化方法,三个对象和 Spout 不一样的只有 OutputCollector:
List<Integer> emit(String streamId, Collection<Tuple> anchors, List<Object> tuple);
void emitDirect(int taskId, String streamId, Collection<Tuple> anchors, List<Object> tuple);
void ack(Tuple input);
void fail(Tuple input);
void resetTimeout(Tuple input);
其实也 OutputCollector 只是把 ack 和 fail 方法囊括进去了,多了个超时重置配置,用法和 SpoutOutputCollector 基本相同。
然后重点看的是 execute 方法,这是个用作逻辑处理方法,你可以在这里取得从 Spout 传递过来的 tuple,然后在 execute 中对其作你需要的业务实现。当然,如果你还想要向下继续传输你的 tuple,那就得调用你在 prepare 方法中初始化好的 OutputCollector 对象,emit 你的 tuple(至于是否锚定还是看业务是否注重数据可靠)。
刚发现漏了说个重要的东西,Tuple,嗨呀好气啊,补上补上:
Tuple 这个类,包含了你要传输的元组元信息、内容以及操作方法,继承自 ITuple,以下放一些方法(实在太多)
public GlobalStreamId getSourceGlobalStreamId();
public String getSourceComponent();
public int getSourceTask();
public MessageId getMessageId();
/**
* 判断 tuple 是否包含该命名的 field
*/
public boolean contains(String field);
/**
* 通过位置参数返回 tuples 的 field(动态类型)
*/
public Object getValue(int i);
/**
* 通过位置参数返回 tuples 的 field(String 类型)
*/
public String getString(int i);
/**
* 通过命名返回 tuples 的 field(String 类型)
*/
public String getStringByField(String field);这里只是 Tuple 的一部分方法,很多实现其实都大同小异,可以返回各种上下文信息,可以通过 tuples 的位置和命名(具体讲 Stream 模式的时候再说)返回动态或已知类型的 field,也就是你传递的实际数据,顺便说下,所谓 Value 其实就是个封装 ArrayList 的类
public class Values extends ArrayList<Object>{
public Values() {
}
public Values(Object... vals) {
super(vals.length);
for(Object o: vals) {
add(o);
}
}
}
那么 Spout 和 Bolt 基本的 API 接口分析就到这里,接着说一个 Bolt 的扩展接口 IBasicBolt
public interface IBasicBolt extends IComponent {
void prepare(Map stormConf, TopologyContext context);
void execute(Tuple input, BasicOutputCollector collector);
void cleanup();
}
其实之前看懂了朋友这里应该是很容易看明白的,BasicOutputCollector,这就是关键
public interface IBasicOutputCollector extends IErrorReporter{
List emit(String streamId, List IBasicOutputCollector 自己帮助你实现了 ack 机制的 emit,不需要你自己去写,对于一些要求可靠性而且不复杂的业务 IBasicBolt 非常实用。
OK,本篇就到这里,抽象类这里我就不说了(没啥说的)。其实 Spout 和 Bolt 的 API 还有一些功能性的封装,像 ITransactionSpout、KafkaSpout之类的(本次项目时所用),各位可以自己去查看源码,其实同样是我说道的这些方法加上其各自的功能点,最多实现逻辑复杂些,还是能看明白的。