自然语言理解发展历程
(一)、NLP四大类任务:
1.序列标注:这是最典型的 NLP 任务,比如中文分词,词性标注,命名实体识别,语义角色标注等都可以归入这一类问题,它的特点是句子中每个单词要求模型根据上下文都要给出一个分类类别。
2.分类任务:比如我们常见的文本分类,情感计算等都可以归入这一类。它的特点是不管文章有多长,总体给出一个分类类别即可。
3.句子关系判断:比如 QA,语义改写,自然语言推理等任务都是这个模式,它的特点是给定两个句子,模型判断出两个句子是否具备某种语义关系。
4.生成式任务:比如机器翻译,文本摘要,写诗造句,对对联,看图说话等都属于这一类。它的特点是输入文本内容后,需要自主生成另外一段文字。
(二)、NLP算法发展史
1. NNLM(Neural Network language model):
简述:通过多个上文输入,预测输出,应用了word Embedding方法,但是此word Embedding是没有上下文的word Embedding,也就是word直接用one-hot表示,然后乘以一个向量权重矩阵(这个向量矩阵其实就是word Embedding向量矩阵,是我们训练得到的)得到该word的word Embedding向量。
实现功能:将上文的t-1个词输入,预测第t个词
网络结构:将前t-1个词的one-hot编码向量输入网络,分别乘以一个共享的word Embedding向量矩阵C,得到t-1个word Embedding向量,然后将t-1个向量进行concat,然后经过激活函数tanh激活后,输入到softmax层进行概率预测。
NNLM模型图如下:
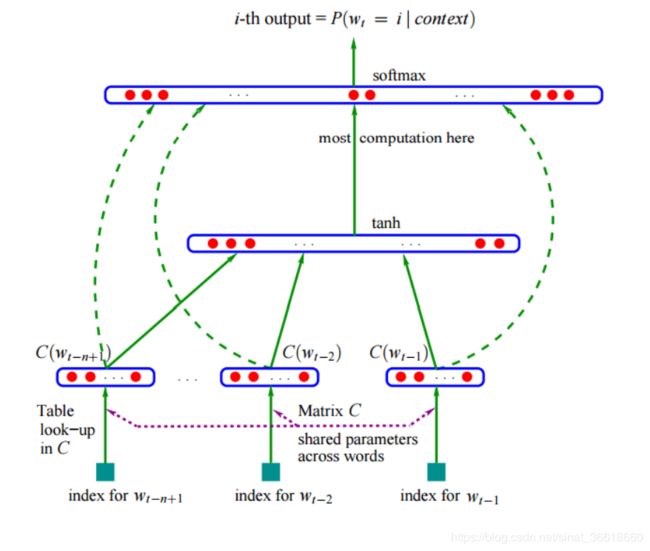
缺点:NNLM所求解的word Embedding矩阵C没有包含上下文的信息,只是一个独立的个体。
2. word2vec:
简述:引入了基于上下文的word Embedding,即用上文的单词和下文的单词共同预测文中单词(cbow),或者是用文中单词来预测上文以及下文的单词(Skip-gram),从而训练出一个包含所有词的word Embedding向量矩阵(如:在下图中,cbow中的以及Skip-gram中的w(t)就是我们训练出的word Embdding向量)
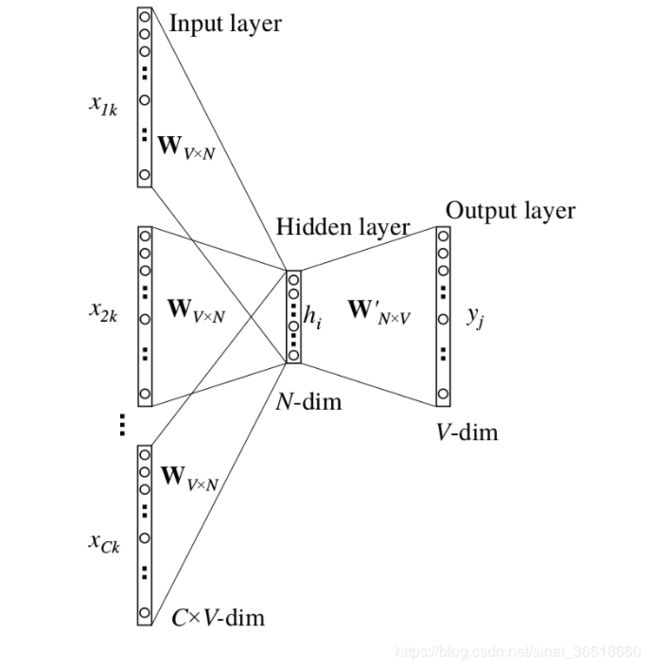
CBOW模型(Continuous Bag of Words)和Skip-gram模型如下图:

实现功能:训练一个word Embedding权重向量矩阵
网络结构:上图中将x(t)的上文单词x(1)、x(2)…x(t-1)以及下文单词x(t+1)、x(t+2)…输入到网络中训练隐藏层(hidden layer)的x(t)的word Embdding向量,最终我们所需要的权重矩阵是网络中输入层到隐藏层的权重矩阵,隐藏层到输出层的权重矩阵只是我们用来训练前面的权重矩阵的,在大样本,海量数据文本训练的过程中,就能训练出每个word的Embedding向量(也就是hidded layer的向量),将所有的word Embedding向量组合就是一个word Embedding向量矩阵,也就是我们常用的word Embedding表
CBOW模型具体结构:
缺点: word2vec计算的word Embedding向量,无法区分多义词的不同语义,在什么语义下的word Embedding向量都表示相同。
3. Seq2Seq:
简述:Seq2Seq模型的核心思想,通过深度神经网络将一个定长(零填充机制实现定长)的输入序列信号转换为输出的序列信号,这一过程由编码和解码两个过程构成。在经典的实现中,编码器和解码器各由一个循环神经网络(RNN,LSTM,GRU均可)构成,在Seq2Seq中,两个循环神经网络是共同训练的(具体见:Seq2Seq模型)
实现功能:实现了将一个序列信号转化成一个不定长的序列输出
网络结构:由编码器(Encoder)和解码器(Decoder)组成,Encoder是个GRU(或者是RNN和LSTM),它会遍历输入的每一个word(词),每个时刻的输入是上一个时刻的隐状态和输入,然后会有一个输出和新的隐状态。这个新的隐状态会作为下一个时刻的输入隐状态。每个时刻都有一个隐状态输出,对于Seq2Seq模型来说,我们通常只保留最后一个时刻的隐状态,认为它编码了整个句子的语义,但是后面我们会用到Attention机制,它还会用到Encoder每个时刻隐状态的输出。Encoder处理结束后会把最后一个时刻的隐状态作为Decoder的初始隐状态。
Seq2Seq模型如下:
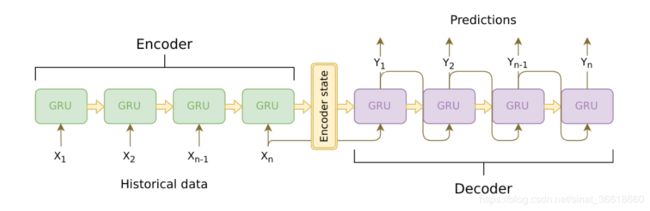
注意力机制的提出:解决了Seq2Seq的两个缺陷,即难以记忆长句子,压缩损失信息.
添加注意力机制的Seq2Seq:
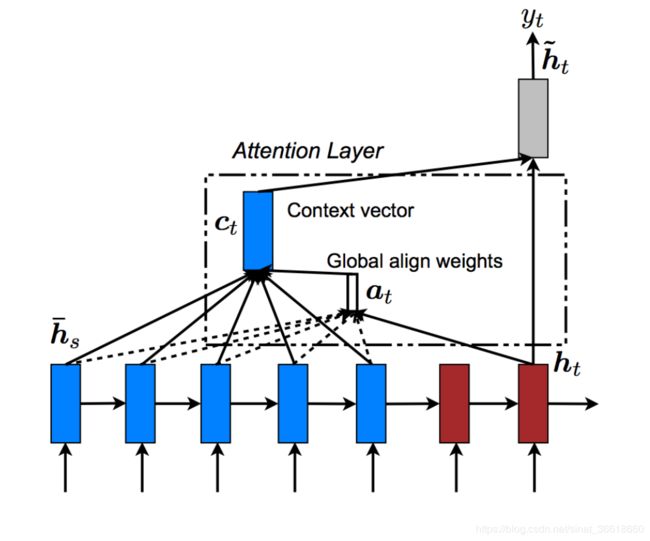
计算过程:Decoder层输出的隐藏层状态与Encoder所有隐藏层状态作点积得到的结果,进行softmax,然后将softmax的结果与Encoder所有隐藏层状态做乘法,并将结果相加,所得到的注意力权重再与原隐藏状态concat,再将所得到的注意力状态与输入一起预测(训练)输出。
4. ELMO(Embedding from language model):
简述:使用了双向LSTM(RNN或者GRU)进行训练,ELMO 的预训练过程不仅仅学会单词的 Word Embedding,还学会了一个双层双向的 LSTM 网络结构。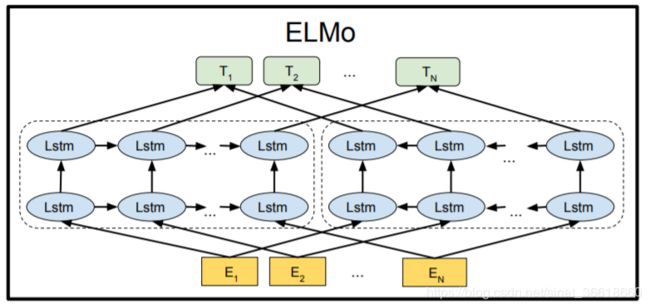
改进:解决了多义词问题
缺点:LSTM抽取特征能力不够强
5. openAI GPT(Generative Pre-Training):
简述:第一个阶段是利用语言模型进行预训练,第二阶段通过 Fine-tuning 的模式解决下游任务,使用了单向Transformer来进行训练,即只采用 上文来进行预测,而抛开了下文。
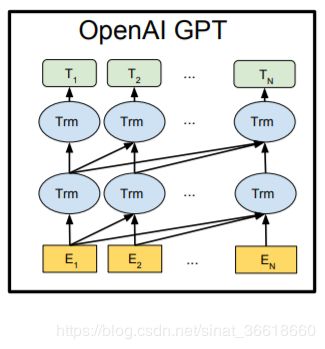
优点:使用Transformer作为特征抽取器,Transformer特征抽取能力明显强于LSTM。
缺点:使用了单向的语言模型,即只考虑了上文,没有考虑下文。
6. BERT(Bidirectional Encoder Representations from Transformers):
简述:Bert 采用和 GPT 完全相同的两阶段模型,首先是语言模型预训练;其次是使Fine-Tuning 模式解决下游任务。和 GPT 的最主要不同在于在预训练阶段采用Transformer的双向语言模型。
BERT的输入表示如下图:
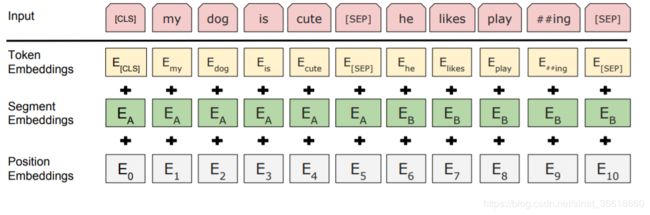
BERT在不同任务上的Fine-tuning:
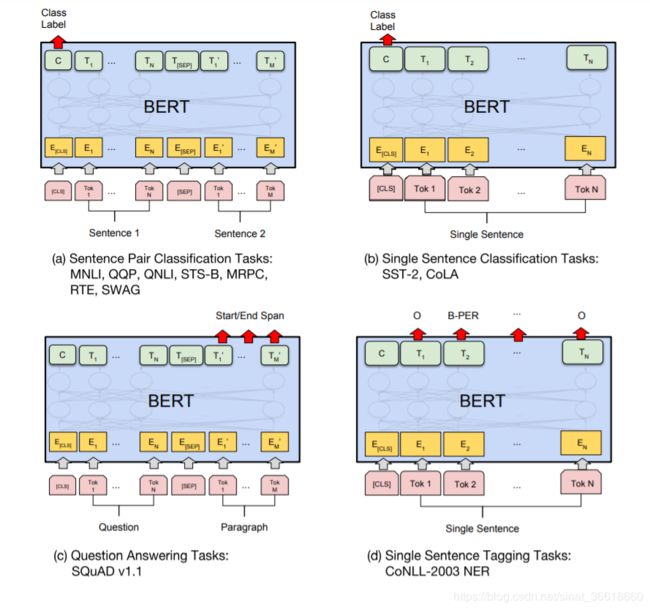
如上述a,b,c,d四图所示,通过Fine-tuning,bert可实现以下不同的四类任务:
a.句子关系分类:是否连续,二分类问题,需加上一个起始和终结符号,句子之间加个分隔符即可
b.单句分类:可以看成是文本分类任务,多分类问题,需增加起始和终结符号,输出部分和句子关系判断任务类似改造
c.问答系统:可以附着在 Seq2Seq 结构上,Encoder 部分是个深度 Transformer 结构,Decoder 部分也是个深度 Transformer 结构。根据任务选择不同的预训练数据初始化 Encoder 和 Decoder 即可
d.序列标注:输入部分和单句分类是一样的,只需要输出部分 Transformer 最后一层每个单词对应位置都进行分类即可
改进:使用双向的Transformer、Masked LM以及句子级预测(Next Sentence Prediction)
优点:几乎可以做任何 NLP 的下游任务,具备普适性