python+appium爬取微信运动数据,并分析好友的日常步数情况
python+appium爬取微信运动数据,并分析好友的日常步数情况
声明:仅供技术交流,请勿用于非法用途,如有其它非法用途造成损失,和本博客无关
目录
- python+appium爬取微信运动数据,并分析好友的日常步数情况
- 前言
- 一、准备
- 二、爬取数据
- 思维导图(爬取逻辑)
- 第一步:连接手机
- 第二步:元素定位
- 第三步:编写代码
- 三、数据分析
- 第一步、数据预处理
- 第二步、数据探索性分析
- 第三步、数据可视化
- 第四步、结论
- 写在最后
前言
- 微信运动只能看到前30天的数据,超过的会过期而拿不到,我也是现在才知道的。本来还想拿多一点数据的哈哈。(不信你去试试)
- 本次爬取使用的是
appium,因为是完全模拟人的操作,所以耗时由您好友数量决定。(我200左右的微信好友,其中130+个人开启了微信运动,耗时半个钟,基本上一分钟拿到一天的数据) - 最好先给您的好友都备注好,并且名字最好不要超过8个字好像,因为超过之后会显示不全,最后那几个字会省略为点点点,强迫症看着就很烦你懂的
废话不多说,直接开始
一、准备
appium:一个类似于selenium的自动化工具,很多操作也很相像。(这个安装网上有很多教程,亲测确实是很麻烦,不过安装好之后简直是一劳永逸呀)Appium-python-Client:这个是python第三方库,通过它写python代码来操作appium的,直接用pip命令安装即可jupyter notebook:这次推荐使用这个编译器。(后面的数据分析会用到,很友好,很完美,相信你也会爱上她的hiahiahia~)- 一部手机:这个没有的话,用安卓模拟器应该也行。推荐直接上真机就好了
二、爬取数据
思维导图(爬取逻辑)

第一步:连接手机
我这里连接了我自己的真机,安卓模拟器我没装不清楚具体细节请谅解。用USB将电脑和手机连上后,首先要打开手机的USB调试,大致都在:设置——>开发者选项——>开启USB调试
appium的教程网上也都能找得到,也不难,基本上会selenium的都能一下子学会appium。而appium会依赖Android环境,那么这里给出两个要用到的adb命令:
- 查看包名和界面名(package&activity)
linux/mac
adb shell dumpsys window windows | grep mFocusedApp
windows
adb shell dumpsys window windows | findstr mFocusedApp
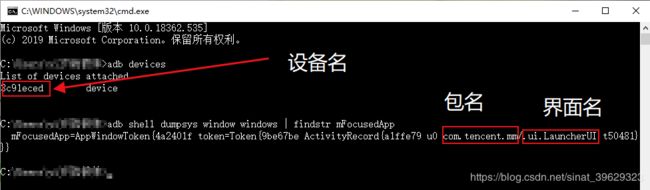
- 获取当前电脑已经连接的设备和对应的设备名
adb devices
然后在cmd中输入上述命令获取手机的设备名、再者进入微信,输入命令获取包名和界面名。(好像不同手机不同版本的包名和界面名会有所差异)
第二步:元素定位
我这里用的查找元素定位工具是安装Android SDK自带的uiautomatorviewer工具。具体在你安装的Android SDK目录下:tools目录——>uiautomatorviewer.bat
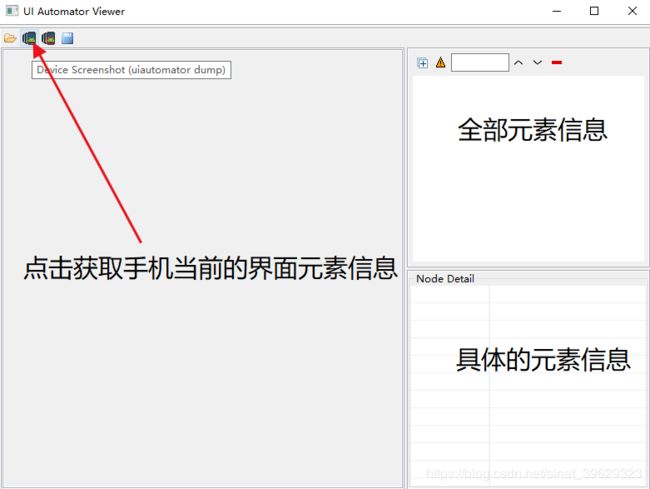
元素主要是通过resource-id标签来定位,用到的主要是xpath语句,具体定位内容请看代码。
好像不同手机不同版本的resource-id也会有所差异,所以尽量不要复制代码直接运行哈,自己动手丰衣足食。
第三步:编写代码
运行代码前的准备:自己先打开微信,然后进入消息的页面,并把微信运动置顶,这样是为了减少不必要的操作。
ps:详情讲解请看代码和代码注释
from appium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from appium.webdriver.common.touch_action import TouchAction
import parsel #解析页面
import datetime
import time
def crawl(desired_caps,date_out):
driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_caps)
wait=WebDriverWait(driver,20,4) #设置显示等待,即在20秒的时间内,每隔4秒找一次元素,这个按需更改
TouchAction(driver).tap(element=wait.until(lambda x : x.find_element_by_xpath('//*[@text="微信运动"]'))).perform()
data={} #存储每个排行榜的信息
num=0 #给日期计数
sj=int(time.time()) #记录开始爬取数据开始的时间
while True:
start_time=int(time.time()) #记录本次爬取开始的时间
up_el=driver.find_elements_by_id('com.tencent.mm:id/ai')[0] #捕获上一个排行榜时间的元素
low_el=driver.find_elements_by_id('com.tencent.mm:id/ai')[1] #捕获当前排行榜时间的元素
if num != 0:
driver.drag_and_drop(up_el,low_el) #拖动上一个元素的位置到当前元素的位置
date=(datetime.datetime.now()-datetime.timedelta(days=1+num)).strftime("%Y-%m-%d")
name_list=[] #存储姓名
run_count_list=[] #存储步数
like_list=[] #存储点赞数
flag=1 #因为自己总是会出现在第一位,所以第一次滑要排除自己
if date_out not in low_el.text:
now=driver.find_elements_by_id('com.tencent.mm:id/atb')[2]
TouchAction(driver).tap(element=now).perform() #点击进入当前排行榜
while True:
if driver.find_elements_by_xpath('//*[@text="邀请朋友"]') == []: #判断是否到底端了
driver.swipe(480,1500,480,700,duration=2000) #这个也按你们实际情况来更改坐标吧,只要第一次滑完的时候要看到第一名的信息
response=parsel.Selector(driver.page_source)
if flag == 1:
people=response.xpath('//*[@resource-id="com.tencent.mm:id/om"]')[1:] #第一次排除自己
else:
people=response.xpath('//*[@resource-id="com.tencent.mm:id/om"]')
for eachone in people:
flag=0
name=eachone.xpath('.//*[@resource-id="com.tencent.mm:id/brk"]/@text').get() #注意这里用的是@text,而不是/text,之前我在这里都快绝望了,一直拿不到text的内容,最后给蒙出来了哈哈
run_count=eachone.xpath('.//*[@resource-id="com.tencent.mm:id/bq8"]/@text').get()
like=eachone.xpath('.//*[@resource-id="com.tencent.mm:id/bpy"]/@text').get()
if (name not in name_list)and(name is not None):
temp=[] #存储步数和点赞数
name_list.append(name)
temp.append(run_count)
temp.append(like)
run_count_list.append(temp)
item=dict(zip(name_list,run_count_list))
data.update({date:item})
else:
break
print(f'{date},有{len(name_list)}个好友开启了他们的微信运动。本轮耗时:{int(time.time())-start_time}秒')
num+=1
driver.back() #返回
else:
print(f'再往后消息已过期。总耗时:{int(time.time())-sj}秒')
break
driver.quit() #退出
return data
def save_data(data):
json_str = json.dumps(data, indent=4,ensure_ascii=False)
with open('data.json', 'w', encoding='utf-8') as f:
f.write(json_str)
def main(desired_caps,date_out):
# 爬取数据
data=crawl(desired_caps,date_out)
# 保存数据
save_data(data)
if __name__ == '__main__':
desired_caps={
'platformName': 'Android', #操作系统
'deviceName': '3c91eced', #设备名
'platformVersion': '6.0.1', #版本号
'appPackage': 'com.tencent.mm', #包名
'appActivity': 'com.tencent.mm.ui.LauncherUI' #界面名
}
main(desired_caps,date_out='12月12日') #我的是12月12日之前的都已过期,你们按实际时间来更改这个日期就行
运行完之后呢,会在当前目录下生成一个data.json的文件,这就是爬下来的全部数据啦
输出如下:
2020-01-10,有135个好友开启了他们的微信运动。本轮耗时:59秒
2020-01-09,有135个好友开启了他们的微信运动。本轮耗时:61秒
2020-01-08,有135个好友开启了他们的微信运动。本轮耗时:62秒
2020-01-07,有134个好友开启了他们的微信运动。本轮耗时:61秒
2020-01-06,有134个好友开启了他们的微信运动。本轮耗时:62秒
2020-01-05,有132个好友开启了他们的微信运动。本轮耗时:60秒
2020-01-04,有133个好友开启了他们的微信运动。本轮耗时:60秒
2020-01-03,有133个好友开启了他们的微信运动。本轮耗时:60秒
2020-01-02,有132个好友开启了他们的微信运动。本轮耗时:60秒
2020-01-01,有134个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-31,有134个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-30,有133个好友开启了他们的微信运动。本轮耗时:59秒
2019-12-29,有134个好友开启了他们的微信运动。本轮耗时:60秒
2019-12-28,有135个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-27,有135个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-26,有134个好友开启了他们的微信运动。本轮耗时:61秒
2019-12-25,有135个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-24,有135个好友开启了他们的微信运动。本轮耗时:61秒
2019-12-23,有134个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-22,有135个好友开启了他们的微信运动。本轮耗时:63秒
2019-12-21,有136个好友开启了他们的微信运动。本轮耗时:77秒
2019-12-20,有133个好友开启了他们的微信运动。本轮耗时:68秒
2019-12-19,有134个好友开启了他们的微信运动。本轮耗时:64秒
2019-12-18,有134个好友开启了他们的微信运动。本轮耗时:64秒
2019-12-17,有133个好友开启了他们的微信运动。本轮耗时:63秒
2019-12-16,有133个好友开启了他们的微信运动。本轮耗时:61秒
2019-12-15,有133个好友开启了他们的微信运动。本轮耗时:62秒
2019-12-14,有134个好友开启了他们的微信运动。本轮耗时:63秒
2019-12-13,有135个好友开启了他们的微信运动。本轮耗时:63秒
再往后消息已过期。总耗时:1819秒
三、数据分析
首先先加载刚刚爬取到的数据和导入所需要的库,以及设定一些默认的配置
import pandas as pd
import random
import json
import os
import matplotlib.pyplot as plt #画图工具
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] #黑体(显示中文)
plt.rcParams['font.size'] = 20 #字体大小
#加载json数据
with open('data.json','r',encoding='utf-8') as f:
data=json.load(f)
第一步、数据预处理
预处理主要是剔除异常值、空值、重复值等等,可是我觉得在这里,我并不想剔除这些数据,因为可以从这里看出哪些人什么时候开启了微信运动,什么时候关闭了它,还有空值的话也可能是因为他没有打开过微信甚至可能根本没有上过网玩过手机都有可能。还有一种可能是找出他/她哪一天屏蔽了你的微信运动哈哈。
所以我这里就不做数据处理了,直接全部套用就ok

第二步、数据探索性分析
ps:考虑到隐私的问题,以下的图片均已打码
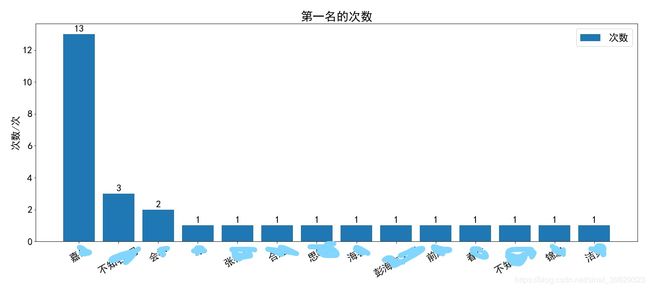
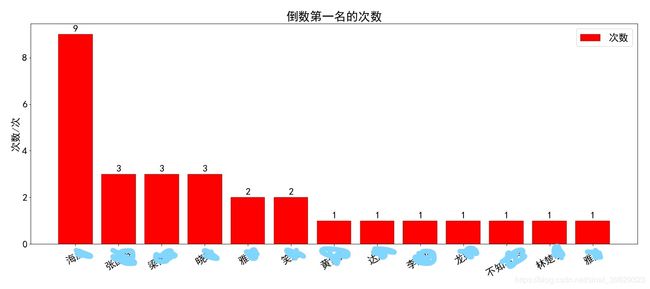
- 康康第一名和倒数第一名都有谁
one=[]
for i in list(data.keys()):
print('{},第一名:{}'.format(i,list(data[i].keys())[0]))
one.append(list(data[i].keys())[0])
df=pd.DataFrame([one]).T
df.columns=['第一名']
df.index=list(data.keys())
print('获得第一名的次数:')
print(df['第一名'].value_counts())
daoshu_one=[]
for i in list(data.keys()):
print('{},倒数第一名:{}'.format(i,list(data[i].keys())[-1]))
daoshu_one.append(list(data[i].keys())[-1])
df['倒数第一名']=daoshu_one
print('获得倒数第一名的次数:')
print(df['倒数第一名'].value_counts())
输出如下:




- 康康前十名和倒数前十名都有谁
ten=[]
all_ten=[]
for i in list(data.keys()):
print('{},前十名:{}'.format(i,list(data[i].keys())[:10]))
ten.append(list(data[i].keys())[:10])
all_ten+=list(data[i].keys())[:10]
df['前十名']=ten
df_ten=pd.DataFrame([all_ten]).T
df_ten.columns=['前十名的次数']
print('获得前十名的次数:')
print(df_ten['前十名的次数'].value_counts())
daoshu_ten=[]
all_daoshu_ten=[]
for i in list(data.keys()):
print('{},倒数前十名:{}'.format(i,list(data[i].keys())[-10:]))
daoshu_ten.append(list(data[i].keys())[-10:])
all_daoshu_ten+=list(data[i].keys())[-10:]
df['倒数前十名']=daoshu_ten
df_daoshu_ten=pd.DataFrame([all_daoshu_ten]).T
df_daoshu_ten.columns=['倒数前十名的次数']
print('获得倒数前十名的次数:')
print(df_daoshu_ten['倒数前十名的次数'].value_counts())
ps:由于边幅有限,这个就不上传输出了,跟第一名和倒数第一名的输出差不多,有兴趣自己运行看看吧
第三步、数据可视化
- 先可视化前面两个
下面这个函数的用处是将柱状图中的每根柱子标上对应的数值,后面很多操作都用到这个函数,所以我把它单独拿了出来
def autolabel(rects):
for rect in rects:
height = rect.get_height()
plt.annotate('{}'.format(height),
xy=(rect.get_x() + rect.get_width() / 2, height),
xytext=(0,3), # 3 points vertical offset
textcoords="offset points",
ha='center', va='bottom')
name=df['第一名'].value_counts().index
one_count=df['第一名'].value_counts().values
plt.figure(figsize=(18,8))
a=plt.bar(name,one_count,label='次数')
plt.ylabel('次数/次')
plt.tick_params(axis='x', rotation=30)
plt.title('第一名的次数')
autolabel(a)
plt.legend()
plt.tight_layout()
plt.savefig('第一名的次数.jpg')
plt.show()
name=df['倒数第一名'].value_counts().index
daoshu_one_count=df['倒数第一名'].value_counts().values
plt.figure(figsize=(18,8))
a=plt.bar(name,daoshu_one_count,color='red',label='次数')
plt.ylabel('次数/次')
plt.tick_params(axis='x', rotation=30)
plt.title('倒数第一名的次数')
autolabel(a)
plt.legend()
plt.tight_layout()
plt.savefig('倒数第一名的次数.jpg')
plt.show()
name=df_ten['前十名的次数'].value_counts().index[:20]
ten_count=df_ten['前十名的次数'].value_counts().values[:20]
plt.figure(figsize=(18,8))
a=plt.bar(name,ten_count,label='次数')
plt.ylabel('次数/次')
plt.tick_params(axis='x', rotation=30)
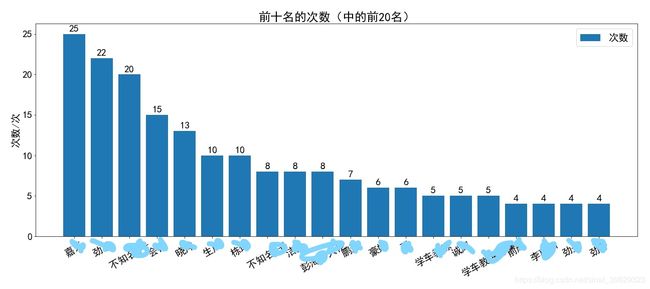
plt.title('前十名的次数(中的前20名)')
autolabel(a)
plt.legend()
plt.tight_layout()
plt.savefig('前十名的次数(中的前20名).jpg')
plt.show()
name=df_daoshu_ten['倒数前十名的次数'].value_counts().index[:20]
daoshu_ten_count=df_daoshu_ten['倒数前十名的次数'].value_counts().values[:20]
plt.figure(figsize=(18,8))
a=plt.bar(name,daoshu_ten_count,color='red',label='次数')
plt.ylabel('次数/次')
plt.tick_params(axis='x', rotation=30)
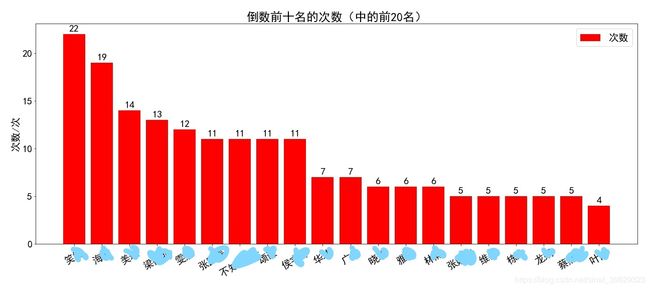
plt.title('倒数前十名的次数(中的前20名)')
autolabel(a)
plt.legend()
plt.tight_layout()
plt.savefig('倒数前十名的次数(中的前20名).jpg')
plt.show()
输出如下:
- 个人步数趋势可视化
def everyone_plot(name):
run_count_list=[] #存储步数
like_list=[] # 存储点赞数
for i in list(data.keys())[::-1]:
if data[i].get(name) is not None:
run_count=int(data[i].get(name)[0])
run_count_list.append(run_count)
like_list.append(int(data[i].get(name)[1]))
else:
run_count_list.append(0)
like_list.append(0)
plt.figure(figsize=(18,8))
plt.plot(list(data.keys())[::-1],run_count_list,label='步数',linewidth=2,color='blue',marker='o',markerfacecolor='red',markersize=8)
plt.tick_params(axis='x', rotation=70)
plt.ylabel('步数/步')
plt.title(f'{name}的个人运动趋势')
low=-1000 if min(run_count_list) < 1000 else 250
high=max(run_count_list)+max(run_count_list)/2
plt.ylim(low,high)
plt.grid(True)
for x,y in zip(list(data.keys())[::-1],run_count_list):
plt.text(x, y, y, ha='center', va='bottom', fontsize=18)
for i,(x,y) in enumerate(zip(list(data.keys())[::-1],run_count_list)):
if like_list[i] != 0:
plt.text(x, low,f'{like_list[i]}赞', ha='center', va='bottom', fontsize=18)
plt.legend()
plt.tight_layout() #铺满整个画布
plt.savefig(f'./personal/{name}.jpg')
plt.show()
if __name__ == '__main__':
if not os.path.exists('./personal'):
os.makedirs('./personal')
all_name=[] #存储这些数据里面出现过的所有人的姓名
for i in list(data.keys()):
all_name+=list(data[i].keys())
all_name=list(set(all_name)) #集合去重法
for i in range(len(all_name)):
eachone=random.choice(all_name)
all_name.remove(eachone)
everyone_plot(eachone)
这里保存和输出了所有人的这30天以来的运动趋势情况,图片有点多,就不一一列出来了,下面就随便展示一个吧
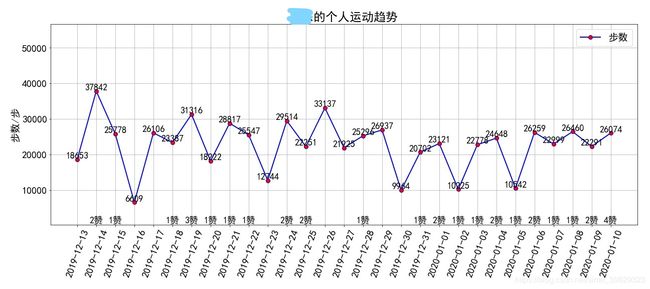
- 比较两个或多个人的运动趋势
def compare_plot(names,flag=True): #flag判断是否需要标上数值
plt.figure(figsize=(18,8))
for name in names: #通过循环画出传进来的每个人的运动趋势
run_count_list=[]
like_list=[]
for i in list(data.keys())[::-1]:
if data[i].get(name) is not None:
run_count=int(data[i].get(name)[0])
run_count_list.append(run_count)
like_list.append(int(data[i].get(name)[1]))
else:
run_count_list.append(0)
like_list.append(0)
plt.plot(list(data.keys())[::-1],run_count_list,label=name,linewidth=2,marker='o',markersize=6)
if flag:
for x,y in zip(list(data.keys())[::-1],run_count_list):
plt.text(x, y, y, ha='center', va='bottom', fontsize=18)
plt.tick_params(axis='x', rotation=70)
plt.ylabel('步数/步')
plt.title(f'{len(names)}个人之间的比较')
plt.grid(True)
plt.legend()
plt.tight_layout()
plt.savefig(f'{len(names)}个人之间的比较.jpg')
plt.show()
if __name__ == '__main__':
compare_plot(['好友A名字','好友B名字'],flag=True)
下面我也随机找两个好友进行比较了一下,输出如下:
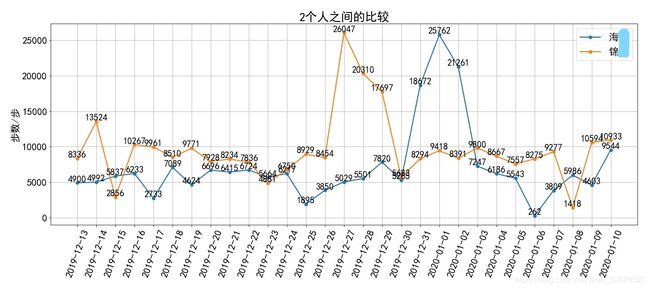
第四步、结论
-
通过观察第一名和倒数第一名、前十名和倒数前十名,并且看到了谁占的次数最多,大致可以猜出这些好友每天的运动即行走状况,是几万步在外面兜兜转转很忙呢,还是寥寥几百步甚至几十步宅在家里面呢,看得一清二楚。(排除那些用工具来刷步数的情况,大致还是很准确的了)
-
还能看到点赞的数量,这个点赞我觉得就是看你的好友的好友是不是时常关注这个微信运动了,因为我觉得很少会去在意别人吧并且还给他/她点赞,这样的行为我之前点赞过几次之后就没有再点过了,没必要,主要还是懒哈啊哈。
-
再者通过观察每个人的运动趋势,也能清楚地知道好友们这30天里面的运动情况的。是毫无波动地持续一个月的几千步呢,还是会有那么一两天突然增高呢,再或者是跌宕起伏地像人生一样呢,又或者走着走着步数变成了零呢(可能关闭了微信运动这个功能了)等等等等
-
可能我分析地还不够全面,不够细致,那就先这样吧
写在最后
为什么会去爬取微信运动信息并分析好友的运动情况呢?
一个原因:在很早之前,我就有过这个想法了,就想分析微信运动里好友们的运动情况,看看他们每一天是怎么过的,这其实是一件很好玩的事情嘻嘻。(我要我觉得,不要你觉得)
另一个原因:本来是想学appium的,因为想在手机上开发一些自动化的任务,比如日常签到啊,爬数据啊,刷xx啊等等(你懂的),并且还可以配合一些抓包工具来完成一些别人爬不到的数据哈哈(只存在于手机中的那些数据)。可是呢,不知道为啥,我只能拿到与微信相关的页面数据,其他的应用都不能拿到,拿不到页面数据那就别想爬虫了呀。我也百度找了很久,什么重装环境啦,Android API版本更换啦,我都试过了,还是不行。(学appium还真的是从入门到放弃呢),所以就在我下定决心快要卸载所有和appium相关的东西的时候,我忍住了,内心想法是既然都入门了,不搞一下就放弃了?于是乎就有了这一篇文章。
ps:其实我也有爬取过朋友圈动态里面的数据的,只是因为拿不到图片和视频,只能拿文字,我就想没有图片和视频那还爬什么呢,这些才是精华所在呀。(只是我个人看法,你们有兴趣也可以自己去尝试一番),对了,如果有Android大佬,可以帮我看下只能获取到微信页面数据,这是出了什么问题吗?万分感谢!