03xml 解析
xml文件的解析
1 常用的两种解析xml的思想
xml文件中存储了数据,将其读到内存中有两种方式
- DOM解析
- SAX解析
两种方式解析xml的优缺点:
- dom
dom会将xml文档加载进内存,形成一颗dom树(document对象),将文档的各个组成部分封装为对象。- 优点:可以对dom树进行增删改查。
- 缺点:dom树非常占内存,解析速度慢。
- sax
逐行读取,基于事件驱动- 优点:不占内存,速度快
- 缺点:只能读取,不能回写
1.1 DOM解析
所有现代浏览器都内建了供读取和操作 XML 的 XML 解析器。
Document Object Model(缩写DOM),即文档对象模型。
解析器把 xml转换为 XML DOM 对象 - 可通过 JavaScript 操作的对象。解析器把 XML 载入内存,然后把它转换为可通过 JavaScript 访问的 XML DOM 对象。将xml文档加载进内存,形成一颗dom树(document对象),将文档的各个组成部分封装为对象。通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,这种方式称为随机访问机制
DOM 把 XML 文档作为树结构来查看。能够通过 DOM 树来访问所有元素。可以修改或删除它们的内容,并创建新的元素。元素,它们的文本,以及它们的属性,都被认为是节点。
说明,虽然js提供了解析xml的方式,但并不是很好用,下面介绍的xml解析器提供了解析xml的api,添加相关jar包到工程会使解析工作方便些
1.2 SAX解析
Simple APIs for XML(缩写SAX),与DOM不同,SAX提供的访问模式是一种顺序模式,这是一种快速读写XML数据的方式。,SAX解析方式逐行扫描XML文档,遇到标签时会触发解析处理器,采用事件处理的方式解析。SAX接口也被称作事件驱动接口
2 xml常用解析器
JAXP:sun公司提供的解析器,支持dom和sax,不过使用的不多。
JDOM,下面一个是它的升级版
DOM4J:全称是dom for java,是jdom的升级版,性能优异,使用较为广泛
3 DOM4J
dom4j是一个Java的XML API,是jdom的升级品,用来读写XML文件的。该包采用集合框架并支持DOM,SAX和JAXP等解析方式
先说dom树,将xml文档看成一棵树,用Document定义,那么根元素,用Element定义,根元素包含的元素用Element定义,Element是一个比较完整的xml元素,包含了属性,子元素,注释等,节点用Node定义,Element的子节点是Node,也可能是Element
Node在这里表示范围最大的元素,一个属性,一个文本,一个注释,一个元素都是Node
画个图说明下
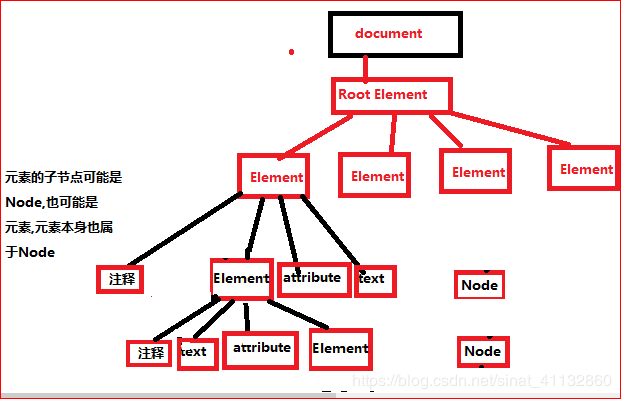
其实一棵树上的每一点不管是根元素,元素,还是节点都是一个Node,Document和Element也继承了Node接口,并在它的基础上进行了扩展,为了更好的区分不同元素类型,所以区分出了Element和Node
介绍dom4j jar包中常用的几个类
XAXReader类
org.dom4j.io.SAXReader,该类的定义为xml文档的解析对象
常用方法:
Document read(File file)
Document read(URL url)
Document read(String systemId) 有多个重载的read方法用来读取xml文件,并创建Document对象
Document接口
org.dom4j.Document,继承自Branch接口,Branch接口又继承自Node接口,该接口表示XML文档
常用方法:
Element getRootElement() 获取根元素
Element接口
org.dom4j.Element,继承自Branch接口,Branch接口又继承自Node接口,该接口表示XML 元素
常用方法:
List elements()返回该元素的子元素,即xml元素
Element element(String name),根据指定名字返回子元素中的xml元素
Node node(int index)该方法继承自Branch接口,返回该元素上指定名字的子节点,子节点可能是空格,文本等,单独的文本的名字为null,值为文本
int nodeCount()该方法继承自Branch接口,返回属于这个元素的所有子节点的数量,子元素本质上也属于节点,另外空格属于一个Node,但是名字为null
String getText()该方法继承自Node接口,获取元素上的文本
String getName()该方法继承自Node接口,获取元素名称
String attributeValue(String name)获取元素的属性值,根据元素属性的名字
Iterator nodeIterator()获取子节点的迭代器
Node接口
org.dom4j.Node,在Dom树中表示最小的元素,比如一个属性,或一个注释
常用方法:
String getName()返回节点名称
String getText()返回节点中的文本
下面两个方法想要使用,需要加入相关jar包jaxen-1.1-beta-6.jar,路径为\dom4j-1.6.1\lib\jaxen-1.1-beta-6.jar
List selectNodes(String xpathExpression)根据传入的路径,获取单个节点
List selectNodes(String xpathExpression)根据传入的路径,获取指定路径下所有的Node节点
Attribute接口
org.dom4j.Attribute,表示元素的属性
常用方法:
String getValue()返回该属性的属性值
3.1 使用dom4j中dom方式读取xml
采用dom的方式读取xml文档
package xml;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
public class Dom4jTest01 {
/**
*
* 找出xml文件中第4个元素的name标签的文本
*/
@Test
public void test1() throws DocumentException {
//创建xml解析对象
SAXReader sax=new SAXReader();
//将xml文档加载到Document对象
Document doc=sax.read("src/xml01.xml");
//获取根元素
Element root=doc.getRootElement();
//获取根元素的所有子元素
List list=root.elements();
//取出根元素下第4个元素
Element fourthEle=(Element)list.get(3);
//获取该元素下名为name的子元素上的文本
String name=fourthEle.element("sex").getText();
System.out.println(name);
//获取根元素下第4个元素的子元素name下的迭代器,观察子节点是什么
Iterator it=fourthEle.element("name").nodeIterator();
int count=0;
while(it.hasNext()) {
count+=1;
System.out.println(count+"===============");
Object obj=it.next();
if (obj instanceof Node) {
Node node=(Node)obj;
System.out.println(node.getName()+"node"+node.getText());
}
if (obj instanceof Element) {
Element ele=(Element)obj;
System.out.println(ele.getName()+"element"+ele.getText());
}
}
}
// 遍历所有元素节点
@Test
public void test2() throws DocumentException {
//创建xml解析对象
SAXReader sax=new SAXReader();
//将xml文档加载到Document对象
Document doc=sax.read("src/xml01.xml");
//获取根元素
Element root=doc.getRootElement();
//遍历根元素
checkNode(root);
}
//递归遍历元素
private void checkNode(Element ele) {
//打印元素名称
System.out.println(ele.getName());
//遍历属性
for(int i=0;inodename 选取此节点。
/ 从根节点选取。
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。
.. 选取当前节点的父节点。
@ 选取属性。
[@属性名] 属性过滤
[标签名] 子元素过滤xpath解析方式示例:
package xml;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import org.junit.Test;
public class XpathTest01 {
@Test
public void test1() throws DocumentException {
SAXReader sax=new SAXReader();
Document doc=sax.read("src/xml01.xml");
//选择第1个元素的name子元素
Node node1=doc.selectSingleNode("/students/student/name");
System.out.println(node1.getText());
//选择第2个元素的high子元素
Node node2=doc.selectSingleNode("/students/student[2]/high");
System.out.println(node2.getText());
//选择最后一个子元素的name子元素
Node node3=doc.selectSingleNode("/students/student[last()]/name");
System.out.println(node3.getText());
//选择第1个元素的id属性
Node node4=doc.selectSingleNode("/students/student/attribute::id");
System.out.println(node4.getText());
//选择第2个元素的id属性
Node node5=doc.selectSingleNode("/students/student[2]/attribute::id");
System.out.println(node5.getText());
}
@Test
public void test2() throws DocumentException{
SAXReader sax=new SAXReader();
Document doc=sax.read("src/xml01.xml");
//选择所有元素
List list=doc.selectNodes("//*");
for(int i=0;i
参考:小猴子视频