2018年秋招Java后台开发面试笔试总结(干货)+数据库
序
对于非科班找Java后台开发的小伙伴来说,本文具有很强的借鉴意义。本文包括以下7个方面,每个部分都详细说了各个部分的意义和常见题目。阅读本文需要充分利用目录来阅读。
1. Java基础
Java基础的意义
…这部分内容非常重要,几乎每个公司都会问到,如果基础不过关,后面的数据库、计算机网络、项目框架等可能就不会问了。并且面试评价上会写上: 基础太差,pass!
Java常见的面试笔试题
- Object类中有几种方法?

- 上述wait方法为什么不放在线程Thread类中?为什么放在Object类中?
因为Synchronized关键字在多线程加锁的时候,实际上是对对象头中markword进行的标志位的读写。因此这是针对的每个对象,而不是一个类。
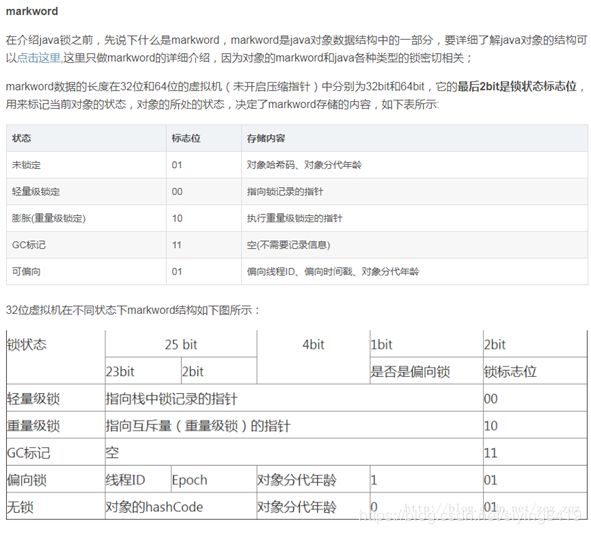
- finalize()方法和finally,以及final关键字什么区别,catch()中有return语句,finally中的语句是否执行?
https://www.cnblogs.com/ktao/p/8586966.html - equals和“==”和hashcode()有什么区别?为什么重写equals要重写hashcode()?
https://www.cnblogs.com/kexianting/p/8508207.html
1、如果两个对象equals,Java运行时环境会认为他们的hashcode一定相等。
2、如果两个对象不equals,他们的hashcode有可能相等。
3、如果两个对象hashcode相等,他们不一定equals。
4、如果两个对象hashcode不相等,他们一定不equals。
- 进程和线程的区别?
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
- HashMap和LinkedHashmap的区别?
HashMap无法保证遍历的顺序和插入数据的顺序一致,而LinkedHashmap可以保持与插入的顺序一致,原因是其内部维护了一个双向链表。 - 八种基本的数据类型?

- Collections.synchronizedMap()、ConcurrentHashMap、Hashtable之间的区别
https://www.cnblogs.com/shamo89/p/6700353.html
总结:
》1. 当一个线程访问 HashTable 的同步方法时,其他线程如果也要访问同步方法,会被阻塞住。举个例子,当一个线程使用 put 方法时,另一个线程不但不可以使用 put 方法,连 get 方法都不可以,好霸道啊!!!so~~,效率很低,现在基本不会选择它了。
》2. 从源码中可以看出调用 synchronizedMap() 方法后会返回一个 SynchronizedMap 类的对象,而在 SynchronizedMap 类中使用了 synchronized 同步关键字来保证对 Map 的操作是线程安全的
》3. ConcurrentHashMap将锁的粒度进一步缩小,在JDK 1.8中只锁数组头就行了。参考下文:
https://www.cnblogs.com/study-everyday/p/6430462.html - hashMap的数据结构是什么样的?扩容机制是怎样的?
是基于数组加链表加红黑树来实现的 ,扩容是要扩大原来size的二倍,原因是要保持hashcode&(size-1)尽量均匀。保持size是2的指数倍可以保证只要hashcode后面几位是均匀分布的,那么最终位于数组结构中的位置就是均匀的。 - hashmap中的阈值因子是怎么理解的?太大或太小会有什么影响?
太大则会发生很多hash冲突,太小会使底层容器的利用率下降。 - HashSet中的元素怎么实现的去重?
利用hashMap的key非重原理。底层的存储就是hashset的keys。 - 启动线程的两种方式?有什么区别?
※ 需要从Java.lang.Thread类派生一个新的线程类,重载它的run()方法;
※ 实现Runnalbe接口,重载Runnalbe接口中的run()方法。
在Java中,类仅支持单继承,也就是说,当定义一个新的类的时候,它只能扩展一个外部类.这样,如果创建自定义线程类的时候是通过扩展 Thread类的方法来实现的,那么这个自定义类就不能再去扩展其他的类,也就无法实现更加复杂的功能。因此,如果自定义类必须扩展其他的类,那么就可以使用实现Runnable接口的方法来定义该类为线程类,这样就可以避免Java单继承所带来的局限性。 - 线程池了解吗?为什么需要线程池?线程池中有几种队列?
①Java通过Executors提供四种线程池,分别为:
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
②线程池的意义:
线程池的作用:
线程池作用就是限制系统中执行线程的数量。
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
为什么要用线程池:
1.减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
2.可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
线程池中的相关参数
线程池中的执行过程

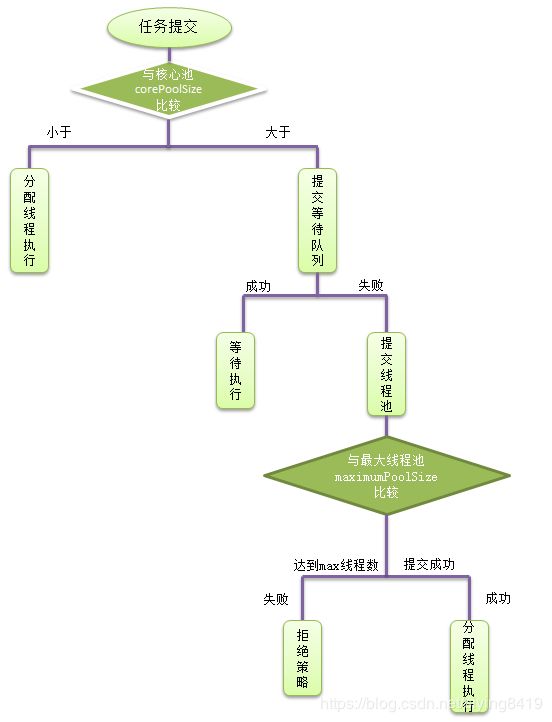
③ 线程池中的队列


14. newFixedThreadPool 中采用了什么阻塞队列,线程池中哪个参数不好用?
采用LinkedBolockingQueue,maxPoolSize参数不好用
15. Collection和Collections有什么区别?
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection是个java.util下的接口,它是各种集合结构的父接口。
16. java中的lock对象了解多少?说说AQS框架?
①lock和synchronize区别体现在以下几个方面:
第一:用法不一样。在需要同步的对象中加入synchronized控制,synchronized关键字既能够加在方法上,也可以加在代码块上,括号中需要表示需要锁的对象。而Lock需要显示的知识起始位置和终止位置。synchronize是托管给Jvm来执行的,而Lock的锁定是通过指定代码实现的,他有比synchronize更加精确地线程定义。
第二:性能不一样。在jdk有个lock接口的实现类,reentrantlock。他拥有和synchronize相同的并发性和内存予以,还多了锁投票,定时锁,等候和中断锁等。在竞争激烈的场景下,ReentranLock会比synchronize更有优势。
第三:锁机制不同。lock需要在finally代码快中进行显式释放。否则会发生死锁,而synchronized关键字则由jvm来进行释放锁。另外,lock还可以通过trylock来进行非阻塞式获得锁。
②AQS框架
https://www.cnblogs.com/waterystone/p/4920797.html
17. java虚拟机了解吗?内存模型画一下?
① java虚拟机是java具有跨平台特性的重要原因。
② 内存模型如下:

注:蓝色小块(方法区和堆)是线程共享的。白色小块为线程独享的(虚拟机栈,本地方法栈,程序计数器(PC))
1.**线程计数器**,是一块较小的内存空间,用来指定当前线程执行字节码的行数,每个线程计数器都是**私有**的,JVM的多线程是通过线程轮流切换分配执行时间来实现的,每个处理器都只会执行一个线程中的指令,所以每个线程必须有个独立的线程计数器。该内存区域是Java虚拟机唯一没有规定任何OutOfMemoryError的区域。 2.**Java虚拟栈**,这个也是一个线程私有的,生命周期与线程是同步的,每个方法在执行的同时,都会创建一个栈帧,每个方法的调用到执行完成的过程就是一个栈帧入栈到出栈的过程;虚拟机栈规定了2种异常情况,一种是线程请求栈的深度大于虚拟机栈所允许的深度,这时候将会抛出StackOverflowError异常,如果当Java虚拟机允许动态扩展虚拟机栈的时候,当扩展的时候没办法分配到内存的时候就会报OutOfMemoryError异常; 3.本地方法栈,与虚拟机栈执行的基本相同,唯一的区别就是虚拟机栈是执行Java方法的,本地方法栈是执行native方法的; 4.Java堆,堆区是Java虚拟机所管理的内存中最大的一块,Java堆是被所有线程共享的内存区域,主要存储对象的实例。 当堆中没有内存完成实例分配,并且堆无法扩展的时候,将会抛出OutOfMemoryError异常;当前虚拟机都是可以扩展的; 5.方法区,这个也是线程共享的内存区域,存储被虚拟机加载的类信息、常量、静态变量、即时编译的代码数据等;
- 垃圾回收都是怎么回收的,怎么判断对象是否该回收?
① 是引用计数器算法,
当创建对象的时候,为这个对象在堆栈空间中分配对象,同时会产生一个引用计数器,同时引用计数器1,当有新的引用的时候,引用计数器继续1,而当其中一个引用销毁的时候,引用计数器-1,当引用计数器被减为零的时候,标志着这个对象已经没有引用了,可以回收了!随着业务的发展,很快出现了一个问题:
当我们的代码出现下面的情形时,该算法将无法适应
a)ObjA-> ObjB
b)ObjB -> ObjA
这样的代码会产生如下引用情形 objA 指向objB ,而objB 又指向objA ,这样当其他所有的引用都消失了之后,objA 和objB 还有一个相互的引用,也就是说两个对象的引用计数器各为1
,而实际上这两个对象都已经没有额外的引用,已经是垃圾了,由此引出根搜索算法。
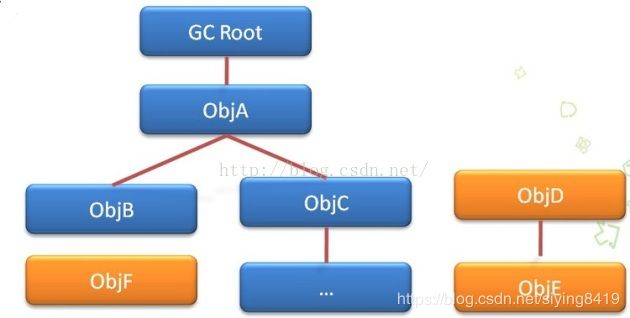
② 根搜索算法,
根搜索算法是从离散数学中的图论引入的,程序把所有的引用关系看作一张图,从一个节点GC ROOT 开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点。
目前java 中可作为GC Root 的对象有1,虚拟机栈中引用的对象(本地变量表)
2,方法区中静态属性引用的对象
3,方法区中常量引用的对象
4,本地方法栈中引用的对象(Native Object)
- 引用分为那几种?都用来做什么?
引用分为:
① 强引用:常见的对象引用,只要引用存在,垃圾回收器永远不会回收
Object obj = new Object();
而这样 obj对象对后面newObject的一个强引用,只有当obj这个引用被释放之后,对象才会被释放掉
② 软引用: 非必须引用,内存溢出之前进行回收,可以通过以下代码实现
Objectobj = new Object();
SoftReference这时候sf是对obj的一个软引用,通过sf.get()方法可以取到这个对象,当然,当这个对象被标记为需要回收的对象时,则返回null;
软引用主要用户实现类似缓存的功能,在内存足够的情况下直接通过软引用取值,无需从繁忙的真实来源查询数据,提升速度;当内存不足时,自动删除这部分缓存数据,从真正的来源查询这些数据。
③ 、 弱引用 : 第二次垃圾回收时回收,可以通过如下代码实现
Objectobj = new Object();
WeakReference弱引用是在第二次垃圾回收时回收,短时间内通过弱引用取对应的数据,可以取到,当执行过第二次垃圾回收时,将返回null。
④ 虚引用:垃圾回收时回收,无法通过引用取到对象值,可以通过如下代码实现
Objectobj = new Object();
PhantomReference虚引用是每次垃圾回收的时候都会被回收,通过虚引用的get方法永远获取到的数据为null,因此也被成为幽灵引用。虚引用主要用于检测对象是否已经从内存中删除。
- 常见的垃圾回收器都有什么?
1、Serial收集器曾经是虚拟机新生代收集的唯一选择,是一个单线程的收集器,在进行收集垃圾时,必须stop the world,它是虚拟机运行在Client模式下的默认新生代收集器。
2、Serial Old是Serial收集器的老年代版本,同样是单线程收集器,使用标记整理算法。
3、ParNew收集器是Serial收集器的多线程版本,许多运行在Server模式下的虚拟机中首选的新生代收集器,除Serial外,只有它能与CMS收集器配合工作。
4、Parallel Scavenge收集器也是新生代收集器,使用复制算法又是并行的多线程收集器,它的目标是达到一个可控制的运行用户代码跟(运行用户代码+垃圾收集时间)的百分比值。5、Parallel Old收集器是Parallel Scavenge收集器的老年代版本,使用多线程和标记整理算法。
6、Concurrent Mark Sweep 收集器是一种以获得最短回收停顿时间为目标的收集器,基于标记清除算法。
过程如下:初始标记,并发标记,重新标记,并发清除,优点是并发收集,低停顿,缺点是对CPU资源非常敏感,无法处理浮动垃圾,收集结束会产生大量空间碎片。
7、G1收集器是基于标记整理算法实现的,不会产生空间碎片,可以精确地控制停顿,将堆划分为多个大小固定的独立区域,并跟踪这些区域的垃圾堆积程度,在后台维护一个优先列表,每次根据允许的收集时间,优先回收垃圾最多的区域(Garbage
First)。

- cms 和 g1垃圾回收有什么区别?
https://blog.csdn.net/linhu007/article/details/48897597
1、并行与并发:G1能充分利用CPU、多核环境下的硬件优势,使用多个CPU(CPU或者CPU核心)来缩短stop-The-World停顿时间。部分其他收集器原本需要停顿Java线程执行的GC动作,G1收集器仍然可以通过并发的方式让java程序继续执行。
2、分代收集:虽然G1可以不需要其他收集器配合就能独立管理整个GC堆,但是还是保留了分代的概念。它能够采用不同的方式去处理新创建的对象和已经存活了一段时间,熬过多次GC的旧对象以获取更好的收集效果。
3、空间整合:与CMS的“标记–清理”算法不同,G1从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
4、可预测的停顿:这是G1相对于CMS的另一个大优势,降低停顿时间是G1和CMS共同的关注点,但G1除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为M毫秒的时间片段内,
- 类的加载机制是什么?什么是双亲委派模型?如何破坏?
类从被加载到虚拟机内存中开始,到卸载出内存为止,这七个阶段的发生顺序如下图所示:
加载:类的装载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区内,然后在堆区创建一个java.lang.Class对象,用来封装类在方法区内的数据结构。
验证:验证的目的是为了确保Class文件中的字节流包含的信息符合当前虚拟机的要求,而且不会危害虚拟机自身的安全。不同的虚拟机对类验证的实现可能会有所不同,但大致都会完成以下四个阶段的验证:文件格式的验证、元数据的验证、字节码验证和符号引用验证。
准备:准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中进行分配。
解析:解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。
初始化:类初始化阶段是类加载过程的最后一步,前面的类加载过程中,除了加载(Loading)阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。

- 了解java的锁类型吗?
- 什么是cas操作?cas操作的ABA问题怎么解决?
- 什么是锁的膨胀机制?什么是锁粗化?
- 还有好多问题,这里就不一一列出了,总之基础非常重要,附上一个很重要的链接,大家可以去GitHub上clone一个java最新的面试题。
链接: https://github.com/Huberychina/JavaGuide

2. 项目实战知识
项目的意义
项目经验在面试中占得比例也很大,而且很多情况是面试时候第一个问题:比如说,
通常流程就是如下:
- 你好,请你自我介绍一下自己?
- 看到你曾经做过****管理系统对吧,请介绍一下相关情况,软件架构是怎样的?
- 看你项目中用到了Spring框架,了解底层原理吗?。。。。。。
所以,项目是切入口,更有甚者,曾经出现过史上最短面试经历
Q: 说一下你的项目经历?
A:我没有相关的项目经历
Q:那你有什么要问我的?
所以,项目一定要重视,如果是有应用高并发、大数据场景的的产品,会非常加分。
项目常见的面试笔试题
- 说说你的软件架构?
- Spring用过吗?怎么理解的ioc和aop?
- AOP实现的原理?
- Spring中的bean的生命周期?
- Spring mvc是怎么执行的?
- Mybatis中的缓存是怎么做的?
- 项目中的分页是怎么做的?
- Spring中用到了哪些设计模式?
- 说说redis的作用?
- redis的五种数据结构及1其应用场景?
- 项目中的问题处理方法?
- 你在项目中最大的收获是什么?
3. 数据库
数据库的意义
作为后端程序开发者,数据库是必备技能之一,概率是百分之百会问到。而且在实际开发过程中,数据库的设计和优化也是后端开发者花大量时间的地方。因此,其相关技能在面试中非常重要。
这个部分相当于基础,掌握不是特别的加分项,但是不掌握很可能给面试官基础不过关的感觉,例如数据库的隔离级别这种问题,是在面试官觉得非常简单的问题,一定要记牢。
数据库常见的面试笔试题
- 数据库用的是什么数据库?Mysql还是Oracle?
- Mysql 中有哪些引擎?
- Mysql 的索引有几种?
- Mysql中索引的存储结构?为什么不用hash存储?为什么不用B树存储?
- 数据库的隔离级别有哪几种?
- 数据库有几种锁?
- 表级锁和行级锁都是怎么实现的?
- 乐观锁和悲观锁的读写关系都是什么?
- 你能设计一个问卷调查的后台数据库系统吗?
- 简单的sql语句,
select * from tb1 inner join tb2 on id1=id2 where (balabala) group by (balabala) order by (balabala)
类似这种
4. 数据结构与算法
算法的意义
算法在面试中个人感觉比例约占百分之30,但是这个部分对面试官给你的评价占比超过百分之八十。换句话说,你的基础不好,项目基础薄弱,但是算法超级厉害,那么很有可能得到面试官的青睐。
因为,项目和基础这种东西其实很好补,一个985大学的学生,可能两个月就补回来了,但是算法是不太好补的。
一个好的算法设计会是程序的点睛之笔,程序真正美在算法。
所以,重视算法一定是你拿到大厂offer的必要条件。
算法常见的面试笔试题
- 剑指offer所有
- lettcode上算法题
- 各种排序
- 各种大数据处理
- 大数据top K问题
- LRU等等
5. 设计模式
设计模式的意义
有时候设计模式会作为切入点来问你,因为这个部分比较简单,你看过就知道了,没看过也无妨,可以很轻松的回答。设计模式说到底就是一种编程思想,没什么技术含量其实。
但是,这个部分很重要,尤其是单例模式这种常见的设计模式,可以说在实际开发也经常使用,所以这个部分的内容,花不了多长时间就能学会,不需要死记硬背,但是要记得思想。
设计模式面试笔试题
- 单例模式
https://blog.csdn.net/siying8419/article/details/82152921 - 工厂模式
https://blog.csdn.net/siying8419/article/details/81044238 - 适配器模式
https://blog.csdn.net/siying8419/article/details/81044791 - 代理模式
https://blog.csdn.net/siying8419/article/details/81045330
代理模式在AOP中的应用
https://blog.csdn.net/siying8419/article/details/81189833 - 责任链模式
https://blog.csdn.net/siying8419/article/details/81045687
6. 前端知识
前端知识的意义
前端知识对于后端开发人来说,可能不是那么重要。但是,在实际校园招聘来说,由于招聘任务巨大,非常有可能前端工程师面试你,所以这个时候掌握一些前端知识就显得尤为重要了。
其实,从技术层面来说,个人感觉,后端应该会前端的知识,因为很多前端的知识是常识,作为一个程序员,没有理由不会。面试的时候,也会问你这些常识比较多。
前端知识的面试笔试题
- http和https的区别?
- ssl是对称加密还是非对称加密?
- 什么是Ajax?
- 什么是Json?
- 前端校验和后端校验有什么不同?
- 了解node吗?
- 描述浏览器中敲一个url,后发生了什么?
- http有几种请求?get和post有什么区别?
7. 除了Java技术栈的知识
知识扩展的意义
这里除了java知识,作为一名后端工程师,对计算机网络,操作系统,虚拟化,微服务,大数据等知识了解很多,会在面试的非常加分。
常见的面试笔试题
- 计算机网络
1.1 了解三次握手吗?为什么需要四次挥手?
1.2 了解拥塞控制方法吗?
1.3 滑动窗口说一下理解
1.4 TCP和UDP 的区别?
1.5 说以下为什么不用Mac地址直接组网?
1.6 七层模型了解多少?
1.8 子网掩码工作原理?有什么用? - 操作系统
2.1 Linux 了解吗?
2.2 如何创建一个不存在的多层路径?
2.3 如何查看进程?
2.4 如何查看内存管理? - git操作了解吗?
- git中的clone和fork操作过吗?
- docker知道吗?
- 你了解哪些微服务?
- 了解Hadoop吗?
8. 补充GitHub面试题连接
大家可以去GitHub上clone一个java最新的面试题。
链接: https://github.com/Huberychina/JavaGuide