梯度下降优化算法概述
This post explores how many of the most popular gradient-based optimization algorithms actually work.
Note: If you are looking for a review paper, this blog post is also available as an article on arXiv.
Update 09.02.2018: Added AMSGrad.
Update 24.11.2017: Most of the content in this article is now also available as slides.
Update 15.06.2017: Added derivations of AdaMax and Nadam.
Update 21.06.16: This post was posted to Hacker News. The discussion provides some interesting pointers to related work and other techniques.
Table of contents:
●几种梯度下降算法
●Batch梯度下降
●随机梯度下降
●Mini-batch梯度下降
●挑战
●梯度下降优化算法
●Momentum
●Nesterov加速梯度
●Adagrad
●Adadelta
●RMSprop
●Adam
●AdaMax
●Nadam
●AMSGrad
●算法可视化
●该使用哪种优化算法?
●并行和分布式SGD
●Hogwild!
●Downpour SGD
●SGD延迟容忍算法
●TensorFlow
●弹性平均SGD
●优化SGD的其它策略
●重排和递进学习
●Batch标准化
●早停法
●梯度噪声
●结论
梯度下降是执行优化的最流行算法之一,也是迄今为止最优化神经网络的最常用方法。同时,每个最新的深度学习库都包含各种针对梯度下降优化算法的实现(e.g. lasagne, caffe,以及keras的文档)。但是,这些算法通常用作黑盒优化器,那么针对其优点和缺点就很难得到实用的解释。
这篇文章旨在为您提供优化梯度下降的不同算法行为的直观概念,这将有助于您使用它们。我们首先会介绍几种不同的梯度下降法。然后,将简要总结训练数据时遇到的挑战。随后,我们将介绍最常见的优化算法,说明它们解决这些挑战的动机,以及这如何导致其更新规则的推导。我们还将简要介绍在并行和分布式设置中优化梯度下降的算法和体系结构。最后,我们将考虑有助于优化梯度下降的其他策略。
梯度下降是一种最小化目标函数 J ( θ ) J(\theta) J(θ)方法,该目标函数由是模型参数 θ ∈ R d \theta \in \mathbb{R}^d θ∈Rd参数化的,梯度下降会根据相关参数在与目标函数 ∇ θ J ( θ ) \nabla_\theta J(\theta) ∇θJ(θ)梯度相反的方向上来更新参数。学习率 η \eta η决定了我们到达(局部)最小值的步长。换句话说,我们沿着由目标函数创建的表面斜坡方向下坡,直到山谷。如果您不熟悉梯度下降,可以在这里找到有关优化神经网络的很好的介绍。
几种梯度下降算法
梯度下降有三种变体,它们的不同之处在于计算目标函数的梯度时使用多少数据。 根据数据量,我们在参数更新的准确性和执行更新所需的时间之间进行权衡。
Batch梯度下降
Vanilla梯度下降,又称批梯度下降,用于计算整个训练数据集关于参数 θ \theta θ的代价函数的梯度:
θ = θ − η ⋅ ∇ θ J ( θ ) \theta = \theta - \eta \cdot \nabla_\theta J( \theta) θ=θ−η⋅∇θJ(θ).
由于我们需要计算整个数据集的梯度以仅执行一次更新,因此批次梯度下降可能非常缓慢,并且对于与内存不合适的数据集来说很棘手。批梯度下降法也不允许我们在线更新模型,即:即时添加新实例。
在代码中,批梯度下降看起来像这样:
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
对于预定义的周期数,我们首先计算与参数向量“params”相关的整个数据集的代价函数的梯度向量“ params_grad”。请注意,最新的深度学习库提供自动区分功能,可以有效地计算某些参数的梯度。如果您依靠自己计算出梯度,那么最好进行梯度检查。(关于如何正确检查渐变的一些重要提示,请参考此处。)
然后,我们按梯度相反的方向更新参数,学习率决定了我们执行的更新量。在凸误差曲面上,批梯度下降可以保证收敛到全局最小值,对于非凸曲面,可以保证收敛到局部最小值。
随机梯度下降
相反,随机梯度下降(SGD)为每个训练示例 x ( i ) x^{(i)} x(i)和标签 y ( i ) y^{(i)} y(i)执行参数更新:
θ = θ − η ⋅ ∇ θ J ( θ ; x ( i ) ; y ( i ) ) \theta = \theta - \eta \cdot \nabla_\theta J( \theta; x^{(i)}; y^{(i)}) θ=θ−η⋅∇θJ(θ;x(i);y(i)).
批梯度下降对大型数据集执行冗余计算,因为它会在每个参数更新之前重新计算相似实例的梯度。SGD通过在单位时间内执行一次更新来消除这种冗余。 因此,它通常要快得多,也可以用于在线学习。
SGD频繁执行更新,且变化很大,这导致目标函数如图1所示剧烈波动。
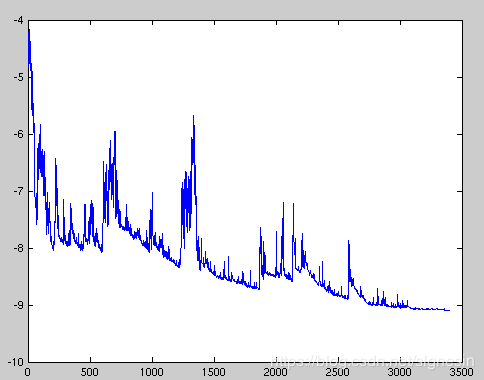
图1: SGD波动 (来源: Wikipedia)
当批梯度下降收敛到参数所放置的盆地的最小值时,一方面,SGD的波动使它跳到新的并可能是更好的局部最小值;而另一方面,由于SGD会持续超调,因此最终会使收敛到最小的精确度变得复杂。However, it has been shown that when we slowly decrease the learning rate, SGD shows the same convergence behaviour as batch gradient descent, almost certainly converging to a local or the global minimum for non-convex and convex optimization respectively.但是,已经表明,当我们缓慢降低学习率时,SGD会显示与批梯度下降相同的收敛行为,几乎可以肯定,对于非凸和凸优化,它们分别收敛到局部或全局最小值。
Its code fragment simply adds a loop over the training examples and evaluates the gradient w.r.t. each example. Note that we shuffle the training data at every epoch as explained in this section.
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad
Mini-batch gradient descent
Mini-batch gradient descent finally takes the best of both worlds and performs an update for every mini-batch of n n n training examples:
θ = θ − η ⋅ ∇ θ J ( θ ; x ( i : i + n ) ; y ( i : i + n ) ) \theta = \theta - \eta \cdot \nabla_\theta J( \theta; x^{(i:i+n)}; y^{(i:i+n)}) θ=θ−η⋅∇θJ(θ;x(i:i+n);y(i:i+n)).
This way, it a ) a) a) reduces the variance of the parameter updates, which can lead to more stable convergence; and b ) b) b) can make use of highly optimized matrix optimizations common to state-of-the-art deep learning libraries that make computing the gradient w.r.t. a mini-batch very efficient. Common mini-batch sizes range between 50 and 256, but can vary for different applications. Mini-batch gradient descent is typically the algorithm of choice when training a neural network and the term SGD usually is employed also when mini-batches are used. Note: In modifications of SGD in the rest of this post, we leave out the parameters x ( i : i + n ) ; y ( i : i + n ) x^{(i:i+n)}; y^{(i:i+n)} x(i:i+n);y(i:i+n) for simplicity.
In code, instead of iterating over examples, we now iterate over mini-batches of size 50:
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
Challenges
Vanilla mini-batch gradient descent, however, does not guarantee good convergence, but offers a few challenges that need to be addressed:
● Choosing a proper learning rate can be difficult. A learning rate that is too small leads to painfully slow convergence, while a learning rate that is too large can hinder convergence and cause the loss function to fluctuate around the minimum or even to diverge.
● Learning rate schedules try to adjust the learning rate during training by e.g. annealing, i.e. reducing the learning rate according to a pre-defined schedule or when the change in objective between epochs falls below a threshold. These schedules and thresholds, however, have to be defined in advance and are thus unable to adapt to a dataset’s characteristics.
● Additionally, the same learning rate applies to all parameter updates. If our data is sparse and our features have very different frequencies, we might not want to update all of them to the same extent, but perform a larger update for rarely occurring features.
● Another key challenge of minimizing highly non-convex error functions common for neural networks is avoiding getting trapped in their numerous suboptimal local minima. Dauphin et al. argue that the difficulty arises in fact not from local minima but from saddle points, i.e. points where one dimension slopes up and another slopes down. These saddle points are usually surrounded by a plateau of the same error, which makes it notoriously hard for SGD to escape, as the gradient is close to zero in all dimensions.
Gradient descent optimization algorithms
In the following, we will outline some algorithms that are widely used by the deep learning community to deal with the aforementioned challenges. We will not discuss algorithms that are infeasible to compute in practice for high-dimensional data sets, e.g. second-order methods such as Newton’s method.
Momentum
SGD has trouble navigating ravines, i.e. areas where the surface curves much more steeply in one dimension than in another, which are common around local optima. In these scenarios, SGD oscillates across the slopes of the ravine while only making hesitant progress along the bottom towards the local optimum as in Image 2.
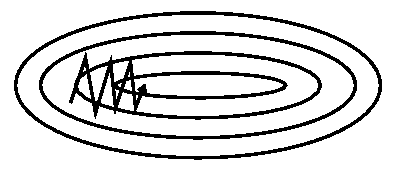
Image 2: SGD without momentum

Image 3: SGD with momentum
Momentum is a method that helps accelerate SGD in the relevant direction and dampens oscillations as can be seen in Image 3. It does this by adding a fraction γ γ γ of the update vector of the past time step to the current update vector:
v t = γ v t − 1 + η ∇ θ J ( θ ) θ = θ − v t v_t= \gamma v_{t-1} + \eta \nabla_\theta J( \theta) \\ \theta= \theta - v_t vt=γvt−1+η∇θJ(θ)θ=θ−vt
Note: Some implementations exchange the signs in the equations. The momentum term γ \gamma γ is usually set to 0.9 or a similar value.
Essentially, when using momentum, we push a ball down a hill. The ball accumulates momentum as it rolls downhill, becoming faster and faster on the way (until it reaches its terminal velocity if there is air resistance, i.e. γ < 1 \gamma<1 γ<1). The same thing happens to our parameter updates: The momentum term increases for dimensions whose gradients point in the same directions and reduces updates for dimensions whose gradients change directions. As a result, we gain faster convergence and reduced oscillation.
Nesterov accelerated gradient
However, a ball that rolls down a hill, blindly following the slope, is highly unsatisfactory. We’d like to have a smarter ball, a ball that has a notion of where it is going so that it knows to slow down before the hill slopes up again.
Nesterov accelerated gradient (NAG) [6] is a way to give our momentum term this kind of prescience. We know that we will use our momentum term γ v t − 1 \gamma v_{t-1} γvt−1 to move the parameters θ \theta θ . Computing θ − γ v t − 1 \theta - \gamma v_{t-1} θ−γvt−1 thus gives us an approximation of the next position of the parameters (the gradient is missing for the full update), a rough idea where our parameters are going to be. We can now effectively look ahead by calculating the gradient not w.r.t. to our current parameters θ \theta θ but w.r.t. the approximate future position of our parameters:
v t = γ v t − 1 + η ∇ θ J ( θ − γ v t − 1 ) θ = θ − v t v_t= \gamma v_{t-1} + \eta \nabla_\theta J( \theta - \gamma v_{t-1} ) \\ \theta= \theta - v_t vt=γvt−1+η∇θJ(θ−γvt−1)θ=θ−vt
Again, we set the momentum term γ \gamma γ to a value of around 0.9. While Momentum first computes the current gradient (small blue vector in Image 4) and then takes a big jump in the direction of the updated accumulated gradient (big blue vector), NAG first makes a big jump in the direction of the previous accumulated gradient (brown vector), measures the gradient and then makes a correction (red vector), which results in the complete NAG update (green vector). This anticipatory update prevents us from going too fast and results in increased responsiveness, which has significantly increased the performance of RNNs on a number of tasks.
 Image 4: Nesterov update (Source: G. Hinton’s lecture 6c)
Image 4: Nesterov update (Source: G. Hinton’s lecture 6c)
Refer to here for another explanation about the intuitions behind NAG, while Ilya Sutskever gives a more detailed overview in his PhD thesis.
Now that we are able to adapt our updates to the slope of our error function and speed up SGD in turn, we would also like to adapt our updates to each individual parameter to perform larger or smaller updates depending on their importance.
Adagrad
Adagrad is an algorithm for gradient-based optimization that does just this: It adapts the learning rate to the parameters, performing smaller updates
(i.e. low learning rates) for parameters associated with frequently occurring features, and larger updates (i.e. high learning rates) for parameters associated with infrequent features. For this reason, it is well-suited for dealing with sparse data. Dean et al. have found that Adagrad greatly improved the robustness of SGD and used it for training large-scale neural nets at Google, which – among other things – learned to recognize cats in Youtube videos. Moreover, Pennington et al. used Adagrad to train GloVe word embeddings, as infrequent words require much larger updates than frequent ones.
Previously, we performed an update for all parameters θ \theta θ at once as every parameter θ i \theta_i θi used the same learning rate η \eta η. As Adagrad uses a different learning rate for every parameter θ i \theta_i θi at every time step t t t, we first show Adagrad’s per-parameter update, which we then vectorize. For brevity, we use g t g_{t} gt to denote the gradient at time step
t t t. g t , i g_{t, i} gt,i is then the partial derivative of the objective function w.r.t. to the parameter θ i \theta_i θi at time step t t t:
g t , i = ∇ θ J ( θ t , i ) g_{t, i} = \nabla_\theta J( \theta_{t, i} ) gt,i=∇θJ(θt,i)
The SGD update for every parameter θ i \theta_i θi at each time step t t t then becomes:
θ t + 1 , i = θ t , i − η ⋅ g t , i \theta_{t+1, i} = \theta_{t, i} - \eta \cdot g_{t, i} θt+1,i=θt,i−η⋅gt,i
In its update rule, Adagrad modifies the general learning rate η \eta η at each time step t t t
for every parameter θ i \theta_i θi based on the past gradients that have been computed for θ i \theta_i θi:
θ t + 1 , i = θ t , i − η G t , i i + ϵ ⋅ g t , i \theta_{t+1, i} = \theta_{t, i} - \dfrac{\eta}{\sqrt{G_{t, ii} + \epsilon}} \cdot g_{t, i} θt+1,i=θt,i−Gt,ii+ϵη⋅gt,i
G t ∈ R d × d G_{t} \in \mathbb{R}^{d \times d} Gt∈Rd×d here is a diagonal matrix where each diagonal element i i i, i i i is the sum of the squares of the gradients w.r.t. θ i \theta_i θi up to time step t t t, while ϵ \epsilon ϵ is a smoothing term that avoids division by zero (usually on the order of 1 e − 8 1e-8 1e−8). Interestingly, without the square root operation, the algorithm performs much worse.
As G t G_t Gt contains the sum of the squares of the past gradients w.r.t. to all parameters t h e t a theta theta along its diagonal, we can now vectorize our implementation by performing a matrix-vector product ⊙ \odot ⊙ between between G t G_t Gt and g t g_t gt:
θ t + 1 = θ t − η G t + ϵ ⊙ g t \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{G_{t} + \epsilon}} \odot g_{t} θt+1=θt−Gt+ϵη⊙gt
One of Adagrad’s main benefits is that it eliminates the need to manually tune the learning rate. Most implementations use a default value of 0.01 and leave it at that.
Adagrad’s main weakness is its accumulation of the squared gradients in the denominator: Since every added term is positive, the accumulated sum keeps growing during training. This in turn causes the learning rate to shrink and eventually become infinitesimally small, at which point the algorithm is no longer able to acquire additional knowledge. The following algorithms aim to resolve this flaw.
Adadelta
Adadelta is an extension of Adagrad that seeks to reduce its aggressive, monotonically decreasing learning rate. Instead of accumulating all past squared gradients, Adadelta restricts the window of accumulated past gradients to some fixed size w w w.
Instead of inefficiently storing w w w previous squared gradients, the sum of gradients is recursively defined as a decaying average of all past squared gradients. The running average E [ g 2 ] t E[g^2]_t E[g2]t at time step t t t then depends (as a fraction γ \gamma γ similarly to the Momentum term) only on the previous average and the current gradient:
E [ g 2 ] t = γ E [ g 2 ] t − 1 + ( 1 − γ ) g t 2 E[g^2]_t = \gamma E[g^2]_{t-1} + (1 - \gamma) g^2_t E[g2]t=γE[g2]t−1+(1−γ)gt2
We set γ \gamma γ to a similar value as the momentum term, around 0.9. For clarity, we now rewrite our vanilla SGD update in terms of the parameter update vector Δ θ t \Delta \theta_t Δθt:
Δ θ t = − η ⋅ g t , i θ t + 1 = θ t + Δ θ t \Delta \theta_t= - \eta \cdot g_{t, i} \\ \theta_{t+1}= \theta_t + \Delta \theta_t Δθt=−η⋅gt,iθt+1=θt+Δθt
The parameter update vector of Adagrad that we derived previously thus takes the form:
Δ θ t = − η G t + ϵ ⊙ g t \Delta \theta_t = - \dfrac{\eta}{\sqrt{G_{t} + \epsilon}} \odot g_{t} Δθt=−Gt+ϵη⊙gt
We now simply replace the diagonal matrix G t G_t Gt with the decaying average over past squared gradients E [ g 2 ] t E[g^2]_t E[g2]t:
Δ θ t = − η E [ g 2 ] t + ϵ g t \Delta \theta_t = - \dfrac{\eta}{\sqrt{E[g^2]_t + \epsilon}} g_{t} Δθt=−E[g2]t+ϵηgt
As the denominator is just the root mean squared (RMS) error criterion of the gradient, we can replace it with the criterion short-hand:
Δ θ t = − η R M S [ g ] t g t \Delta \theta_t = - \dfrac{\eta}{RMS[g]_{t}} g_t Δθt=−RMS[g]tηgt
The authors note that the units in this update (as well as in SGD, Momentum, or Adagrad) do not match, i.e. the update should have the same hypothetical units as the parameter. To realize this, they first define another exponentially decaying average, this time not of squared gradients but of squared parameter updates:
E [ Δ θ 2 ] t = γ E [ Δ θ 2 ] t − 1 + ( 1 − γ ) Δ θ t 2 E[\Delta \theta^2]_t = \gamma E[\Delta \theta^2]_{t-1} + (1 - \gamma) \Delta \theta^2_t E[Δθ2]t=γE[Δθ2]t−1+(1−γ)Δθt2
The root mean squared error of parameter updates is thus:
R M S [ Δ θ ] t = E [ Δ θ 2 ] t + ϵ RMS[\Delta \theta]_{t} = \sqrt{E[\Delta \theta^2]_t + \epsilon} RMS[Δθ]t=E[Δθ2]t+ϵ
Since R M S [ Δ θ ] t RMS[\Delta \theta]_{t} RMS[Δθ]t is unknown, we approximate it with the RMS of parameter updates until the previous time step. Replacing the learning rate η \eta η in the previous update rule with R M S [ Δ θ ] t − 1 RMS[\Delta \theta]_{t-1} RMS[Δθ]t−1 finally yields the Adadelta update rule:
Δ θ t = − R M S [ Δ θ ] t − 1 R M S [ g ] t g t θ t + 1 = θ t + Δ θ t \Delta \theta_t= - \dfrac{RMS[\Delta \theta]_{t-1}}{RMS[g]_{t}} g_{t} \\ \theta_{t+1}= \theta_t + \Delta \theta_t Δθt=−RMS[g]tRMS[Δθ]t−1gtθt+1=θt+Δθt
With Adadelta, we do not even need to set a default learning rate, as it has been eliminated from the update rule.
RMSprop
RMSprop is an unpublished, adaptive learning rate method proposed by Geoff Hinton in Lecture 6e of his Coursera Class.
RMSprop and Adadelta have both been developed independently around the same time stemming from the need to resolve Adagrad’s radically diminishing learning rates. RMSprop in fact is identical to the first update vector of Adadelta that we derived above:
E [ g 2 ] t = 0.9 E [ g 2 ] t − 1 + 0.1 g t 2 θ t + 1 = θ t − η E [ g 2 ] t + ϵ g t E[g^2]_t= 0.9 E[g^2]_{t-1} + 0.1 g^2_t \\ \theta_{t+1}= \theta_{t} - \dfrac{\eta}{\sqrt{E[g^2]_t + \epsilon}} g_{t} E[g2]t=0.9E[g2]t−1+0.1gt2θt+1=θt−E[g2]t+ϵηgt
RMSprop as well divides the learning rate by an exponentially decaying average of squared gradients. Hinton suggests γ \gamma γ to be set to 0.9, while a good default value for the learning rate η \eta η is 0.001.
Adam
Adaptive Moment Estimation (Adam) is another method that computes adaptive learning rates for each parameter. In addition to storing an exponentially decaying average of past squared gradients v t v_t vt like Adadelta and RMSprop, Adam also keeps an exponentially decaying average of past gradients m t m_t mt, similar to momentum. Whereas momentum can be seen as a ball running down a slope, Adam behaves like a heavy ball with friction, which thus prefers flat minima in the error surface. We compute the decaying averages of past and past squared gradients m t m_t mt and v t v_t vt respectively as follows:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 m_t= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ v_t= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2
m t m_t mt and v t v_t vt are estimates of the first moment (the mean) and the second moment (the uncentered variance) of the gradients respectively, hence the name of the method. As m t m_t mt and v t v_t vt are initialized as vectors of 0’s, the authors of Adam observe that they are biased towards zero, especially during the initial time steps, and especially when the decay rates are small (i.e. β 1 \beta_1 β1 and β 2 \beta_2 β2 are close to 1).
They counteract these biases by computing bias-corrected first and second moment estimates:
m ^ t = m t 1 − β 1 t v ^ t = v t 1 − β 2 t \hat{m}_t= \dfrac{m_t}{1 - \beta^t_1} \\ \hat{v}_t= \dfrac{v_t}{1 - \beta^t_2} m^t=1−β1tmtv^t=1−β2tvt
They then use these to update the parameters just as we have seen in Adadelta and RMSprop, which yields the Adam update rule:
θ t + 1 = θ t − η v ^ t + ϵ m ^ t \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θt+1=θt−v^t+ϵηm^t
The authors propose default values of 0.9 for β 1 \beta_1 β1, 0.999 for β 2 \beta_2 β2,and 1 0 − 8 10^{-8} 10−8 for ϵ \epsilon ϵ. They show empirically that Adam works well in practice and compares favorably to other adaptive learning-method algorithms.
AdaMax
The v t v_t vt factor in the Adam update rule scales the gradient inversely proportionally to the ℓ 2 \ell_2 ℓ2 norm of the past gradients (via the v t − 1 v_{t−1} vt−1 term) and current gradient ∣ g t ∣ 2 |g_t|^2 ∣gt∣2:
v t = β 2 v t − 1 + ( 1 − β 2 ) ∣ g t ∣ 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) |g_t|^2 vt=β2vt−1+(1−β2)∣gt∣2
We can generalize this update to the ℓ p \ell_p ℓp orm. Note that Kingma and Ba also parameterize
β 2 \beta_2 β2 as β 2 p \beta^p_2 β2p:
v t = β 2 p v t − 1 + ( 1 − β 2 p ) ∣ g t ∣ p v_t = \beta_2^p v_{t-1} + (1 - \beta_2^p) |g_t|^p vt=β2pvt−1+(1−β2p)∣gt∣p
Norms for large p p p values generally become numerically unstable, which is why ℓ 1 \ell_1 ℓ1 and ℓ 2 \ell_2 ℓ2 norms are most common in practice. However, ℓ ∞ \ell_\infty ℓ∞ also generally exhibits stable behavior. For this reason, the authors propose AdaMax (Kingma and Ba, 2015) and show that v t v_t vt with ℓ ∞ \ell_\infty ℓ∞ converges to the following more stable value. To avoid confusion with Adam, we use u t u_t ut to denote the infinity norm-constrained v t v_t vt:
u t = β 2 ∞ v t − 1 + ( 1 − β 2 ∞ ) ∣ g t ∣ ∞ = max ( β 2 ⋅ v t − 1 , ∣ g t ∣ ) u_t= \beta_2^\infty v_{t-1} + (1 - \beta_2^\infty) |g_t|^\infty= \max(\beta_2 \cdot v_{t-1}, |g_t|) ut=β2∞vt−1+(1−β2∞)∣gt∣∞=max(β2⋅vt−1,∣gt∣)
We can now plug this into the Adam update equation by replacing v ^ t + ϵ \sqrt{\hat{v}_t} + \epsilon v^t+ϵ with u t u_t ut to obtain the AdaMax update rule:
θ t + 1 = θ t − η u t m ^ t \theta_{t+1} = \theta_{t} - \dfrac{\eta}{u_t} \hat{m}_t θt+1=θt−utηm^t
Note that as u t u_t ut relies on the max operation, it is not as suggestible to bias towards zero as m t m_t mt and v t v_t vt in Adam, which is why we do not need to compute a bias correction for u t u_t ut. Good default values are again η = 0.002 \eta = 0.002 η=0.002, β 1 = 0.9 \beta_1 = 0.9 β1=0.9, and β 2 = 0.999 \beta_2 = 0.999 β2=0.999.
Nadam
As we have seen before, Adam can be viewed as a combination of RMSprop and momentum: RMSprop contributes the exponentially decaying average of past squared gradients v t v_t vt, while momentum accounts for the exponentially decaying average of past gradients m t m_t mt. We have also seen that Nesterov accelerated gradient (NAG) is superior to vanilla momentum.
Nadam (Nesterov-accelerated Adaptive Moment Estimation) thus combines Adam and NAG. In order to incorporate NAG into Adam, we need to modify its momentum term m t m_t mt.
First, let us recall the momentum update rule using our current notation :
g t = ∇ θ t J ( θ t ) m t = γ m t − 1 + η g t θ t + 1 = θ t − m t g_t= \nabla_{\theta_t}J(\theta_t)\\ m_t= \gamma m_{t-1} + \eta g_t\\ \theta_{t+1}= \theta_t - m_t gt=∇θtJ(θt)mt=γmt−1+ηgtθt+1=θt−mt
where J J J is our objective function, γ \gamma γ is the momentum decay term, and η \eta η is our step size. Expanding the third equation above yields:
θ t + 1 = θ t − ( γ m t − 1 + η g t ) \theta_{t+1} = \theta_t - ( \gamma m_{t-1} + \eta g_t) θt+1=θt−(γmt−1+ηgt)
This demonstrates again that momentum involves taking a step in the direction of the previous momentum vector and a step in the direction of the current gradient.
NAG then allows us to perform a more accurate step in the gradient direction by updating the parameters with the momentum step before computing the gradient. We thus only need to modify the gradient g t g_t gt to arrive at NAG:
g t = ∇ θ t J ( θ t − γ m t − 1 ) m t = γ m t − 1 + η g t θ t + 1 = θ t − m t g_t= \nabla_{\theta_t}J(\theta_t - \gamma m_{t-1})\\ m_t= \gamma m_{t-1} + \eta g_t\\ \theta_{t+1}= \theta_t - m_t gt=∇θtJ(θt−γmt−1)mt=γmt−1+ηgtθt+1=θt−mt
Dozat proposes to modify NAG the following way: Rather than applying the momentum step twice – one time for updating the gradient g t g_t gt and a second time for updating the parameters θ t + 1 \theta_{t+1} θt+1 – we now apply the look-ahead momentum vector directly to update the current parameters:
g t = ∇ θ t J ( θ t ) m t = γ m t − 1 + η g t θ t + 1 = θ t − ( γ m t + η g t ) g_t= \nabla_{\theta_t}J(\theta_t)\\ m_t= \gamma m_{t-1} + \eta g_t\\ \theta_{t+1}= \theta_t - (\gamma m_t + \eta g_t) gt=∇θtJ(θt)mt=γmt−1+ηgtθt+1=θt−(γmt+ηgt)
Notice that rather than utilizing the previous momentum vector m t − 1 m_{t-1} mt−1 as in the equation of the expanded momentum update rule above, we now use the current momentum vector m t m_t mt to look ahead. In order to add Nesterov momentum to Adam, we can thus similarly replace the previous momentum vector with the current momentum vector. First, recall that the Adam update rule is the following (note that we do not need to modify v ^ t \hat{v}_t v^t):
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m ^ t = m t 1 − β 1 t θ t + 1 = θ t − η v ^ t + ϵ m ^ t m_t= \beta_1 m_{t-1} + (1 - \beta_1) g_t\\ \hat{m}_t = \frac{m_t}{1 - \beta^t_1}\\ \theta_{t+1}= \theta_{t} - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t mt=β1mt−1+(1−β1)gtm^t=1−β1tmtθt+1=θt−v^t+ϵηm^t
Expanding the second equation with the definitions of m ^ t \hat{m}_t m^t and m t m_t mt in turn gives us:
θ t + 1 = θ t − η v ^ t + ϵ ( β 1 m t − 1 1 − β 1 t + ( 1 − β 1 ) g t 1 − β 1 t ) \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} (\dfrac{\beta_1 m_{t-1}}{1 - \beta^t_1} + \dfrac{(1 - \beta_1) g_t}{1 - \beta^t_1}) θt+1=θt−v^t+ϵη(1−β1tβ1mt−1+1−β1t(1−β1)gt)
Note that β 1 m t − 1 1 − β 1 t \dfrac{\beta_1 m_{t-1}}{1 - \beta^t_1} 1−β1tβ1mt−1 is just the bias-corrected estimate of the momentum vector of the previous time step. We can thus replace it with m ^ t − 1 \hat{m}_{t-1} m^t−1:
θ t + 1 = θ t − η v ^ t + ϵ ( β 1 m ^ t − 1 + ( 1 − β 1 ) g t 1 − β 1 t ) \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} (\beta_1 \hat{m}_{t-1} + \dfrac{(1 - \beta_1) g_t}{1 - \beta^t_1}) θt+1=θt−v^t+ϵη(β1m^t−1+1−β1t(1−β1)gt)
Note that for simplicity, we ignore that the denominator is 1 − β 1 t 1 - \beta^t_1 1−β1t and not 1 − β 1 t − 1 1 - \beta^{t-1}_1 1−β1t−1 as we will replace the denominator in the next step anyway. This equation again looks very similar to our expanded momentum update rule above. We can now add Nesterov momentum just as we did previously by simply replacing this bias-corrected estimate of the momentum vector of the previous time step m ^ t − 1 \hat{m}_{t-1} m^t−1 with the bias-corrected estimate of the current momentum vector m ^ t \hat{m}_t m^t, which gives us the Nadam update rule:
θ t + 1 = θ t − η v ^ t + ϵ ( β 1 m ^ t + ( 1 − β 1 ) g t 1 − β 1 t ) \theta_{t+1} = \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} (\beta_1 \hat{m}_t + \dfrac{(1 - \beta_1) g_t}{1 - \beta^t_1}) θt+1=θt−v^t+ϵη(β1m^t+1−β1t(1−β1)gt)
AMSGrad
As adaptive learning rate methods have become the norm in training neural networks, practitioners noticed that in some cases, e.g. for object recognition or machine translation they fail to converge to an optimal solution and are outperformed by SGD with momentum.
Reddi et al. (2018) formalize this issue and pinpoint the exponential moving average of past squared gradients as a reason for the poor generalization behaviour of adaptive learning rate methods. Recall that the introduction of the exponential average was well-motivated: It should prevent the learning rates to become infinitesimally small as training progresses, the key flaw of the Adagrad algorithm. However, this short-term memory of the gradients becomes an obstacle in other scenarios.
In settings where Adam converges to a suboptimal solution, it has been observed that some minibatches provide large and informative gradients, but as these minibatches only occur rarely, exponential averaging diminishes their influence, which leads to poor convergence. The authors provide an example for a simple convex optimization problem where the same behaviour can be observed for Adam.
To fix this behaviour, the authors propose a new algorithm, AMSGrad that uses the maximum of past squared gradients v t v_t vt rather than the exponential average to update the parameters. v t v_t vt is defined the same as in Adam above:
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
Instead of using v t v_t vt (or its bias-corrected version v ^ t \hat{v}_t v^t ) directly, we now employ the previous v t − 1 v_{t-1} vt−1 if it is larger than the current one:
v ^ t = max ( v ^ t − 1 , v t ) \hat{v}_t = \text{max}(\hat{v}_{t-1}, v_t) v^t=max(v^t−1,vt)
This way, AMSGrad results in a non-increasing step size, which avoids the problems suffered by Adam. For simplicity, the authors also remove the debiasing step that we have seen in Adam. The full AMSGrad update without bias-corrected estimates can be seen below:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v ^ t = max ( v ^ t − 1 , v t ) θ t + 1 = θ t − η v ^ t + ϵ m t m_t= \beta_1 m_{t-1} + (1 - \beta_1) g_t \\ v_t= \beta_2 v_{t-1} + (1 - \beta_2) g_t^2\\ \hat{v}_t= \text{max}(\hat{v}_{t-1}, v_t) \\ \theta_{t+1}= \theta_{t} - \dfrac{\eta}{\sqrt{\hat{v}_t} + \epsilon} m_t mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2v^t=max(v^t−1,vt)θt+1=θt−v^t+ϵηmt
The authors observe improved performance compared to Adam on small datasets and on CIFAR-10. Other experiments, however, show similar or worse performance than Adam. It remains to be seen whether AMSGrad is able to consistently outperform Adam in practice. For more information about recent advances in Deep Learning optimization, refer to this blog post.
算法可视化
The following two animations (Image credit: Alec Radford) provide some intuitions towards the optimization behaviour of most of the presented optimization methods. Also have a look here for a description of the same images by Karpathy and another concise overview of the algorithms discussed.
In Image 5, we see their behaviour on the contours of a loss surface (the Beale function) over time. Note that Adagrad, Adadelta, and RMSprop almost immediately head off in the right direction and converge similarly fast, while Momentum and NAG are led off-track, evoking the image of a ball rolling down the hill. NAG, however, is quickly able to correct its course due to its increased responsiveness by looking ahead and heads to the minimum.
Image 6 shows the behaviour of the algorithms at a saddle point, i.e. a point where one dimension has a positive slope, while the other dimension has a negative slope, which pose a difficulty for SGD as we mentioned before. Notice here that SGD, Momentum, and NAG find it difficulty to break symmetry, although the two latter eventually manage to escape the saddle point, while Adagrad, RMSprop, and Adadelta quickly head down the negative slope.

Image 5: SGD optimization on loss surface contours
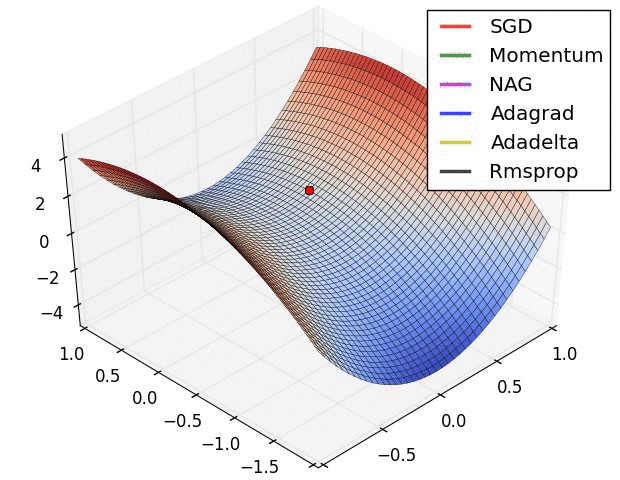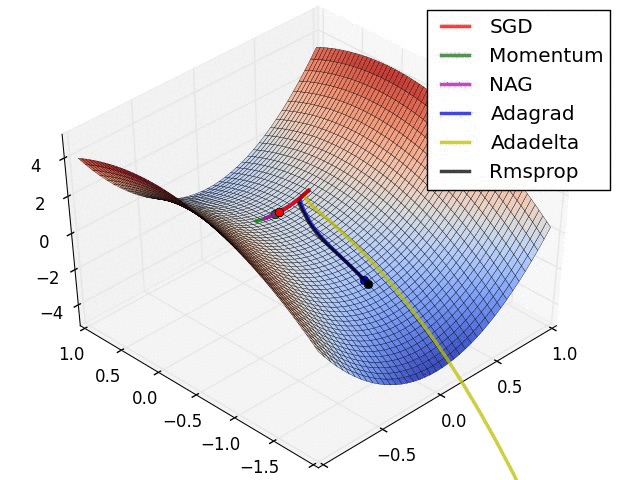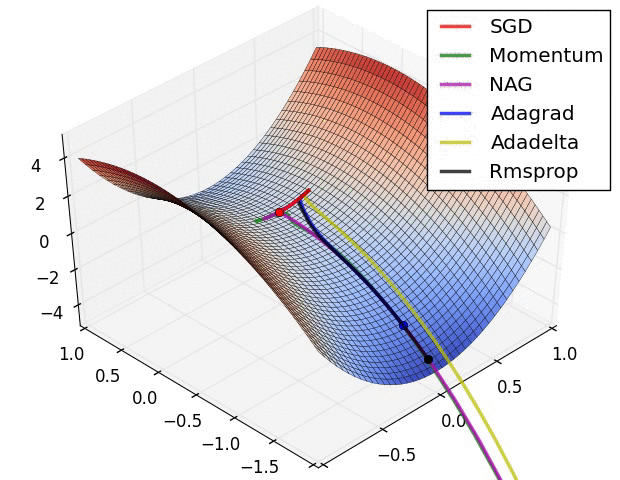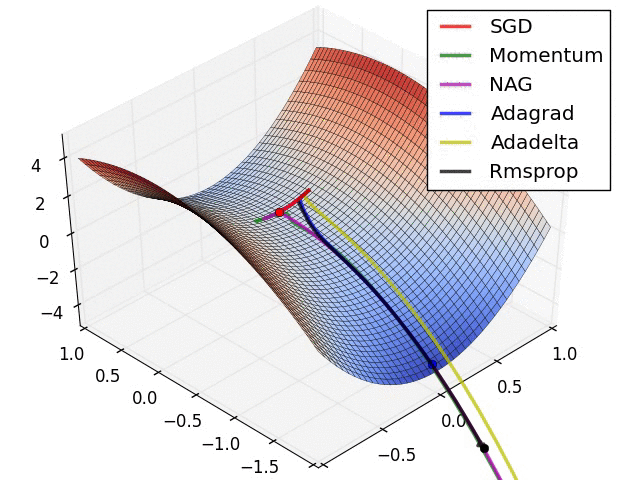
Image 6: SGD optimization on saddle point
As we can see, the adaptive learning-rate methods, i.e. Adagrad, Adadelta, RMSprop, and Adam are most suitable and provide the best convergence for these scenarios.
Note: If you are interested in visualizing these or other optimization algorithms, refer to this useful tutorial.
该使用哪种优化算法?
So, which optimizer should you now use? If your input data is sparse, then you likely achieve the best results using one of the adaptive learning-rate methods. An additional benefit is that you won’t need to tune the learning rate but likely achieve the best results with the default value.
In summary, RMSprop is an extension of Adagrad that deals with its radically diminishing learning rates. It is identical to Adadelta, except that Adadelta uses the RMS of parameter updates in the numinator update rule. Adam, finally, adds bias-correction and momentum to RMSprop. Insofar, RMSprop, Adadelta, and Adam are very similar algorithms that do well in similar circumstances. Kingma et al. show that its bias-correction helps Adam slightly outperform RMSprop towards the end of optimization as gradients become sparser. Insofar, Adam might be the best overall choice.
Interestingly, many recent papers use vanilla SGD without momentum and a simple learning rate annealing schedule. As has been shown, SGD usually achieves to find a minimum, but it might take significantly longer than with some of the optimizers, is much more reliant on a robust initialization and annealing schedule, and may get stuck in saddle points rather than local minima. Consequently, if you care about fast convergence and train a deep or complex neural network, you should choose one of the adaptive learning rate methods.
并行和分布式SGD
Given the ubiquity of large-scale data solutions and the availability of low-commodity clusters, distributing SGD to speed it up further is an obvious choice.
SGD by itself is inherently sequential: Step-by-step, we progress further towards the minimum. Running it provides good convergence but can be slow particularly on large datasets. In contrast, running SGD asynchronously is faster, but suboptimal communication between workers can lead to poor convergence. Additionally, we can also parallelize SGD on one machine without the need for a large computing cluster. The following are algorithms and architectures that have been proposed to optimize parallelized and distributed SGD.
Hogwild!
Niu et al. introduce an update scheme called Hogwild! that allows performing SGD updates in parallel on CPUs. Processors are allowed to access shared memory without locking the parameters. This only works if the input data is sparse, as each update will only modify a fraction of all parameters. They show that in this case, the update scheme achieves almost an optimal rate of convergence, as it is unlikely that processors will overwrite useful information.
Downpour SGD
Downpour SGD is an asynchronous variant of SGD that was used by Dean et al. in their DistBelief framework (predecessor to TensorFlow) at Google. It runs multiple replicas of a model in parallel on subsets of the training data. These models send their updates to a parameter server, which is split across many machines. Each machine is responsible for storing and updating a fraction of the model’s parameters. However, as replicas don’t communicate with each other e.g. by sharing weights or updates, their parameters are continuously at risk of diverging, hindering convergence.
Delay-tolerant Algorithms for SGD
McMahan and Streeter extend AdaGrad to the parallel setting by developing delay-tolerant algorithms that not only adapt to past gradients, but also to the update delays. This has been shown to work well in practice.
TensorFlow
TensorFlow is Google’s recently open-sourced framework for the implementation and deployment of large-scale machine learning models. It is based on their experience with DistBelief and is already used internally to perform computations on a large range of mobile devices as well as on large-scale distributed systems. For distributed execution, a computation graph is split into a subgraph for every device and communication takes place using Send/Receive node pairs. However, the open source version of TensorFlow currently does not support distributed functionality (see here).
Update 13.04.16: A distributed version of TensorFlow has been released.
弹性平均SGD
Zhang et al. propose Elastic Averaging SGD (EASGD), which links the parameters of the workers of asynchronous SGD with an elastic force, i.e. a center variable stored by the parameter server. This allows the local variables to fluctuate further from the center variable, which in theory allows for more exploration of the parameter space. They show empirically that this increased capacity for exploration leads to improved performance by finding new local optima.
优化SGD的其它策略
Finally, we introduce additional strategies that can be used alongside any of the previously mentioned algorithms to further improve the performance of SGD. For a great overview of some other common tricks, refer to.
Shuffling and Curriculum Learning
Generally, we want to avoid providing the training examples in a meaningful order to our model as this may bias the optimization algorithm. Consequently, it is often a good idea to shuffle the training data after every epoch.
On the other hand, for some cases where we aim to solve progressively harder problems, supplying the training examples in a meaningful order may actually lead to improved performance and better convergence. The method for establishing this meaningful order is called Curriculum Learning.
Zaremba and Sutskever were only able to train LSTMs to evaluate simple programs using Curriculum Learning and show that a combined or mixed strategy is better than the naive one, which sorts examples by increasing difficulty.
Batch normalization
To facilitate learning, we typically normalize the initial values of our parameters by initializing them with zero mean and unit variance. As training progresses and we update parameters to different extents, we lose this normalization, which slows down training and amplifies changes as the network becomes deeper.
Batch normalization reestablishes these normalizations for every mini-batch and changes are back-propagated through the operation as well. By making normalization part of the model architecture, we are able to use higher learning rates and pay less attention to the initialization parameters. Batch normalization additionally acts as a regularizer, reducing (and sometimes even eliminating) the need for Dropout.
早停法
According to Geoff Hinton: “Early stopping (is) beautiful free lunch” (NIPS 2015 Tutorial slides, slide 63). You should thus always monitor error on a validation set during training and stop (with some patience) if your validation error does not improve enough.
Gradient noise
Neelakantan et al. add noise that follows a Gaussian distribution N ( 0 , σ t 2 ) N(0, \sigma^2_t) N(0,σt2) to each gradient update:
g t , i = g t , i + N ( 0 , σ t 2 ) g_{t, i} = g_{t, i} + N(0, \sigma^2_t) gt,i=gt,i+N(0,σt2)
They anneal the variance according to the following schedule:
σ t 2 = η ( 1 + t ) γ \sigma^2_t = \dfrac{\eta}{(1 + t)^\gamma} σt2=(1+t)γη
They show that adding this noise makes networks more robust to poor initialization and helps training particularly deep and complex networks. They suspect that the added noise gives the model more chances to escape and find new local minima, which are more frequent for deeper models.
结论
In this blog post, we have initially looked at the three variants of gradient descent, among which mini-batch gradient descent is the most popular. We have then investigated algorithms that are most commonly used for optimizing SGD: Momentum, Nesterov accelerated gradient, Adagrad, Adadelta, RMSprop, Adam, as well as different algorithms to optimize asynchronous SGD. Finally, we’ve considered other strategies to improve SGD such as shuffling and curriculum learning, batch normalization, and early stopping.
I hope that this blog post was able to provide you with some intuitions towards the motivation and the behaviour of the different optimization algorithms. Are there any obvious algorithms to improve SGD that I’ve missed? What tricks are you using yourself to facilitate training with SGD? Let me know in the comments below.