软件架构设计常用方法-软件架构设计学习第五天(非原创)
文章大纲
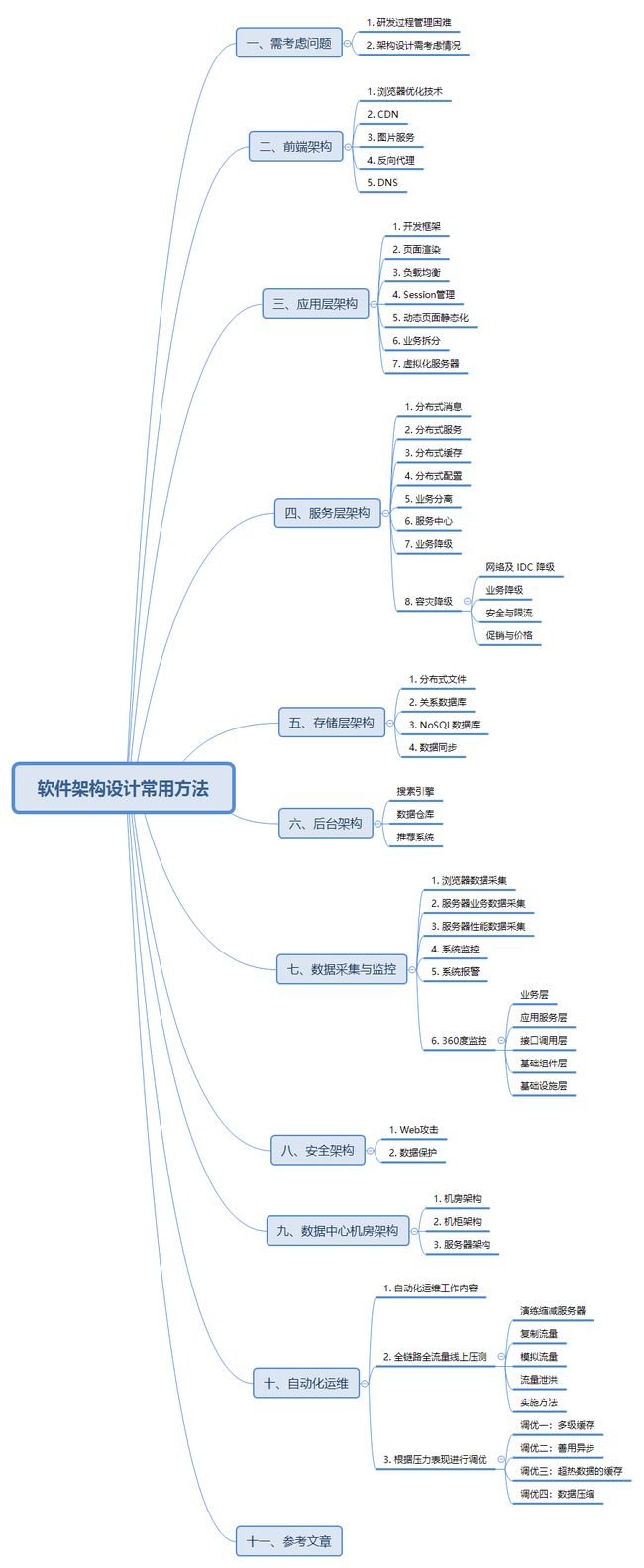
一、需考虑问题
二、前端架构
三、应用层架构
四、服务层架构
五、存储层架构
六、后台架构
七、数据采集与监控
八、安全架构
九、数据中心机房架构
十、自动化运维
十一、参考文章
一、需考虑问题
1. 研发过程管理困难
(1)依赖管理,每个模块对其他模块的依赖是管理困难的;
(2)版本管理;
(3)部署管理(搭火车,难以触达到用户);
(4)模块组织方式(库工程,源代码级别,没有权限)。
(5)构建打包痛苦:可能不能打包(2.x安装不上),合并代码搞了很久,编译打包时间过长。
2. 架构设计需考虑情况
(1)业务分级、核心、非核心业务隔离
(2)多机房部署,流量分流、容灾冗余、峰值应对冗余
(3)读库多源,失败自动转移
(4)写库主备,短暂有损服务容忍下的快速切换
(5)外部接口,失败转移或快速断路
6.Redis 主备,失败转移
7.大表迁移,MongoDB 取代 MySQL 存储消息记录
8.改进消息投递模型
二、前端架构
前端指用户请求到达网站应用服务器之前经历的环节,通常不包含网站业务逻辑,不处理动态内容。
1. 浏览器优化技术
并不是优化浏览器,而是通过优化响应页面,加快浏览器页面的加载和显示,常用的有页面缓存、合并HTTP减少请求次数、使用页面压缩等。
2. CDN
内容分发网络,部署在网络运营商机房,通过将静态页面内容分发到离用户最近最近的CDN服务器,使用户可以通过最短路径获取内容。
动静分离,静态资源独立部署
静态资源,如JS、CSS等文件部署在专门的服务器集群上,和Web应用动态内容服务分离,并使用专门的(二级)域名。
3. 图片服务
图片不是指网站Logo、按钮图标等,这些文件属于上面提到的静态资源,应该和JS、CSS部署在一起。这里的图片指用户上传的图片,如产品图片、用户头像等,图片服务同样适用独立部署的图片服务器集群,并使用独立(二级)域名。
4. 反向代理
部署在网站机房,在应用服务器、静态资源服务器、图片服务器之前,提供页面缓存服务。
5. DNS
域名服务,将域名解析成IP地址,利用DNS可以实现DNS负载均衡,配置CDN也需要修改DNS,使域名解析后指向CDN服务器。
三、应用层架构
应用层是处理网站主要业务逻辑的地方。
1. 开发框架
网站业务是多变的,网站的大部分软件工程师都是在加班加点开发网站业务,一个好的开发框架至关重要。一个号的开发框架应该能够分离关注面,使美工、开发工程师可以各司其事,易于协作。同时还应该内置一些安全策略,防护Web用攻击。
2. 页面渲染
将分别开发维护的动态内容和静态页面模板集成起来,组合成最终显示给用户的完整页面。
3. 负载均衡
将多台应用服务器组成一个集群,通过负载均衡技术将用户请求分发到不同的服务器上,以应对大量用户同时访问时产生的高并发负载压力。
4. Session管理
为了实现高可用的应用服务器集群,应用服务器通常设计为无状态,不保存用户请求上下文信息,但是网站业务通常需要保持用户会话信息,需要专门的机制管理Session,使集群内甚至跨集群的应用服务器可以共享Session。
5. 动态页面静态化
对于访问量特别大而更新又不很频繁的动态页面,可以将其静态化,即生成一个静态页面,利用静态页面的优化手段加速用户访问,如反向代理、CDN、浏览器缓存等。
6. 业务拆分
将复杂而庞大的业务拆分开来,形成多个规模较小的产品,独立开发、部署、维护,除了降低系统耦合度,也便于数据库业务分库。按业务对关系数据库进行拆分,技术难度相对较小,而效果又相对较好。
7. 虚拟化服务器
将一台物理服务器虚拟化成多态虚拟服务器,对于并发访问较低的业务,更容易用较少的资源构架高可用的应用服务器集群。
四、服务层架构
提供基础服务,供应用层调用,完成网站业务。
1. 分布式消息
利用消息队列机制,实现业务和业务、业务和服务之间的异步消息发送及低耦合的业务关系。
2. 分布式服务
提供高性能、低耦合、易复用、易管理的分布式服务,在网站实现面向服务架构(SOA)。
3. 分布式缓存
通过可伸缩的服务器集群提供大规模热点数据的缓存服务,是网站性能优化的重要手段。
4. 分布式配置
系统运行需要配置许多参数,如果这些参数需要修改,比如分布式缓存集群加入新的缓存服务器,需要修改应用程序客户端的缓存服务器列表配置,并重启应用程序服务器。分布式配置在系统运行期提供配置动态推送服务,将配置修改实时推送到应用系统,无需重启服务器。
5. 业务分离
系统把所有的功能都包含了,比如说登录、注册、参数下发、消息、日志、更新。
其实对于玩家来玩游戏来说,真正强相关的只有登录注册和参数下发,消息和日志、更新其实并不是玩家玩游戏必须具备或者强相关的。
所以,业务分离的做法就是把核心业务和非核心业务分拆到不同的系统中,把两个系统之间通过接口调用,互相访问。
这样做的好处,假设非核心业务系统出现故障,它并不影响核心业务系统,因为它们之间是通过接口调用的,并不共享相同的资源。
6. 服务中心
服务中心类似于DNS,是实现整个内部系统之间服务调用时候的调度功能,服务中心是一个类似于服务的名字系统。
比如说有一个A业务想访问其他系统提供的业务。它首先并不是直接访问到另外一个系统,而是要到服务中心访问一下。
比如说我需要X服务,服务中心告诉A:你去访问Host1+port1的xxx接口。服务中心有一个配置和状态上报,可以根据一些状态、算法、配置,选择一个最优秀的服务器告诉A业务。
那么,A业务收到之后就按照这个指示去访问真正提供业务的机器,比如B系统里的Host1+ port1这个机器。服务中心的作用跟HTTP-DNS的作用差不多,就是希望在内部某个系统故障的时候可以快速处理或者切换。
假设B系统某台机器有问题了,我们可以通过自动或者人工的方式在服务中心把这台机器直接下掉,A业务请求的时候,它就不会再请求到这个有问题的机器上,这一台机器的故障就不影响A业务。
7. 业务降级
整个系统拆分成核心业务系统和非核心业务系统,在一些紧急情况下,比如说非核心业务系统重启也没有办法,甚至说某个数据库搞挂了,它又影响业务核心系统。
这个时候,接口是可以访问的,但是响应时间特别慢,核心系统就有点被拖慢。
那么,在这种比较极端的情况下,我们可以通过人工的方式下发降级指令,把这个非核心业务系统的功能给停掉,这个停掉并不是把程序停掉,而是说把其中的一个接口或者url停掉,核心系统去访问的时候就得到一个500或者503错误。
我们做了一个专门的降级系统,降级系统可以去下发这些降级指令。一般情况下由降级系统给非核心业务系统下发降级指令,如果到了一些关键时刻,其实核心业务系统中有的接口也是可以进行降级的。
也就是说,我们降级的时候并不是对整个系统或者整个功能进行降级,我们可以做到接口或者url这个级别的降级。通过牺牲非核心业务系统的功能,我们尽最大努力地去保证核心业务系统提供的业务。
这个业界有很多叫法,比如有损服务、可损服务,其实我们这个也是一个可损服务,功能上的可损,不是流量上的可损。
8. 容灾降级
如果分流、限流还没抗住,系统进一步出现压力问题,再要做准备做容灾降级。
容灾降级有机房容灾,我们做多中心机房,网络容灾、内网外网的容灾,应用的容灾,分组、托底容器,最后保证基础的服务是正常的。
网络及 IDC 降级
这是容灾降级,这是网络大概示意图。我们的 ISP 进入机房,核心交换机、柜顶交换机、这是交换级的容灾,网络共享容灾。
业务降级
购物车结算页的降级,当订单出现过大,延保服务、预约服务如果不行,直接保主流层,就属于业务层面的降级。
安全与限流
我们假设系统当超过一定流量后,超过的流量做直接拒绝处理,以便保护后端的服务,这就是限流。
Web 的限流根据 PIN 来限流,这是根据 IP 加 PIN 风控数据限流,这一块根据业务逻辑,一个单一天能下多少单,根据这个逻辑去限流。渠道可以按 App、PC、微信等分开,分流和限流这么做。
下面讲秒杀系统是怎么来的。秒杀系统是限流和分流的典型。
秒杀,假设预约是 1500 万,在那一分钟之内,这么多用户过来抢手机,也就是单个商品,就把流量直接导到秒杀系统。
秒杀系统从 Ngnix 进来就有各种的限制,到我们会识别用户供应商或者商贩去刷的数据,这块调用是从正常访问的单品页分出来,不影响主流程。
通过 IP、PIN、每一步怎么来、用户以提交记录,一秒钟提交多少次,一分钟提交多少次等一堆的规则做判断来限流。到最后再验证有没有预约、常用地址服务等,都通过后再调到接单系统。
整个秒杀系统就是一个典型的沙漏的系统,当流量跑到后面,实际上只剩很小的一部分,只有真实的写流量到接单。
接单提交服务单独出来两台机器给它用,后面的存储得到保护,两台机器最多也就几十万,也能承载住,这就是分流跟限流。
促销与价格
促销里面也有一个限购,比如前 30 个用户享受促销,发一个码出去,需要对这个码进行处理,这是一种限流。
促销分流中需要把价格服务单拎出来,分出去,单品页搜索,手机微信,购物车的架构从这里出来,最实时的价格。这样产生分流,这一块有一个存储分流,还有更多其它的就没有一一列举,这只是一个示意图。
这就是我们整个的分流跟限流。根据前面的渠道,调用量、做多少程度,相对于影响力,做分流和限流。
五、存储层架构
提供数据、文件的持久化存储访问与管理服务。
1. 分布式文件
网站在线业务需要存储的文件大部分都是图片、网页、视频等比较小的文件,但是这些文件的数量非常庞大,而且通常都在持续增加,需要伸缩性设计比较好的分布式文件系统。
2. 关系数据库
大部分万丈的主要业务是基于关系数据库开发的,但是关系数据库对集群伸缩性的支持表较差。通过在应用程序的数据访问层增加数据库访问的路由功能,根据业务配置将数据库访问路由到不同的物理数据库上,可实现关系数据库的分布式访问。
3. NoSQL数据库
目前各种NoSQL数据库层出不穷,在内存管理、数据模型、集群分布式管理等方面各有优势,不过从社区活动性角度看,HBase无疑是目前最好的。
4. 数据同步
在支持全球范围内数据共享的分布式数据库技术成熟之前,拥有多个数据中心的网站必须在多个数据中心之间进行数据同步,以保证每个数据中心都拥有完整的数据。在实践中,为了减轻数据库压力,将数据库的事物日志(或者NoSQL的写操作Log)同步到其他数据中心,根据Log进行数据重演,实现数据同步。
六、后台架构
网站应用中,除了要处理用户的实时访问请求外,还有一些后台非实时数据分析要处理。
搜索引擎
即使是网站内部的搜索引擎,也需要进行数据增量更新及全量更新、构建索引等。这些操作通过后台系统定时执行。
数据仓库
根据离线数据,提供数据分析与数据挖掘服务。
推荐系统
社交网站及购物网站通过挖掘人与人之间的关系,人和商品之间的关系,发展潜在的人际关系和购物兴趣,为用户提供个性化推荐服务。
七、数据采集与监控
监控网站访问情况与系统运行情况,为网站运营决策和运维管理提供支持保障。
1. 浏览器数据采集
通过在网站页面中嵌入JS脚本采集用户浏览器环境与操作记录,分析用户行为。
2. 服务器业务数据采集
服务器业务数据包括两种,一种是采集在服务器端记录的用户请求操作日志;一种是采集应用程序运行期业务数据,比如待处理消息数目等。
3. 服务器性能数据采集
采集服务器性能数据,如系统负载、内存使用率、网卡流量等。
4. 系统监控
将前述采集的数据以图表的方式展示,以便运营和运维人员监控网站运行状况,做到这一步仅仅是系统监视。更先进的做法是根据采集的数据进行自动化运维,自动处理系统异常状况,是吸纳自动化控制。
5. 系统报警
如果采集来的数据超过预设的正常情况的阀值,比如系统负载过高,就通过邮件、短信、语音电话等方式发出警报信号,等待工程师干预。
6. 360度监控
整体方案从上到下分为五层:业务层、应用服务层、接口调用层、基础组件层、基础设施层。
(1)业务层:就是我们业务上的打点,根据这些打点进行机型统计或者分析;
(2)应用服务层:简单来说就是我们url的一个访问情况;
(3)接口调用层:就是我们自己系统对外部依赖的那些接口的访问情况,比如A系统调用B系统的一个接口,在A系统里统计或者监控调用B系统接口的情况,包括时延、错误次数之类;
(4)基础组件层:其实就是我们使用的一些组件,包括MySQL等;
(5)基础设施层:就是最底层的,包括操作系统、网络、磁盘、IO这些设备。
整个监控是分层的,在我们出现问题的时候,定位问题需要的关键信息全部包括在这里面的。
八、安全架构
保护网站免遭攻击及敏感信息泄露。
1. Web攻击
以HTTP请求的方式发起的攻击,危害最大的就是XSS和SQL注入攻击。但是只要措施得当,这两种攻击都是比较容易防范的。
2. 数据保护
敏感信息加密传输与存储,保护网站和用户资产。
九、数据中心机房架构
大型网站需要的服务器规模数以十万计,机房物理架构也需要关注。
1. 机房架构
对于一个拥有十万台服务器的大型网站,每台服务器耗电(包括服务器本身耗电及空调耗电)每年大约需要人民币2000元,那么网站每年机房电费就需要两亿人民币。数据中心能耗问题日趋严重,Google、Facebook选择数据中心地理位置的时候趋向选择散热良好,供电充裕的地方。
2. 机柜架构
包括机柜大小,网线布局、指示灯规格、不间断电源、电压规格(是48V直流电还是220V民用交流电)等一系列问题。
3. 服务器架构
大型网站由于服务器采购规模庞大,大都采用定制服务器的方式代替购买服务器整机。根据网站应用需求,定制硬盘、内存、甚至CPU,同时去除不必要的外设接口(显示器输出接口,鼠标、键盘输入接口),并使空间结构利于散热。
十、自动化运维
1. 自动化运维工作内容
(1)硬件和网络的自动管理
(2)云化、虚拟机的自动管理
(3)操作系统和软件的自动化安装、配置
(4)常规任务(健康检查、安全加固和检查、备份、清理、数据管理、弹性伸缩等)
(5)手工任务(容灾切换、应急操作、应用部署和起停……)
(6)监控
(7)问题诊断
(8)可视化
2. 全链路全流量线上压测
压测分为线上压测、线下压测,主力做线上压测。
为什么我们会采用线上压测?早年我们只做线下压测,环境跟线上不一样,路由器和机器 CPU,物理机,每一个不相同或者架设的路由超过 3 层,丢包,各种数据不一样,压测出来的数据经常会差异。
线上压测分开是怎么样做的?需要将读业务跟写业务区分开。读业务,我们正常可以看到读价格读库存、读购物车场景的分开,读跟写,看到购物车上的分布,就能知道是读还是写。
演练缩减服务器
从压测上,在集群中将服务器缩减,因为我们支撑的量,最高量达到 1 分钟达到 1 亿左右,平常最少有几十万、几百万的量。集群肯定是比较大的,最少也是几十台的机器,我们会把集群机器逐台往下缩减,真正看到线上量能扛到什么情况。
做到这儿,大家会有疑问?风险挺大。对,风险的确挺大,比如一个集群的 30 台机器一个一个往下缩,比如缩到 5 台,如果扛不住,所有的机器就崩溃,就会面临很大风险。所以梳理完每个架构之后,每年我们冒着风险,找到这个点,往上一点的量进行缩减,缩到一定程度再强行缩。
复制流量
主要通过 TCPCopy 复制端口流量,多层翻倍放大流量。如下图就直接将每层流量翻倍整体就是 1,000 倍,工具实现简单,可以实现多条线组合进行流量复制。通过这种方式发起超负荷的请求,检验服务能够承载的容量。
模拟流量
我们做了一个成立了一个压力小组,线上压力测试小组,我们做线上压测。用非常简单的底层工具去做压测。底层发起的量特别快而且特别多,集群,我们只做了压测平台,把这些工具集成起来做模拟流量压测。
在数据模拟上,我们是自己事先会准备一批数据。比如说几万个用户,几万个 SKU。商家各种库存模式,促销模式,在模拟平台我们会准备好。
流量泄洪
我们把订单在这个结构,接住堵在这个地方不往下放,往后拽都是密集的一些服务。从这一块把量堵住,堵几十万,突然有一天打开,看到一个峰值,看每一分钟处理量,往后能承受多大量,是不是能够承受发起的量,
实施方法
大家可能在朋友圈看到照片,各个服务的核心人员,集中在一个会议室,进行压测。一步一步往上加量,严密监控线上响应情况、订单量情况、各个服务器,以及各个缓存、数据库等机器的实际负载情况。出现任何风吹草动就停止发起压力,并进行记录和排查问题。
然后压测订单提交,往主集群写数据。跟购物车不同,这种压测会直接在生成集群上进行压测,并会写入数据。因此需要将写入数据进行隔离操作,并将垃圾数据进行数据删除,不能进入生产环境。
根据业务和技术维度筛选一批商品、一批用户,主要覆盖存储分布、用户每个等级以及业务分支。促销组帮忙建立能覆盖所有环节的促销数据。将这些用户的提交订单后清空购物车的功能禁用,保证能不停的重复下单。另外这些用户的订单提交流程中的邮件、短信提醒等相关功能禁用,产生的订单进行隔离,不往生产系统下发,并在测试完成后进行删除。
线上压测时,组织各个相关组核心人员严密监控各项数据。出现问题立即停止压测。先进行恢复,同时进行数据记录和问题排查,如分钟级无法恢复则直接切亦庄备用集群。
每个服务分别进行一轮压测,记录每个服务和购物车、订单提交压测得出的数据。根据线上实际用户调用比例进行换算,得出一个相对精准的整体集群承载数据。
订单生产后系统,主要用憋单,快速释放流量进行压测。形成对整个后续系统的,持续性高流量冲击,得出整体系统的处理订单能力。
通过压测,就知道目前京东系统,压测完能承受多大量,面临我们目标差距有多少?压测完之后,我们就要运维优化。
在打压时候,我们按照交易系统的流量分布来模拟流量,比如正常访问购物车与结算页是 16 :4 的流量,下图的在打压时候我们也严格按照这个流量来执行,确保压力接近大促时候的真实访问场景。
3. 根据压力表现进行调优
调优一:多级缓存
缓存从前面比较多,CDN、Nginx、Java 都会有缓存。
缓存是逐级往下做,是一个漏斗状,最开始做缓存,到缓存的持续性在很短的时间内,一分钟或者一秒钟或者毫秒,这样给用户的感知是看不到缓存的,如果你要承载这么大量,必须逐级做缓存,前面做一些静态缓存掉,后面会做一些基础数据缓存,最后大数据,一层一层往上能挡住整个这一块,
调优二:善用异步
这是购物车大概的结构。这里有一个异步双写,我们会写丢这个数据,写丢没关系,我们购物车是整体的,加一个商品,写不过来,下次过来又会全覆盖。这样购物车就有一个多机房多活的可用性。
调优三:超热数据的缓存
购物车里面做热数据缓存,这种数据的缓存,比如促销服务直接影响到价格,缓存效率必须是在秒级毫秒级,在一秒钟怎么筛选十亿商品里面最热的商品?
我们利用 Queue 的原理,不断往里塞 SKU,队列的长只有 50。传进来之后,这里有的位置往前移,我们很快知道在一秒钟知道,排在前面肯定是访问次数最多的,每一个阶段应用存储访问最多的数据,如果是秒杀商品,500 万的请求有十万到二十万,它肯定大部分的请求在这块就出去了,不会穿透进来,这是我们自己做的热数据缓存。
调优四:数据压缩
对 Redis 存储的数据进行压缩,这样空间又缩小四分之一或是三分之一,我们数据到后面就会很小。当量小之后,访问效率就会升高,你数据量弹出很小,丢单率很小,可以提高我们的可用性。
十一、参考文章
-
- https://mp.weixin.qq.com/s?__biz=MzA4Nzg5Nzc5OA==&mid=2651660980&idx=1&sn=640c3d2280d7657f236434ff6ba0b22b#rd
- https://my.oschina.net/xianggao/blog/524943
- https://mp.weixin.qq.com/s/Sql4w39tiMq3Fu9JnqC2fQ
- https://www.cnblogs.com/mindwind/p/5017591.html
- http://www.hollischuang.com/archives/1132
- https://mp.weixin.qq.com/s?__biz=MzAwMDU1MTE1OQ==&mid=2653547431&idx=1&sn=744a42639e7c362a05aacbfbed6a988c&scene=0
- https://mp.weixin.qq.com/s/oN2RfufF4Tex25MxqJuwpA
- https://mp.weixin.qq.com/s/ryYSyil2Gu9DaZ14QpDUUA
- https://mp.weixin.qq.com/s/ryYSyil2Gu9DaZ14QpDUUA
I hate being alone,but I'm afraid I won't get married early