redis 集群 Redis-Cluster 集群环境搭建 分布式 jedis java客户端操作redis
redis
概念
是一个开源的使用ANSI C语言编写,遵守BSC协议(BSC协议:简单说就是为所欲为协议,它给予使用者很大的自由,可以使用、修改,并且可以将修改后的代码作为开源或专业软件再发布)支持网络数据库,基于内存亦可持续化的日志型、key-value的数据库。并且提供了各种语言的API的非关系型数据库
非关系型数据库
Nosql 是not Only Sql的缩写,是对不同于关系型数据库的统称。和关系型数据库是互补关系
一般使用再分布式系统,遵循CAP定理:CAD是分布式系统中的一致性,可用型,分区容错性。CAP的原则是,三个要素最多只能同时实现两点,不可能三者兼得。
使用场景
- 缓存数据
缓存热帖
缓存文章详细信息
记录用户会话信息
-记录帖子点赞数、评论数、转发量等
redis集群
1.集群与分布式概述
1.1.分布式优化
分布式是指将不同的业务分布在不同的地方(集群). web应用和数据库服务分开.
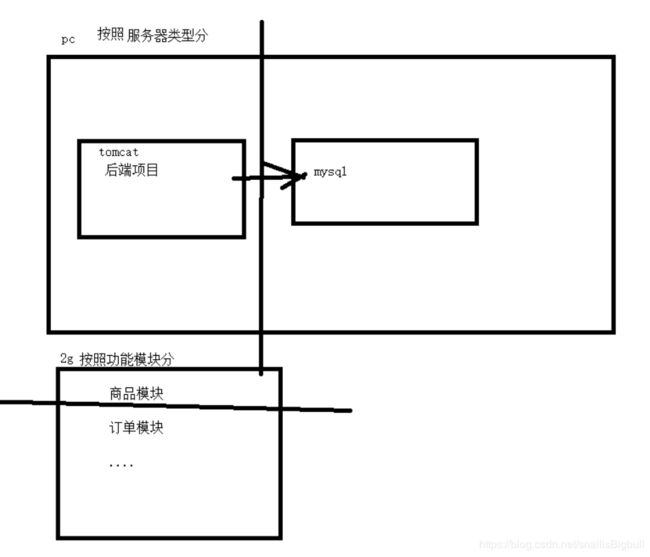
将不同业务分布到不同集群.
集群优化
集群指的是将多台服务器集中在一起,实现同一业务。 数据库集群和应用集群和功能集群

1)两大关键特性
集群提供了以下两个关键特性:
1、可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。动态添加服务器
2、高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。在集群中,同样的服务可以由多个服务实体提供。如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。集群提供的从一个出错的服务实体恢复到另一个服务实体的功能增强了应用的可用性
当访问的服务器挂了时,集群要有能力找可以正常使用额服务器继续提供服务器。
2)两大能力
为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力:
1、负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
2、错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
当访问的服务器挂了时,集群要有能力找可以正常使用额服务器继续提供服务器。
负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的
分布式和集群相同点和不同点?
相同点:
都是处理高并发,而且都需要多台服务器协同.一把在一个系统中同时存在分布式和集群.
不同点:
分布式中不同服务器处理是不同业务.而集群处理时同一业务.
2.2.Redis集群方案选择
2.2.1.为什么redis要做集群
1)防止单点故障
2)处理高并发-太多请求一台服务器搞不定
3)处理大量数据-太多内存数据一台服务器搞不定
2.2.2.方案1 主从复制
原理:
从服务器连接主服务器,发送SYNC命令;
主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;(从服务器初始化完成)
主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令(从服务器初始化完成后的操作)
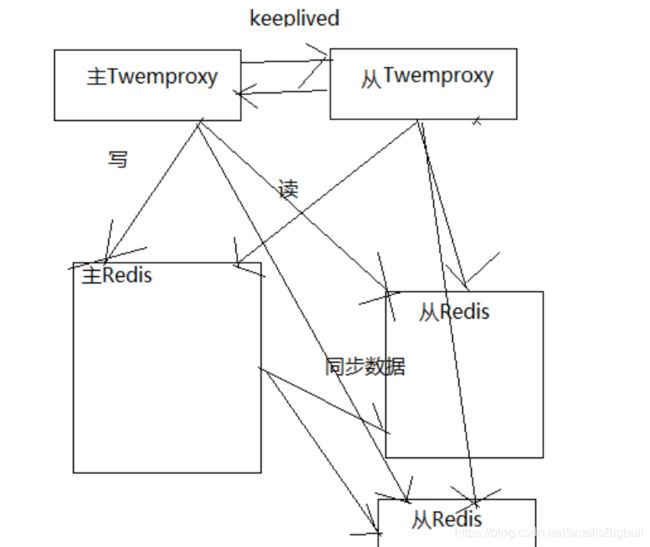
主从同步,读写分离,主备切换.
优缺点:
优点:
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离
为了分载Master(主)的读操作压力,Slave(从)服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成
Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据
缺点:
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
只解决高并发
2.2.3.方案2 哨兵模式
当主服务器中断服务后,可以将一个从服务器升级为主服务器,以便继续提供服务,但是这个过程需要人工手动来操作。 为此,Redis 2.8中提供了哨兵工具来实现自动化的系统监控和故障恢复功能。
哨兵的作用就是监控Redis系统的运行状况。它的功能包括以下两个。
(1)监控主服务器和从服务器是否正常运行。
(2)主服务器出现故障时自动将从服务器转换为主服务器。
哨兵的工作方式:
每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的Master主服务器,Slave从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
如果一个Master主服务器被标记为主观下线(SDOWN),则正在监视这个Master主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认Master主服务器的确进入了主观下线状态
当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认Master主服务器进入了主观下线状态(SDOWN), 则Master主服务器会被标记为客观下线(ODOWN)
在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有Master主服务器、Slave从服务器发送 INFO 命令。
当Master主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master主服务器的所有 Slave从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master主服务器的客观下线状态就会被移除。若 Master主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
哨兵模式的优缺点
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
主从可以自动切换,系统更健壮,可用性更高。
缺点:
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂
方案3 Redis-Cluster集群(采纳)
redis的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台redis服务器都存储相同的数据,很浪费内存,所以在redis3.0上加入了cluster模式,实现的redis的分布式存储,也就是说每台redis节点上存储不同的内容。
Redis-Cluster采用无中心结构,它的特点如下:
所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
节点的fail是通过集群中超过半数的节点检测失效时才生效。
客户端与redis节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
在redis的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是cluster,可以理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
为了保证高可用,redis-cluster集群引入了主从模式,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点ping一个主节点A时,如果半数以上的主节点与A通信超时,那么认为主节点A宕机了。如果主节点A和它的从节点A1都宕机了,那么该集群就无法再提供服务了。
Redis-Cluster介绍
2.3.1.什么是Redis-Cluster
为何要搭建Redis集群。Redis是在内存中保存数据的,而我们的电脑一般内存都不大,这也就意味着Redis不适合存储大数据,适合存储大数据的是Hadoop生态系统的Hbase或者是MogoDB。Redis更适合处理高并发,一台设备的存储能力是很有限的,但是多台设备协同合作,就可以让内存增大很多倍,这就需要用到集群。
Redis集群搭建的方式有多种,例如使用客户端分片、Twemproxy(读写分离)、Codis等,但从redis 3.0之后版本支持redis-cluster集群,它是Redis官方提出的解决方案,Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接。其redis-cluster架构图如下:
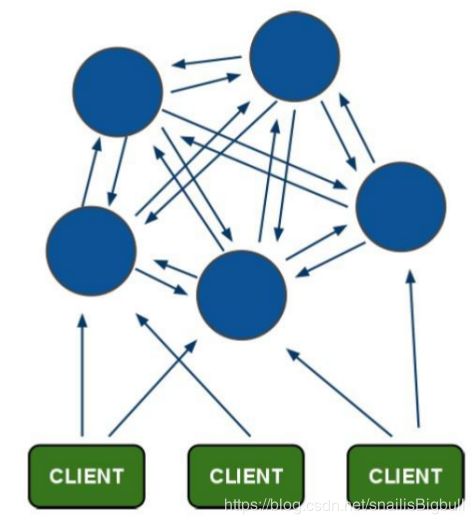
客户端与 redis 节点直连,不需要中间 proxy 层.客户端不需要连接集群所有节点连接集群中任何一个可用节点即可。
所有的 redis 节点彼此互联(PING-PONG 机制),内部使用二进制协议优化传输速度和带宽.
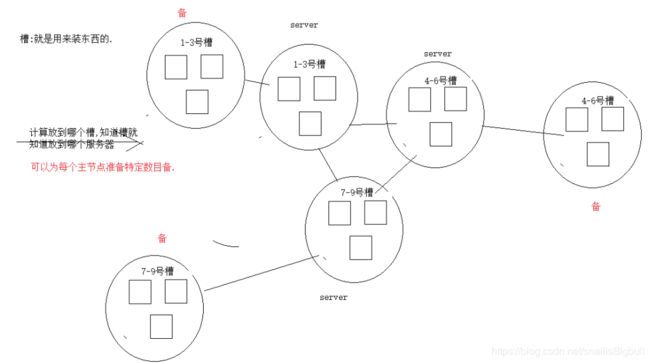
2.3.2.分布存储机制-槽
redis-cluster 把所有的物理节点映射到[0-16383]slot 上,cluster 负责维护
node<->slot<->value
(2)Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
例如三个节点:槽分布的值如下:
SERVER1: 0-5460
SERVER2: 5461-10922
SERVER3: 10923-16383
2.3.3.容错机制-投票
(1)选举过程是集群中所有master参与,如果半数以上master节点与故障节点通信超过(cluster-node-timeout),认为该节点故障,自动触发故障转移操作. 故障节点对应的从节点自动升级为主节点
(2)什么时候整个集群不可用(cluster_state:fail)?
如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态.

集群环境搭建
参考https://blog.csdn.net/weixin_41846320/article/details/83654766
2.4.1.要求
1)Redis 3.2
需要 6 台 redis 服务器。搭建伪集群。
需要 6 个 redis 实例。
需要运行在不同的端口 6379-6384
2)Ruby语言运行环境 我们需要使用ruby脚本来实现集群搭建
Ruby,一种简单快捷的面向对象(面向对象程序设计)脚本语言,在20世纪90年代由日本人松本行弘(Yukihiro Matsumoto)开发,遵守GPL协议和Ruby License。它的灵感与特性来自于 Perl、Smalltalk、Eiffel、Ada以及 Lisp 语言。由 Ruby 语言本身还发展出了JRuby(Java平台)、IronRuby(.NET平台)等其他平台的 Ruby 语言替代品。Ruby的作者于1993年2月24日开始编写Ruby,直至1995年12月才正式公开发布于fj(新闻组)。因为Perl发音与6月诞生石pearl(珍珠)相同,因此Ruby以7月诞生石ruby(红宝石)命名
3)RubyGems简称gems,是一个用于对 Ruby组件进行打包的 Ruby 打包系统
4)Redis的Ruby驱动redis-xxxx.gem
5)创建Redis集群的工具redis-trib.rb
2.4.2.所需软件
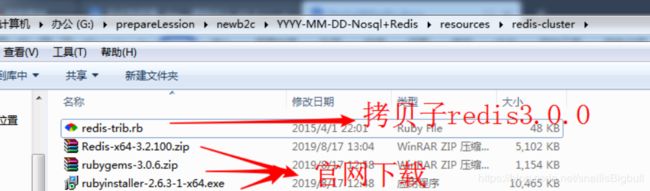
2.4.3.搭建
要让集群正常运作至少需要3个主节点,建议配置3个主节点,其余3个作为各个主节点的从节点(也是官网推荐的模式)。同一台电脑,不同端口模拟
1)安装并拷贝6个服务器
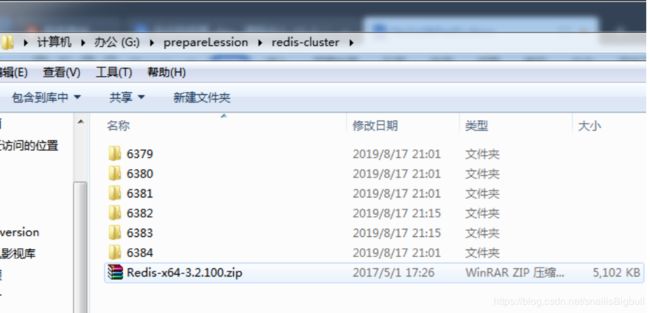
2)进行配置
打开每个Redis目录下的文件 redis.windows.conf,修改里面的端口号分别对应相对应的文件夹名:6379、6380、6381、6382、6383、6384。
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
appendonly yes
cluster-config-file nodes-6379.conf 是为该节点的配置信息,这里使用 nodes-端口.conf命名方法。服务启动后会在目录生成该文件。
3)编写启动脚本,或者进入每个端口命名的文件夹下启动服务
方便启动
编写一个 bat 来启动 redis,在每个节点目录下建立 startup.bat,内容如下:
title redis-6379
redis-server.exe redis.windows.conf
title命名规则 redis-相对应的端口。
4)安装Ruby
redis的集群使用 ruby脚本编写,所以系统需要有 Ruby 环境
![]()

5)安装Redis的Ruby驱动redis-xxxx.gem
下载地址 https://rubygems.org/pages/download
下载后解压,当前目录切换到解压目录中,如 D:\Program Files\Redis_cluster\rubygems-2.7.7 然后命令行执行
ruby setup.rb
再用 GEM 安装 Redis :切换到redis安装目录,需要在命令行中,执行 gem install redis
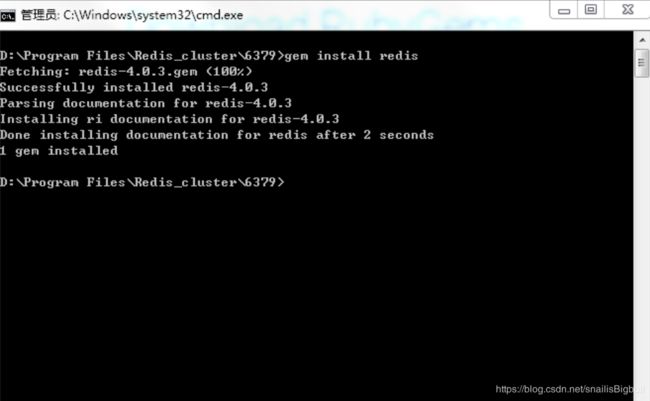
6)启动每个节点并且执行集群构建脚本
点击每个节点start.bat进行启动
拷贝redis-trib.rb到redis节点
执行命令
redis-trib.rb create --replicas 1 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384
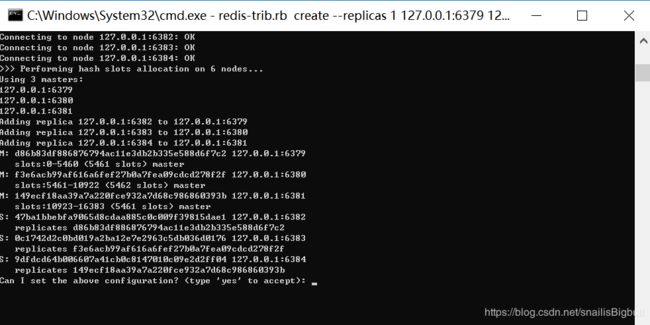
在出现 Can I set the above configuration? (type ‘yes’ to accept): 请确定并输入 yes 。成功后的结果如下:
在这里插入图片描述
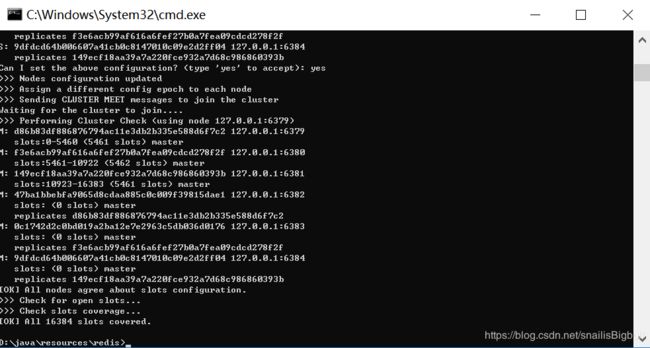
注意事项:
1)现在是windows搭建的,以后再linux.只是redis安装与启动不一样其他都是一样的.
2)5.0以上版本兼容
如果出现 redis-trib.rb is not longer available! 如果redis版本是5.0以上,则使用如下命令:
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6380 127.0.0.1:6381 12
1:6382 127.0.0.1:6383 127.0.0.1:6384 --cluster-replicas 1
原因是redis5.0以上不再需要redis-trib.rb了,而是使用自带的redis-cli作为创建集群的命令了。
2.5.集群环境测试
2.5.1.命令测试 redis-cli
使用Redis客户端Redis-cli.exe来查看数据记录数,以及集群相关信息
命令 redis-cli –c –h ”地址” –p “端口号” ; c 表示集群

1)查看集群的信息,命令:cluster info
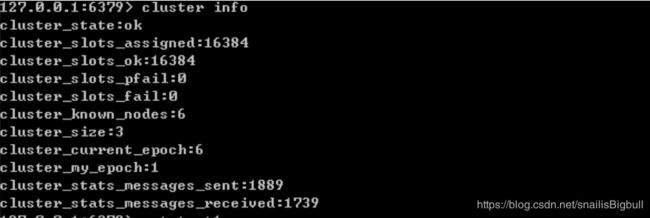
2)命令: info replication
主:

从:

3)查看各个节点分配slot,命令 cluster nodes

4)存值测试
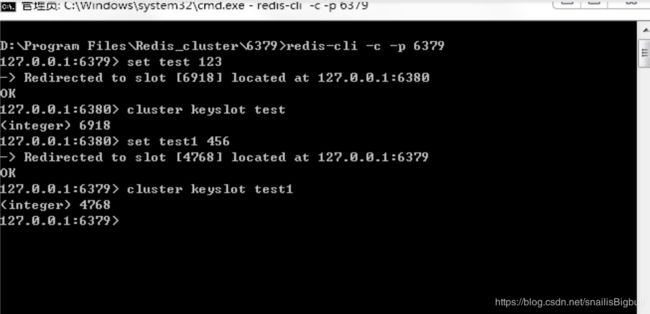
以6380节点为例,管理的slots为5461-10922,key为test的slot为6918,显然命中6380管理的卡槽6918,所以客户端也跳转到了6380。key为test1的slot为4768,在6379的卡槽范围0-5460,所以客户端又跳转到了6379。
Redis集群数据分配策略:
采用一种叫做哈希槽 (hash slot)的方式来分配数据,redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384
注意的是:必须要3个以上的主节点,否则在创建集群时会失败,三个节点分别承担的slot 区间是:
节点A覆盖0-5460;
节点B覆盖5461-10922;
节点C覆盖10923-16383.
jedis
原来mysql需要使用jdbc,现在需要redis的一个java客户端jedis。
jedis是客户端,而reids是服务器。使用jedis这个java客户端操作redis数据库。
1.导包
maven方式
@Test
public void test()throws Exception{
//1.创建连接
String host ="127.0.0.1";
int port = 6379;
int timeout = 1000;//超时时间,1秒超时
Jedis jedis = new Jedis(host,port,timeout);
jedis.auth("admin");
//2.执行操作
jedis.set("yhptest","yhptest dbl!");
System.out.println(jedis.get("yhptest"));
//3.关闭连接
jedis.close();
}

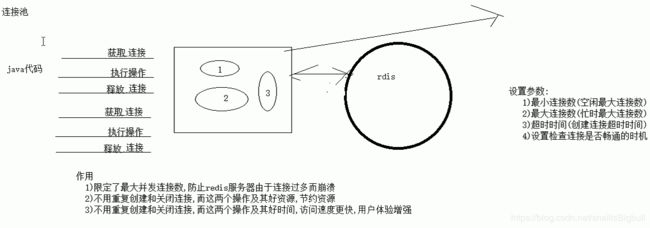
2.5.2.Jedis代码测试
@Test
public void testCluster() throws IOException, InterruptedException {
Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("127.0.0.1", 6379));
nodes.add(new HostAndPort("127.0.0.1", 6380));
nodes.add(new HostAndPort("127.0.0.1", 6381));
nodes.add(new HostAndPort("127.0.0.1", 6382));
nodes.add(new HostAndPort("127.0.0.1", 6383));
nodes.add(new HostAndPort("127.0.0.1", 6384));
JedisCluster cluster = new JedisCluster(nodes);
try {
String res = cluster.get("name");
System.out.println(res);
// cluster.quit();
} catch (Exception e) {
e.printStackTrace();
// cluster.quit();
}
}
}
//思想:如果创建一个对象后需要为他设置很多值,还不如先创建它配置对象并做完配置,然后再通过配置对象创建它
//1 创建jedispool配置对象
//2 做配置-四个
//3 创建jedispool
//4 通过jedispool获取连接
//5 执行操作
// 6 释放连接
// 7 摧毁连接池-如果是真正项目中它应该是一个受spring管理的单例
@Test
public void test()throws Exception{
//1 创建jedispool配置对象
JedisPoolConfig config = new JedisPoolConfig();
//2 做配置-四个
config.setMaxIdle(2);
config.setMaxTotal(10);
config.setMaxWaitMillis(1*1000); //创建连接超时
config.setTestOnBorrow(true);//获取连接是测试连接是否畅通
//3 创建jedispool
//1*1000 获取连接超时时间
JedisPool pool = new JedisPool(config,
"127.0.0.1",6379,1*1000,"admin");
//4 通过jedispool获取连接
Jedis jedis = pool.getResource();
//5 执行操作
jedis.set("jedispooltest","dbldblddzt.....");
System.out.println(jedis.get("jedispooltest"));
// 6 释放连接
jedis.close(); //底层做了兼容,如果是连接池操作就是释放,如果是连接操作就是关闭
// 7 摧毁连接池-如果是真正项目中它应该是一个受spring管理的单例
pool.destroy();
}
使用jedis来操作redis的key和value,而value有很多种类型,和命令操作一样。
JedisUtil .java
package cn.itsource.redis.client.jedis;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public enum JedisUtil {
INSTANCE;
private static JedisPool pool;
static {
//1 创建jedispool配置对象
JedisPoolConfig config = new JedisPoolConfig();
//2 做配置-四个
config.setMaxIdle(2);
config.setMaxTotal(10);
config.setMaxWaitMillis(1*1000); //创建连接超时
config.setTestOnBorrow(true);//获取连接是测试连接是否畅通
//3 创建jedispool
//1*1000 获取连接超时时间
pool = new JedisPool(config,
"127.0.0.1",6379,1*1000,"admin");
}
public Jedis getResource(){
return pool.getResource();
}
public void closeResource(Jedis jedis){
jedis.close();
}
}
package cn.itsource.redis.client.jedis;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import java.util.Iterator;
/**
* jedis操作redis
*
* key:
* 各种类型value(String):
*/
public class JedisOprTest
{
//每个参数方法都要获取连接
Jedis jedis = JedisUtil.INSTANCE.getResource();
@Test
public void testKey()throws Exception{
//清空数据
jedis.flushAll();
System.out.println("判断key为name的key是否存在!"+jedis.exists("name"));
System.out.println("判断key为sex的key是否存在!"+jedis.exists("sex"));
System.out.println("判断key为age的key是否存在!"+jedis.exists("age"));
System.out.println("给key为name的key设置值:"+jedis.set("name", "zs"));
System.out.println("给key为sex的key设置值:"+jedis.set("sex", "nan"));
System.out.println("给key为age的key设置值:"+jedis.set("age", "18"));
System.out.println("再次判断key为name的key是否存在!"+jedis.exists("name"));
System.out.println("再次判断key为sex的key是否存在!"+jedis.exists("sex"));
System.out.println("再次判断key为age的key是否存在!"+jedis.exists("age"));
System.out.println("获取key为name的vaue值:"+jedis.get("name"));
System.out.println("删除前获取key为sex的vaue值:"+jedis.get("sex"));
System.out.println("上传key为sex的key:"+jedis.del("sex"));
System.out.println("删除后获取key为sex的vaue值:"+jedis.get("sex"));
// 获取所有的key
Iterator<String> iterator = jedis.keys("*").iterator();
while (iterator.hasNext()){
String key = iterator.next();
System.out.println(key+"--->"+jedis.get(key));
}
//jedis.expire(key,seconds)
//释放连接
jedis.close();
}
@Test
public void testStringBase()throws Exception{
//jedis.set(key,value) add update
//jedis.del(key) del
//jedis.append(key,appStr)追加
//jedis.get() 获取
}
@Test
public void testStringBatch()throws Exception{
//jedis.mset(keyvalue,keyvalue) dd update
//jedis.del(key1,key2...) del
//jedis.mget(key1,key2,key3....)
}
@Test
public void testStringAdvanceOpr()throws Exception{
//jedis.incr()
//jedis.incrBy()
//jedis.setex(key,time,value) //设置值得时候同时设置过期时间
}
//事务四个特性
// 1 原子性:一个事务中,多个操作是不可分割的,要么都成功,要么都失败.
// 2 一致性:一个事务中,多个操作如果有一个失败了,其他要进行回滚保持数据一致性.
// 3 隔离性:事务是隔离的,多个事务不会相互影响
// 4 连续性(持续性):事务一旦开始,不能中止.
@Test
public void test()throws Exception{
//手动回滚
}
}