大数据Hadoop完全分布式集群搭建
准备完全分布式主机的ssh
-------------------------
1.删除所有主机上的/home/centos/.ssh/*
2.在s201主机上生成密钥对
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
3.将s201的公钥文件id_rsa.pub远程复制到201 ~ 204主机上。
并放置/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s201:/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s202:/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s203:/home/centos/.ssh/authorized_keys
$>scp id_rsa.pub centos@s204:/home/centos/.ssh/authorized_keys


core.site.xml

hdfs-site.xml

mapred.site.xml不需要变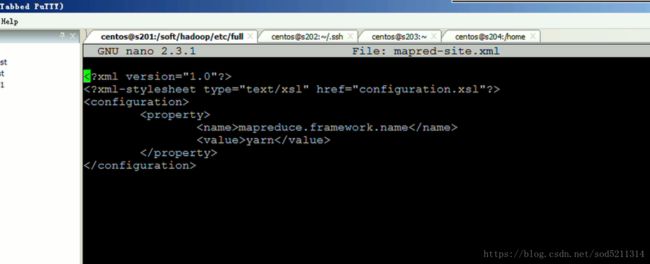
yarn.site.xml

还有一个slaves文件指定谁是数据节点
、/******这个是我忘记了slaves配置文件后来才改的,之后还得重新分发一遍,你们就不用看这个了,我是忘记了,你们千万别忘了就行 *******/
*******/
j接下来就是把所配置好的配置文件分发到其他的机子上去执行三次



命令:rm hadoop ln-s full hadoop
此时hadoop-->full指向full 才是完全分布式 ,因为full里面配置的是完全分布式的配置文件
此时还要远程把另外三台里面的hadoop给删了 ssh s202 rm -rf /root/App/hadoop-2.4.1/etc/hadoop


查看s202已经删除
再远程进行符号链接
![]()
符号链接后s202如图

其他的跟s202一样
操作如下图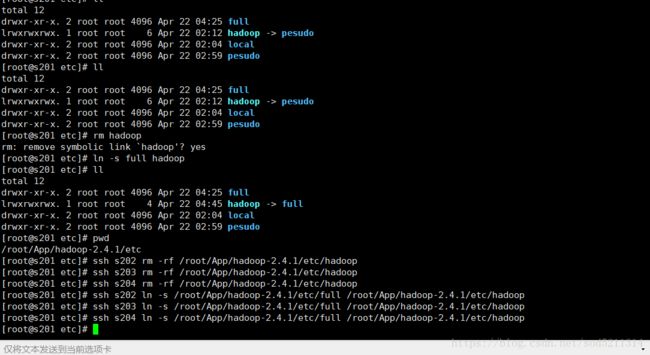
7:删除临时目录文件 在cd /tmp下 这里我没有删
8:删除日志文件

9:格式化名称节点hadoop namenode -format






由于hadoop的数据默认都存放在tmp临时目录下,这样在实际环境中不会弄得
配置hadoop临时目录
---------------------
1.配置[core-site.xml]文件
利用rsync.sh这个脚本进行分发,脚本如下
#!/bin/bash
if [[ $# -lt 1 ]] ; then echo no params ; exit ; fi
p=$1
#echo p=$p
dir=`dirname $p`
#echo dir=$dir
filename=`basename $p`
#echo filename=$filename
cd $dir
fullpath=`pwd -P .`
#echo fullpath=$fullpath
user=`whoami`
for (( i = 202 ; i <= 204 ; i = $i + 1 )) ; do
echo ======= s$i =======
rsync -lr $p ${user}@s$i:$fullpath
done ;

用rsync.sh core-site.xml 这个命令进行分发 ,
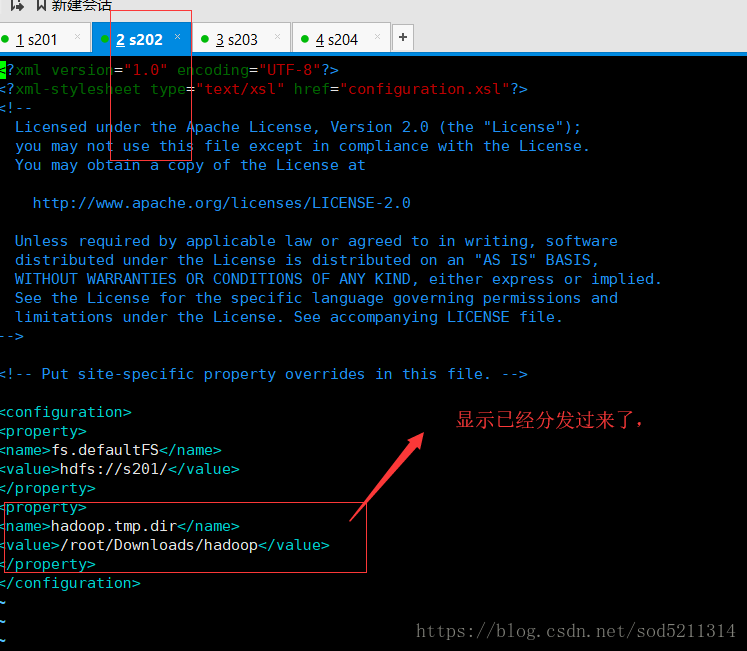
这时候先看下Downloads文件夹里面的内容再格式化之前,
这时候还没有hadoop这个文件夹,如果正常的话,执行format就会产生数据到这个目录下,而不会在吧数据放到tmp文件夹里面了
用下面这条命令来查询是否把core-site.xml这个文件修改的内容分发到其他机器上

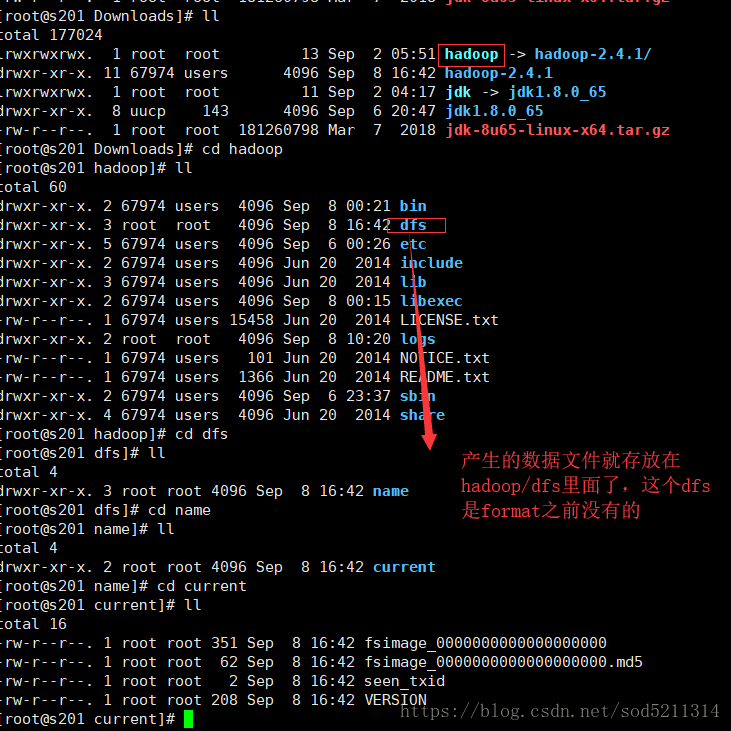
而数据节点里面没有增加hadoop/dfs的内容,说明了hadoop namenode-format只对namenode的本地目录进行初始化
想要查看名称节点里面的镜像文件
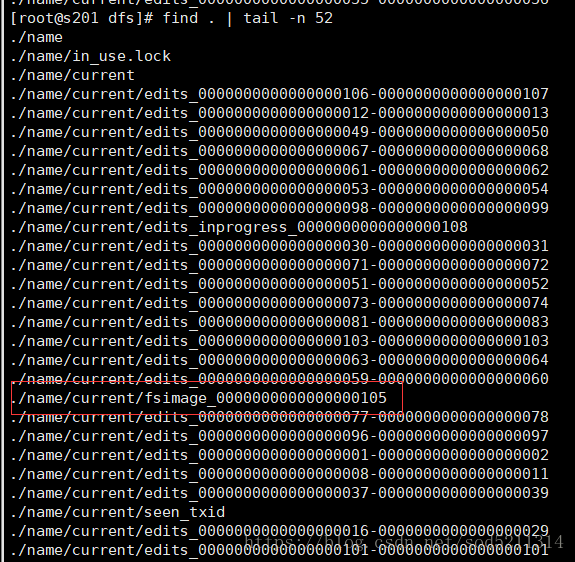
hdfs oiv -i fsimage -o a.xml -p XML //查看镜像文件。 -i是镜像文件 -o是输出到a.xml文件里面 -p是指定xml文件格式
查看一下,结果里面东西没看懂


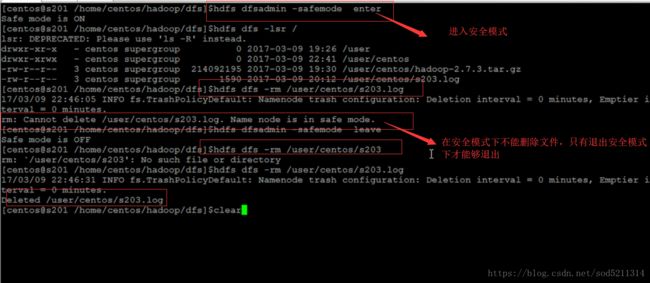
查看hdfs是否在安全模式
------------------------
$>hdfs dfsadmin -safemode enter //进入
$>hdfs dfsadmin -safemode get //查看
$>hdfs dfsadmin -safemode leave //退出
$>hdfs dfsadmin -safemode wait //等待
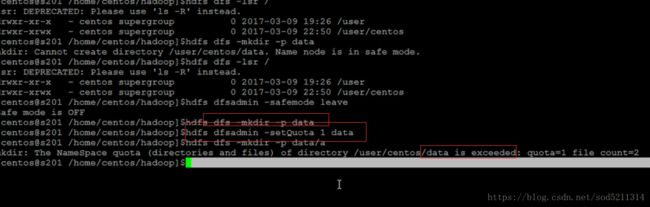
[目录配额]
计算目录下的所有文件的总个数。如果1,表示空目录。
$>hdfs dfsadmin -setQuota 1 dir1 dir2 //设置目录配额
$>hdfs dfsadmin -clrQuota 1 dir1 dir2 //清除配额管理
[空间配额]
计算目录下的所有文件的总大小.包括副本数.
空间配置至少消耗384M的空间大小(目录本身会占用384M的空间)。
$>hdfs dfsadmin -setSpaceQuota 3 data
$>echo -n a > k.txt
$>hdfs dfs -put k.txt data2
$>hdfs dfsadmin -clrSpaceQuota dir1 //清除配额管理

当你的集群一启动,它就把你的编辑文件和镜像文件加载到文件里面同时完成这两个文件的融合产生inprogess文件
