Sql性能优化(一)
在实际应用开发中,随着数据量和并发量的不断增大,sql质量的高低对整个系统性能有着很大的影响,一个糟糕的sql会使系统慢如病牛,直接影响用户体验和系统的正常运行,Sql优化是系统性能优化的必由之路。优化之前需要先看看如何定位sql的病因。
一、开启日志,发现慢sql
我们可以通过开启慢查询日志的方式来记录执行较慢的sql,方法如下:找到配置文件my.cnf,找到log_slow_queries = /var/log/mysql/mysql-slow.log 和long_query_time = 2,将其前面的#去掉即可开启慢查询日志,log_slow_queries表示慢查询日志文件的路径,long_query_time = 2表示查询时间超过两秒就会记录下来。要注意的是慢查询日志开启一段时间后需关闭,避免其io操作影响系统性能。
Mysql自带的mysqldumpslow工具可以用来分析日志,主要功能包括统计不同慢查询sql 的出现次数、执行耗费的平均时间和累计总耗费时间、等待锁耗费的时间、发送给客户端的行总数、扫描的行总数等,其常用的语法如下:
mysqldumpslow -s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-t NUM just show the top n queries
-g PATTERN grep: only consider stmts that include this string
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙。
-t, 是top n的意思,也就是返回前面n条的数据。
-g PATTERN,PATTERN表示匹配模型,用来查找与匹配模型相匹配的值,PATTERN大小写不敏感。mysqldumpslow -s r -t 20 mysql-slow.log返回记录集最多的20个sql。
mysqldumpslow -t 10 -s t -g “left join”mysql-slow.log 这个是按照时间返回前10条里面含有左连接的sql语句。
慢查询日志和mysqldumpslow工具可以帮助我们找到执行较慢的sql,也即优化的目标。
二.诊断sql之望闻声切
要想优化sql,首先要学会如何定位sql执行缓慢的原因,找到病因才能对症下药,要用数据说话而不是凭感觉。在这方面mysql提供了一些非常有用的命令,用来跟踪分析sql执行情况,我们可以通过分析这些数据来定位“病因”!
Mysql提供了EXPLAIN命令分析sql查询的执行计划,其格式为:explain sql
例如 explain select count(uuid) from evidence_details ,执行结果如下:

先说说图中各列的含义:
1.select_type : 表示SELECT的类型,其类型有:SIMPLE,PRIMARY,UNION,SUBQUERY,DERIVED等,其中SIMPLE表示一个简单的表查询,sql中不涉及表连接和子查询。PRIMARY表示主查询也就是最外层的查询,UNION表示union中的第二个或者后面的查询语句,SUBQUERY则表示子查询中的第一个select查询。
如果查询涉及的表不是物理表,则被称为DERIVED,在子查询中常见这种类型。
2.table:查询中涉及的表
3.type: 表示mysql查询表中数据的方式,常见的有以下七种类型:
ALL:表示全表扫描,mysql通过遍历全表来查询数据,性能最差。
b. index: 索引全扫描,mysql通过遍历整个索引来查询数据
c. range: 索引范围扫描,mysql通过根据索引范围遍历查询数据,常见于含有< 、>、between等操作符的语句
d. ref: 使用非唯一的索引扫描或唯一索引的前缀来扫描,返回匹配某个单独值的记录行。
e. eq_ref: 使用唯一性索引来扫描,每个索引键值在表中只有一条记录匹配。
f. const/system: 单表中最多有一个匹配行,查询起来很快。这个匹配行中的其他列的值可以被优化器在当前查询中当做常量来处理。
g. NULL: mysql不用访问表或索引就能直接得到结果
这七种类型的查询方式的性能优劣顺序为:ALL possible_keys: 表示查询时可能用到的索引
key表示实际使用到的索引
key_len: 使用到索引字段的长度
rows: 扫描行的数量
Extra: 执行情况的说明和描述,常见的值如下:
1. Using where
表示查询使用了where 语句来处理结果。
2. Using temporary
表示使用了内部临时表。
3. Using filesort
表示在使用order by时将结果在内存排序区中进行排序
4. Using index
这个值重点强调了只需要使用索引就可以满足查询表的要求,不需要直接访问表数据。
通过explain命令我们可以了解mysql的执行计划,进而判断出sql执行缓慢的原因。
从上图中我们可以看出 select count(uuid) from evidence_details 进行了全表扫描,这也是该sql执行较慢的原因所在。
三、剖析sql之庖丁解牛
Mysql提供的另一个分析sql的有力命令是 show profiles,这个语句让我们可以详细的了解到sql执行的具体过程。需要注意的是mysql5.0.3.7以上版本才支持这条命令。我们可以通过select @@have_profiling命令来查看当前自己使用的mysql是否支持profile. 下图是执行select @@have_profiling命令的结果,YES表示此mysql支持profile

由于profiling默认是关闭的,可以通过select @@profiling命令查看的结果如下图:
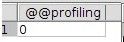
0表示profiling处于关闭状态。执行set profiling=1可以打开profiling
执行select count(uuid) from evidence_details 语句,然后show profiles的结果如下:

Duration表示执行的时间,单位是秒。
接下来我们可以通过 show profile for query Query_ID 命令查看该sql执行过程中的各个状态和对应的时间。
show profile for query 54 ,结果如下图

其中sending data表示mysql线程从开始访问数据行到把结果返回给客户端的时间。在这个过程中要进行大量的IO磁盘读取操作,消耗时间最长。此外还可以通过trace来分析优化器如何选择执行计划的详细过程。
通过以上三步,我们基本上可以确定sql执行缓慢的原因,接下来就是具体的sql优化。
一、开启日志,发现慢sql
我们可以通过开启慢查询日志的方式来记录执行较慢的sql,方法如下:找到配置文件my.cnf,找到log_slow_queries = /var/log/mysql/mysql-slow.log 和long_query_time = 2,将其前面的#去掉即可开启慢查询日志,log_slow_queries表示慢查询日志文件的路径,long_query_time = 2表示查询时间超过两秒就会记录下来。要注意的是慢查询日志开启一段时间后需关闭,避免其io操作影响系统性能。
Mysql自带的mysqldumpslow工具可以用来分析日志,主要功能包括统计不同慢查询sql 的出现次数、执行耗费的平均时间和累计总耗费时间、等待锁耗费的时间、发送给客户端的行总数、扫描的行总数等,其常用的语法如下:
mysqldumpslow -s ORDER what to sort by (al, at, ar, c, l, r, t), 'at' is default
al: average lock time
ar: average rows sent
at: average query time
c: count
l: lock time
r: rows sent
t: query time
-t NUM just show the top n queries
-g PATTERN grep: only consider stmts that include this string
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙。
-t, 是top n的意思,也就是返回前面n条的数据。
-g PATTERN,PATTERN表示匹配模型,用来查找与匹配模型相匹配的值,PATTERN大小写不敏感。mysqldumpslow -s r -t 20 mysql-slow.log返回记录集最多的20个sql。
mysqldumpslow -t 10 -s t -g “left join”mysql-slow.log 这个是按照时间返回前10条里面含有左连接的sql语句。
慢查询日志和mysqldumpslow工具可以帮助我们找到执行较慢的sql,也即优化的目标。
二.诊断sql之望闻声切
要想优化sql,首先要学会如何定位sql执行缓慢的原因,找到病因才能对症下药,要用数据说话而不是凭感觉。在这方面mysql提供了一些非常有用的命令,用来跟踪分析sql执行情况,我们可以通过分析这些数据来定位“病因”!
Mysql提供了EXPLAIN命令分析sql查询的执行计划,其格式为:explain sql
例如 explain select count(uuid) from evidence_details ,执行结果如下:
先说说图中各列的含义:
1.select_type : 表示SELECT的类型,其类型有:SIMPLE,PRIMARY,UNION,SUBQUERY,DERIVED等,其中SIMPLE表示一个简单的表查询,sql中不涉及表连接和子查询。PRIMARY表示主查询也就是最外层的查询,UNION表示union中的第二个或者后面的查询语句,SUBQUERY则表示子查询中的第一个select查询。
如果查询涉及的表不是物理表,则被称为DERIVED,在子查询中常见这种类型。
2.table:查询中涉及的表
3.type: 表示mysql查询表中数据的方式,常见的有以下七种类型:
ALL:表示全表扫描,mysql通过遍历全表来查询数据,性能最差。
b. index: 索引全扫描,mysql通过遍历整个索引来查询数据
c. range: 索引范围扫描,mysql通过根据索引范围遍历查询数据,常见于含有< 、>、between等操作符的语句
d. ref: 使用非唯一的索引扫描或唯一索引的前缀来扫描,返回匹配某个单独值的记录行。
e. eq_ref: 使用唯一性索引来扫描,每个索引键值在表中只有一条记录匹配。
f. const/system: 单表中最多有一个匹配行,查询起来很快。这个匹配行中的其他列的值可以被优化器在当前查询中当做常量来处理。
g. NULL: mysql不用访问表或索引就能直接得到结果
这七种类型的查询方式的性能优劣顺序为:ALL
key表示实际使用到的索引
key_len: 使用到索引字段的长度
rows: 扫描行的数量
Extra: 执行情况的说明和描述,常见的值如下:
1. Using where
表示查询使用了where 语句来处理结果。
2. Using temporary
表示使用了内部临时表。
3. Using filesort
表示在使用order by时将结果在内存排序区中进行排序
4. Using index
这个值重点强调了只需要使用索引就可以满足查询表的要求,不需要直接访问表数据。
通过explain命令我们可以了解mysql的执行计划,进而判断出sql执行缓慢的原因。
从上图中我们可以看出 select count(uuid) from evidence_details 进行了全表扫描,这也是该sql执行较慢的原因所在。
三、剖析sql之庖丁解牛
Mysql提供的另一个分析sql的有力命令是 show profiles,这个语句让我们可以详细的了解到sql执行的具体过程。需要注意的是mysql5.0.3.7以上版本才支持这条命令。我们可以通过select @@have_profiling命令来查看当前自己使用的mysql是否支持profile. 下图是执行select @@have_profiling命令的结果,YES表示此mysql支持profile
由于profiling默认是关闭的,可以通过select @@profiling命令查看的结果如下图:
0表示profiling处于关闭状态。执行set profiling=1可以打开profiling
执行select count(uuid) from evidence_details 语句,然后show profiles的结果如下:
Duration表示执行的时间,单位是秒。
接下来我们可以通过 show profile for query Query_ID 命令查看该sql执行过程中的各个状态和对应的时间。
show profile for query 54 ,结果如下图
其中sending data表示mysql线程从开始访问数据行到把结果返回给客户端的时间。在这个过程中要进行大量的IO磁盘读取操作,消耗时间最长。此外还可以通过trace来分析优化器如何选择执行计划的详细过程。
通过以上三步,我们基本上可以确定sql执行缓慢的原因,接下来就是具体的sql优化。