分布式Restful SpringBoot骨架搭建(一)
分布式Restful SpringBoot骨架搭建
架构演变
现在分布式的SpringBoot是我经过大概半年对JavaEE的探索总结出来的最佳骨架,整合了大部分的常用技术,并有相应的Demo可供参考,并最终部署在一个较为真实的环境中。
先说一下我所经历的JavaEE的架构升级过程。
1. All In One:所有的代码打为一个Jar包,所有的软件(JDK,MySQL,Redis)均安装在同一个机器中。
见https://github.com/songxinjianqwe/SpringBootCentralizedSkeleton dev环境
2. 软件拆分至各个服务器:所有代码打为一个Jar包,运行在一台单独的应用服务器,MySQL安装在MySQL服务器,Redis安装在Redis服务器,等等。
见https://github.com/songxinjianqwe/SpringBootCentralizedSkeleton pro环境
3. 部分软件实现集群:所有代码打为一个Jar包,运行在一台单独的应用服务器,MySQL安装在MySQL服务器集群,Redis安装在Redis服务器集群,等等。
见https://github.com/songxinjianqwe/SpringBootDistributedSkeleton dev,pro环境
4. 服务化拆分:将不同模块的代码打为多个Jar包,运行在多台应用服务器,实现服务化。MySQL安装在MySQL服务器集群,Redis安装在Redis服务器集群,等等。
尚在学习中。
这里我主要介绍的是3,1和2也有相应的实现,见相应的GithubRepo。
涉及技术
- SpringBoot+多环境配置(dev,proc,test)
- SpringMVC
- Spring
- MyBaits
- MyBatis Generator
- MyBatis PageHelper
- Druid
- Lombok
- JWT
- Spring Security
- JavaMail
- Thymeleaf
- HttpClient
- FileUpload
- Spring Scheduler
- Hibernate Validator
- Redis Cluster
- MySQL主从复制,读写分离
- Spring Async
- Spring Cache
- Swagger
- Spring Test
- MockMvc
- HTTPS
- Spring DevTools
- Spring Actuator
- Logback+Slf4j多环境日志
- i18n
- Maven Multi-Module
- WebSocket
- ElasticSearch
功能点
用户模块
- 获取图片验证码
- 登录:解决重复登录问题
- 注册
- 分页查询用户信息
- 修改用户信息
站内信模块
- 一对一发送站内信
- 管理员广播
- 读取站内信(未读和已读)
- 一对多发送站内信
文件模块
- 文件上传
- 文件下载
邮件模块
- 单独发送邮件
- 群发邮件
- Thymeleaf邮件模板
安全模块
- 注解形式的权限校验
- 拦截器
文章管理模块
- 增改删查
实现细节
Spring Boot
从传统过的SSM迁移到SpringBoot花了不少功夫,主要是xml配置文件全部变成了Java Config+application.yml,另外有大量的约定需要了解和遵守。除了原本的功能全部可以实现外,还添加了一些其他的功能。
1. 多环境部署,使用多个yml文件描述不同环境,在运行时只需要加 –spring.profiles.active=pro/dev 就可以切换不同环境,非常方便。
2. Spring Boot DevTools,支持热部署
3. Spring Boot Actuator 监控应用的运行情况
4. Logback多环境日志,配合SpringBoot的多环境部署。
Spring Boot 使用注意点
每个Mapper上都要加@Mapper
yaml文件 @Value获取xx.xx.xx不可行,必须使用@ConfigurationProperties,指定prefix,属性设置setter和getter
logback日志重复打印:自定义logger上加上
additivity="false"SpringBoot 项目没有项目名
登录 Spring Security +JWT
已登录用户验证token
- 主要是在Filter中操作。
从requestHeader中取得token,检查token的合法性,检查这一步可以解析出username去查数据库;
也可以查询缓存,如果缓存中有该token,那么就没有问题,可以放行。
- 主要是在Filter中操作。
未登录用户进行登录
- 登录时要构造UsernamePasswordAuthenticationToken,用户名和密码来自于参数,然后调用AuthenticationManager的authenticate方法,
它会去调用UserDetailsService的loadFromUsername,参数是token的username,然后比对password,检查userDetails的一些状态。
如果一切正常,那么会返回Authentication。返回的Authentication的用户名和密码是正确的用户名和密码,并且还放入了之前查询出的Roles。
调用getAuthentication然后调用getPrinciple可以得到之前听过UserDetailsService查询出的UserDetails
- 登录时要构造UsernamePasswordAuthenticationToken,用户名和密码来自于参数,然后调用AuthenticationManager的authenticate方法,
- 在Controller中使用@PreAuthorize等注解需要在spring-web配置文件中扫描security包下的类
引用application.properties中的属性的方式:@ConfigurationProperties(prefix = “spring.mail”) + @Component + setter + getter
引用其他自定义配置文件中的属性的方式:
- @Component
- @ConfigurationProperties(prefix = “auth”)
- @PropertySource(“classpath:auth.properties”)
- setter & getter
所以写静态资源位置的时候,不要带上映射的目录名(如/static/,/public/ ,/resources/,/META-INF/resources/)!
所有的html都放在templates下面,只有index.html能直接访问,其他均不可,必须通过Controller的转发
- 静态资源都放在static下面,访问时Spring Security会检查URL,根据URL进行拦截。如果通过,那么会交给ViewResolver,添加前面的/static(无需配置,SpringBoot自动完成),得到最终的真实路径
Mybatis打印SQL http://www.cnblogs.com/lixuwu/p/6323739.html
访问Druid监控: http://localhost:8080/druid
- spring-devtools热部署:
- 前提:把Idea的自动编译打开
- 修改类–>保存:应用会重启
- 修改配置文件–>保存:应用会重启
- 修改页面–>保存:应用不会重启,但会重新加载,页面会刷新(原理是将spring.thymeleaf.cache设为false)
@Bean
- 可以指定name,如果不指定那么使用方法名作为name
- 有一个initMethod和destroyMethod两个属性,值为该Bean的方法名 ;当然也可以直接在方法上使用注解@PostConstruct&@PreDestroy
@EnableAsync @EnableTransactionManagement @EnableCaching @EnableScheduling @EnableWebSecurity @EnableSwagger2
- @EnableTransactionManagement | @EnableWebSecurity 可以不加,自动配置
@Conditional(条件注解,感兴趣可深入了解)
注册Servlet、Filter、Listener (在SpringBoot中使用原生JavaEE API,感兴趣可深入了解)
ApplicationEvent Spring 提供的Observer模型骨架(感兴趣可深入了解)
SpringMVC 拦截器 实现HandlerInterceptor接口或继承HandlerInterceptorAdaptor类,然后将其注册为一个Bean,并在registry(继承了WebMvcConfigurerAdapter的配置类)中调用addInterceptor
如果想要自己完全控制WebMVC,就需要在@Configuration注解的配置类上增加@EnableWebMvc;否则会使用自动配置。一般不使用@EnableWebMvc@SpringBootApplication是一个组合注解,组合了@EnableAutoConfiguration,根据类路径中的jar包依赖为当前项目进行自动配置
Jaskson 反序列化 mapper.readValue(content, new TypeReference
日志处理
学习Java快1年半了,最近才懂得日志的重要性,之前都只是System.out.println。当应用部署在服务器时,控制台是很难观察的,只能依靠log文件,而System.out.println是无法被记录下来的。我想到的最简单的做法是使用Log4j/Logback+Slf4j+Lombok。Log4j/Logback都是日志的具体实现,而Slf4j是日志门面,底层依赖于具体实现,而Slf4j的优点在于使用类似于%d的占位符,避免了大量的字符串拼接,无论是可读性还是效率都很不错。Lombok则使用一个@Slf4j注解来避免了每个类都要写一个Logger logger = LoggerFactory.getLogger这行代码。
比如下面这段代码,实现了AOP切面日志。
@Aspect
@Order(2)
@Configuration
@Slf4j
public class LoggingAspect {
@Pointcut("execution(* cn.sinjinsong.skeleton.service..*.*(..))||@annotation(org.springframework.web.bind.annotation.RequestMapping)||execution(* cn.sinjinsong.skeleton.dao..*.*(..))")
public void declareJoinPointExpression() {
}
@Before("declareJoinPointExpression()")
public void beforeMethod(JoinPoint joinPoint) {// 连接点
Object[] args = joinPoint.getArgs();// 取得方法参数
log.info("The method [ {} ] begins with Parameters: {}", joinPoint.getSignature(), Arrays.toString(args));
}
@AfterReturning(value = "declareJoinPointExpression()", returning = "result")
public void afterMethodReturn(JoinPoint joinPoint, Object result) {
log.info("The method [ {} ] ends with Result: {}", joinPoint.getSignature(), result);
}
@AfterThrowing(value = "declareJoinPointExpression()", throwing = "e")
public void doAfterThrowing(JoinPoint joinPoint, Exception e) {
log.error("Error happened in method: [ {} ]", joinPoint.getSignature());
log.error("Parameters: {}", Arrays.toString(joinPoint.getArgs()));
log.error("Exception StackTrace: {}", e);
}
}log是一个日志对象,可以调用info,error等方法进行日志输出。至于日志是仅打印还是写到文件,要看Log4j/Logback的配置文件的描述。
这样看来,使用@Slf4j+log.info这个阻塞,不仅写起来比System.out.println要简洁,并且软件的可维护性也高了很多。
异常处理
关于Restful的异常处理,我造了一个小轮子,代码放在common模块下。
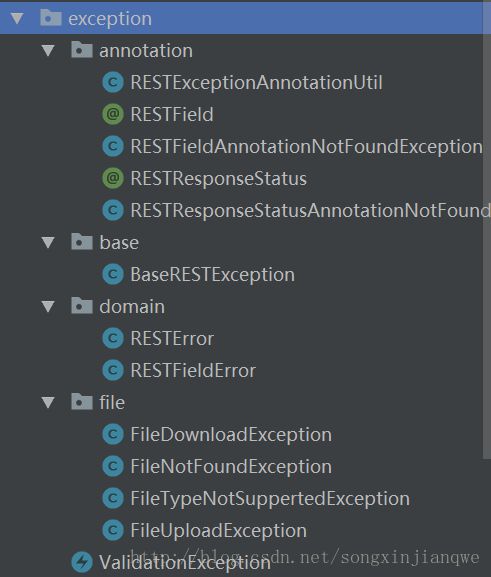
主要是让程序里的RuntimeException变为前端开发人员能够读懂的json格式的统一格式的异常信息,同时具有国际化功能,错误信息也可以直接显示在页面上。
这里只讲一下使用方法,具体实现可以看common/exception下面的源码,并不复杂,使用起来非常简单。
/**
* Created by SinjinSong on 2017/5/5.
*/
@RESTResponseStatus(value= HttpStatus.NOT_FOUND,code=7)
@RESTField("targetId")
public class MailStatusNotFoundException extends BaseRESTException{
public MailStatusNotFoundException(Long targetId){
super(targetId);
}
}
比如想查询某一封站内信,但是不存在这封信,那么我们会在service代码中抛出这个RuntimeException,统一异常处理器会捕获该异常,并将该异常转为前端可读的错误信息。
具体做法是:定义一个异常,并继承自BaseRESTException。在类上加入两个注解,一个是RESTResponseStatus,记录对应的HTTP错误码,code是自定义且唯一的,用来区分不同的404异常;另一个是RESTField,用来记录错误的属性名(key)。该类必须有一个构造方法,传入任意类型的参数,用来记录错误的属性值(value)。另外在src/main/resources/i18n下面的zh_CN中加入一行
i18n.MailStatusNotFound=\u672A\u627E\u5230\u7AD9\u5185\u4FE1\u6536\u4FE1\u4EBA
注意这里的中文要转为unicode编码,否则会出现编码问题。
中文与unicode相互转换可以使用这个网站:
http://tool.chinaz.com/tools/unicode.aspx
根据客户端的Accept-Language来决定是使用zh_CN里的value还是en_US里的value。
整合Redis
该项目在两个地方使用了Redis,一个是用于Spring Cache,具体表现为service方法上的一些注解。
@Override
@Cacheable("UserDO")
@Transactional(readOnly = true)
public UserDO findByUsername(String username) {
return userDOMapper.findByUsername(username);
}
@Override
@Cacheable("UserDO")
@Transactional(readOnly = true)
public UserDO findByPhone(String phone) {
return userDOMapper.findByPhone(phone);
}
@Override
@Cacheable("UserDO")
@Transactional(readOnly = true)
public UserDO findById(Long id) {
return userDOMapper.selectByPrimaryKey(id);
}
@Override
@Transactional
@CacheEvict(value = "UserDO",allEntries = true)
public void save(UserDO userDO) {
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
//对密码进行加密
userDO.setPassword(passwordEncoder.encode(userDO.getPassword()));
userDO.setRegTime(LocalDateTime.now());
//设置用户状态为未激活
userDO.setUserStatus(UserStatus.UNACTIVATED);
userDOMapper.insert(userDO);
//添加用户的角色,每个用户至少有一个user角色
long roleId = roleDOMapper.findRoleIdByRoleName("ROLE_USER");
roleDOMapper.insertUserRole(userDO.getId(),roleId);
}
@Override
@Transactional
@CacheEvict(value = "UserDO",allEntries = true)
public void update(UserDO userDO) {
userDOMapper.updateByPrimaryKeySelective(userDO);
}
@Override
@Transactional
@CacheEvict(value = "UserDO",allEntries = true)
public void resetPassword(Long id,String newPassword) {
BCryptPasswordEncoder passwordEncoder = new BCryptPasswordEncoder();
UserDO userDO = new UserDO();
userDO.setId(id);
userDO.setPassword(passwordEncoder.encode(newPassword));
userDOMapper.updateByPrimaryKeySelective(userDO);
}在查询数据库等方法上加入@Cacheable注解可以将查询到的数据存入Redis,当下一次以相同的参数调用该方法时,会将Redis中的数据返回,大大提高查询效率。
另一个使用到Redis的地方是RedisCacheManager,主要是用于自己想要的做的一些特殊用途,比如各种的Token。
@Component
@Slf4j
public class JWTAuthenticationTokenFilter extends OncePerRequestFilter {
@Autowired
private UserDetailsService userDetailsService;
@Autowired
private TokenManager tokenManager;
@Override
protected void doFilterInternal(
HttpServletRequest request,
HttpServletResponse response,
FilterChain chain) throws ServletException, IOException {
log.info("经过JWTAuthenticationTokenFilter");
//拿到token
String token = request.getHeader(AuthenticationProperties.AUTH_HEADER);
//验证token,如果无效,结果返回exception;如果有效,结果返回username
TokenCheckResult result = tokenManager.checkToken(token);
if (!result.isValid()) {
log.info("Token无效");
request.setAttribute(AuthenticationProperties.EXCEPTION_ATTR_NAME, result.getException());
} else {
log.info("checking authentication {}", result);
UserDetails userDetails = userDetailsService.loadUserByUsername(result.getUsername());
//如果未登录
if (SecurityContextHolder.getContext().getAuthentication() == null) {
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(
userDetails, null, userDetails.getAuthorities());
authentication.setDetails(new WebAuthenticationDetailsSource().buildDetails(
request));
log.info("authenticated user {} ,setting security context", result);
SecurityContextHolder.getContext().setAuthentication(authentication);
}
}
chain.doFilter(request, response);
}
}
这个是登录的Filter,会将Request中的Authentication请求头取出,查看token是否存储在Redis中,如果在且未到期,那么token有效,可以放行;否则拒绝访问。
RedisCacheManager的实现在common/cache下。
安全
安全主要是JWT和Spring Security,二者结合可以实现Restful的鉴权+权限管理。
一个是登录时的权限校验,另一个是用户的权限是否足够访问该资源。由于Restful不存在session,所以JWT提供了一种基于token的鉴权方式。
具体流程:
1. 用户请求图片验证->返回图片
2. 用户请求登录->返回Token,须携带正确的图片验证码
3. 用户发送各种访问请求->须携带该Token
每个Token有一定使用时效,超时需要重新登录。
代码主要是在/skeleton/security下。
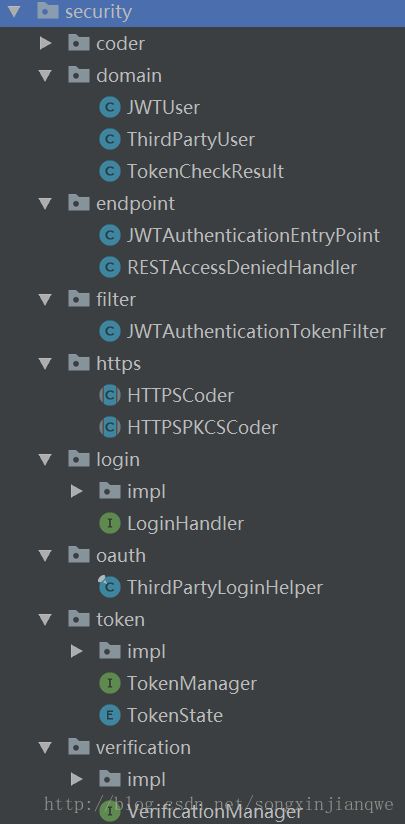
鉴权流程如下:
已登录用户验证token
- 主要是在Filter中操作。
从requestHeader中取得token,检查token的合法性,检查这一步可以解析出username去查数据库;
也可以查询缓存,如果缓存中有该token,那么就没有问题,可以放行。未登录用户进行登录
- 登录时要构造UsernamePasswordAuthenticationToken,用户名和密码来自于参数,然后调用AuthenticationManager的authenticate方法,
它会去调用UserDetailsService的loadFromUsername,参数是token的username,然后比对password,检查userDetails的一些状态。
如果一切正常,那么会返回Authentication。返回的Authentication的用户名和密码是正确的用户名和密码,并且还放入了之前查询出的Roles。
调用getAuthentication然后调用getPrinciple可以得到之前听过UserDetailsService查询出的UserDetails
关于权限认证,可以在controller的方法上加上一些注解实现。
// 更新
@RequestMapping(method = RequestMethod.PUT)
@PreAuthorize("#user.username == principal.username or hasRole('ADMIN')")
@ApiOperation(value = "更新用户信息", response = Void.class, authorizations = {@Authorization("登录权限")})
@ApiResponses(value = {
@ApiResponse(code = 401, message = "未登录"),
@ApiResponse(code = 404, message = "用户属性校验失败"),
@ApiResponse(code = 403, message = "只有管理员或用户自己能更新用户信息"),
})
public void updateUser(@RequestBody @Valid @ApiParam(value = "用户信息,用户的用户名、密码、昵称、邮箱不可为空", required = true) UserDO user, BindingResult result) {
if (result.hasErrors()) {
throw new ValidationException(result.getFieldErrors());
}
service.update(user);
}需要注意的是,不需要登录即可请求的相关方法需要在JavaConfig中写出,如果没有写,那么默认需要登录。这里的PreAuthorize注解中是在用户登录的前提之上的附加权限要求。
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class SecurityConfig extends WebSecurityConfigurerAdapter {
private JWTAuthenticationEntryPoint unauthorizedHandler;
private UserDetailsService userDetailsService;
private AccessDeniedHandler accessDeniedHandler;
@Autowired
public SecurityConfig(JWTAuthenticationEntryPoint unauthorizedHandler,
UserDetailsService userDetailsService,
AccessDeniedHandler accessDeniedHandler) {
this.unauthorizedHandler = unauthorizedHandler;
this.userDetailsService = userDetailsService;
this.accessDeniedHandler = accessDeniedHandler;
}
@Autowired
public void configureAuthentication(AuthenticationManagerBuilder authenticationManagerBuilder) throws Exception {
authenticationManagerBuilder
.userDetailsService(this.userDetailsService)
.passwordEncoder(passwordEncoder());
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public JWTAuthenticationTokenFilter authenticationTokenFilterBean() throws Exception {
return new JWTAuthenticationTokenFilter();
}
@Bean(name = BeanIds.AUTHENTICATION_MANAGER)
@Override
public AuthenticationManager authenticationManagerBean() throws Exception {
return super.authenticationManagerBean();
}
@Override
protected void configure(HttpSecurity httpSecurity) throws Exception {
// 添加JWT filter
httpSecurity
// 由于使用的是JWT,我们这里不需要csrf
.csrf().disable()
.addFilterBefore(authenticationTokenFilterBean(), UsernamePasswordAuthenticationFilter.class)
.exceptionHandling().authenticationEntryPoint(unauthorizedHandler).and()
.exceptionHandling().accessDeniedHandler(accessDeniedHandler).and()
// 基于token,所以不需要session
.sessionManagement().sessionCreationPolicy(SessionCreationPolicy.STATELESS).and()
//添加JWTFilter
.authorizeRequests()
//允许访问静态资源
.antMatchers(
HttpMethod.GET,
"/",
"/*.html",
"/favicon.ico",
"/**/*.html",
"/**/*.css",
"/**/*.js",
"/image/**").permitAll()
//允许访问swagger
.antMatchers(
"/v2/api-docs",
"/configuration/ui",
"/swagger-resources",
"/configuration/security",
"/swagger-ui.html",
"/webjars/**",
"/swagger-resources/configuration/ui",
"/swagger-ui.html",
"/swagger-resources/configuration/security").permitAll()
//允许访问websocket页面
.antMatchers(HttpMethod.GET,"/ws").permitAll()
//允许向websocket的某个endpoint发送消息
.antMatchers("/endpoint/**").permitAll()
//允许访问Druid监控
.antMatchers("/druid/**").permitAll()
//获取图片验证码
.antMatchers(HttpMethod.GET, "/captchas").permitAll()
//检查用户名是否重复
.antMatchers(HttpMethod.GET, "/users/*/duplication").permitAll()
//注册
.antMatchers(HttpMethod.POST, "/users").permitAll()
//获取头像
.antMatchers(HttpMethod.GET, "/users/*/avatar").permitAll()
//用户激活
.antMatchers(HttpMethod.GET, "/users/*/activation").permitAll()
//用户申请忘记密码
.antMatchers(HttpMethod.GET, "/users/*/password/reset_validation").permitAll()
//用户忘记密码后重置密码
.antMatchers(HttpMethod.PUT, "/users/*/password").permitAll()
.antMatchers(HttpMethod.GET,"/articles/**").permitAll()
//获取token
.antMatchers(HttpMethod.POST, "/tokens").permitAll().and()
`这里写代码片` //除上面外的所有请求全部需要鉴权认证
.authorizeRequests().anyRequest().authenticated().and();
//Filter要放到是否认证的配置之后
// 禁用缓存
httpSecurity
.headers().cacheControl();
}
}这个SecurityConfig中的configure方法写了哪些请求不需要进行登录。
邮件
代码主要在service/email下面,依赖了JavaMail,Thymeleaf和Spring Async。
Spring Async是ThreadPoolExecutor的封装,config/ExecutorConfig里配置了线程池的相关参数,主要是发送邮件可能比较慢,使用一个线程池实现异步任务可以加快响应速度。
邮件模板放在/src/main/resources/templates里,比如activation.html是激活邮件的模板。
<html lang="zh" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"/>
<title>Titletitle>
head>
<body>
您好,这是验证邮件,请点击下面的链接完成验证,<br/>
<a href="#" th:href="@{ 'http://localhost:8080/users/'+${id}+'/activation'(activationCode=${activationCode}) }">激活账号a>
body>
html>其中需要一个activationCode的参数。这个参数在sendHTML方法中会传入。
sendHTML方法里使用了一点技巧,Map参数封装了邮件模板中的key和value,比如key是activationCode,value是激活码。subject是邮件模板的名字,比如activation。
这个模板的名字还在resources/email-subject文件中使用到,用于确定邮件的主题名。
@Service
@Async("emailExecutor")
@ConfigurationProperties(prefix = "spring.mail")
@Getter
@Setter
@Slf4j
public class EmailServiceImpl implements EmailService {
@Autowired
private JavaMailSender javaMailSender;
@Autowired
private TemplateEngine templateEngine;
@Autowired
private EmailSubjectProperties subjectProperties;
private String username;
@Override
public void sendHTML(String to, String subject, Map params, List filePaths) {
Context context = new Context();
for (Map.Entry entry : params.entrySet()) {
context.setVariable(entry.getKey(), entry.getValue());
}
String emailContent = templateEngine.process(subject , context);
send(to, subjectProperties.getProperty(subject), emailContent, filePaths);
}
@Override
public void send(String to, String subject, String content, List filePaths) {
MimeMessage message = javaMailSender.createMimeMessage();
try {
MimeMessageHelper helper = new MimeMessageHelper(message, true);
//true表示需要创建一个multipart message
helper.setFrom(username);
helper.setTo(to);
helper.setSubject(subject);
helper.setText(content, true);
if (filePaths != null && filePaths.size() > 0) {
File file;
FileSystemResource fileSystemResource;
for (String filePath : filePaths) {
file = new File(filePath);
if (!file.exists()) {
throw new FileNotFoundException(filePath);
}
fileSystemResource = new FileSystemResource(file);
helper.addAttachment(filePath.substring(filePath.lastIndexOf(File.separator)), fileSystemResource);
}
}
} catch (MessagingException e) {
throw new RuntimeException(e);
}
javaMailSender.send(message);
}
} WebSocket
这里使用WebSocket实现了消息推送,群聊和单聊。
相关代码在skeleton/config/web/WebSocketConfig,skeleton/controller/chat/WsController,skeleton/src/main/resources/templates/ws.html。
参考资料:
http://lrwinx.github.io/2017/07/09/%E5%86%8D%E8%B0%88websocket-%E8%AE%BA%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1/
http://docs.spring.io/spring/docs/current/spring-framework-reference/html/websocket.html
http://blog.csdn.net/daniel7443/article/details/54377326
http://www.cnblogs.com/winkey4986/p/5622758.html
功能:
- 实现服务器端的消息推送,实时页面刷新
- 即时通讯,单聊&群聊
实现:
- @EnableWebSocketMessageBroker注解表示开启使用STOMP协议来传输基于代理的消息,Broker就是代理的意思。
- registerStompEndpoints方法表示注册STOMP协议的节点,并指定映射的URL。
- stompEndpointRegistry.addEndpoint(“/endpointSang”).withSockJS();这一行代码用来注册STOMP协议节点,同时指定使用SockJS协议。
- configureMessageBroker方法用来配置消息代理,由于我们是实现推送功能,这里的消息代理是/topic
配置:
- registry.enableSimpleBroker(“/topic”,”/user”);
- registry.setApplicationDestinationPrefixes(“/app”);
- registry.setUserDestinationPrefix(“/user/”);
第一个是作为@SendTo的前缀
第二三个是作为客户端发送信息send的前缀,后接@MessageMapping
身份验证:
JWT
见WebSocketConfig
消息推送:
客户端有两种消息发送方式:
1. 经过了服务器编写的MessageHandler(@MessageMapping),适用于需要服务器对消息进行处理的,客户端将消息发送给服务器,服务器将消息处理后
广播给所有用户。
示例:客户端订阅了/greetings,并会向/hello发送数据
实现:
- 服务器:@MessageMapping(“/hello”) @SendTo(“/topic/greetings”)
- 客户端:stompClient.send(“/app/hello”, {}, JSON.stringify(…));
stompClient.subscribe(‘/topic/greetings’, function (response) {
showResponse(JSON.parse(response.body).body);
});
- 不经过服务器,客户端发送的消息直接广播给所有用户,此时send和subscribe的路径是一样的
示例:客户端订阅了/greetings,并会向/greetings发送数据
实现:
- 服务器:什么都不用做
- 客户端:stompClient.send(“/topic/greetings”, {}, JSON.stringify(…));
stompClient.subscribe(‘/topic/greetings’, function (response) {
showResponse(JSON.parse(response.body).body);
});
共同点:都需要登录
@MessageMapping 客户端发送路径
@MessageMapping注解和我们之前使用的@RequestMapping类似。客户端向该(ApplicationPrefix+@MessageMapping)路径发送消息。
@MessageMapping(“/hello”)
stompClient.send(“/app/hello”, {}, JSON.stringify({‘body’: name}));
客户端会先将信息发送到代理(Broker,位于服务器),然后Broker会再将处理后的信息发送给客户端@SendTo 客户端接收路径
@SendTo注解表示当服务器有消息需要推送的时候,会对订阅了@SendTo中路径的浏览器发送消息。
@SendTo(“/topic/xxx”)中必须要以WebSocketConfig中messageBroker中设置的任一Prefix(“/topic”)为前缀
聊天
@SendToUser
发送给单一客户端的标志
注意是谁请求的发送给谁convertAndSend
template.convertAndSend(“/topic/hello”,greeting) //广播convertAndSendToUser
convertAndSendToUser(userId, “/message”,userMessage) //一对一发送,发送特定的客户端@MessageExceptionHandler
ElasticSearch
ES是一个分布式的搜索引擎,当然我这里只是使用了一个单机的ES。
代码见skeleton/domain/entity/article,skeleton/dao/article和skeleton/service/article。
实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@Document(indexName = "spring_boot_skeleton",type="article",shards = 5,replicas = 1,indexStoreType = "fs",refreshInterval = "-1")
public class ArticleDO {
@Id
private Long id;
private String author;
private String title;
private String body;
}在实体类上加入
@Document
(indexName=”article_index”, //索引库的名称,个人建议以项目的名称命名(相当于一个Database)
indexName 配置必须是全部小写,不然会出异常。
type=”article”, //类型,个人建议以实体的名称命名(相当于一张表)
shards=5, //默认分区数
replicas=1, //每个分区默认的备份数
indexStoreType=”fs”, //索引文件存储类型
refreshInterval=”-1” //刷新间隔
)
在需要建立索引的类上加上@Document注解,即表明这个实体需要进行索引。默认情况下这个实体中所有的属性都会被建立索引、并且分词。
在主键上加入@Id
我们通过@Field注解来进行详细的指定。
@Field
(format=DateFormat.date_time, //default DateFormat.none;
index=FieldIndex.no, //默认情况下分词
store=true, //默认情况下不存储原文
type=FieldType.Object) //自动检测属性的类型
private Date postTime;
DAO
public interface ArticleRepository extends ElasticsearchRepository<ArticleDO,Long> {
List findByBodyContaining(String keyWord);
} 虽然这里只写了一个方法,但是由于继承了通用Repository,因此实际上还可以使用很多其他方法。我的实现是基于Spring Data ElasticSearch,使用非常类似于Spring Data JPA,只需要按照一定规则写出方法名即可完成查询,不需要去写ES的查询DSL。
Service
@Service
@Slf4j
public class ArticleServiceImpl implements ArticleService {
@Autowired
private ArticleRepository articleRepository;
private static final String SCORE_MODE_SUM = "sum"; // 权重分求和模式
private static final Float MIN_SCORE = 10.0F; // 由于无相关性的分值默认为 1 ,设置权重分最小值为 10'
@Override
public void save(ArticleDO articleDO) {
articleRepository.save(articleDO);
}
@Override
public void saveAll(List articles) {
articleRepository.save(articles);
}
@Override
public Iterable findAll() {
Iterable all = articleRepository.findAll();
log.info("iterable className:{}", all.getClass().getName());
return all;
}
@Override
public List findByBodyContaining(String keyword) {
return articleRepository.findByBodyContaining(keyword);
}
@Override
public Page findByBodyContainingWithHighlight(String keyword, Integer pageNum, Integer pageSize) {
FunctionScoreQueryBuilder functionScoreQueryBuilder = QueryBuilders.functionScoreQuery()
.add(QueryBuilders.matchPhraseQuery("title", keyword).analyzer("ik_smart"),
ScoreFunctionBuilders.weightFactorFunction(1000))
.add(QueryBuilders.matchPhraseQuery("body", keyword).analyzer("ik_smart"),
ScoreFunctionBuilders.weightFactorFunction(500))
.scoreMode(SCORE_MODE_SUM).setMinScore(MIN_SCORE);
// 分页参数
Pageable pageable = new PageRequest(pageNum, pageSize);
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withPageable(pageable)
.withQuery(functionScoreQueryBuilder)
.build();
log.info("DSL:{}", query.getQuery().toString());
return articleRepository.search(query);
}
} 总结查询方式
Query keywords(查询关键字)
关键字 例子
对应的Elasticsearch查询语句
And findByNameAndPrice
{“bool” : {“must” : [ {“field” : {“name” : “?”}}, {“field” : {“price” : “?”}} ]}}
Or findByNameOrPrice
{“bool” : {“should” : [ {“field” : {“name” : “?”}}, {“field” : {“price” : “?”}} ]}}
Is findByName
{“bool” : {“must” : {“field” : {“name” : “?”}}}}
Not findByNameNot
{“bool” : {“must_not” : {“field” : {“name” : “?”}}}}
LessThanEqual findByPriceLessThan
{“bool” : {“must” : {“range” : {“price” : {“from” : null,”to” : ?,”include_lower” : true,”include_upper” : true}}}}}
GreaterThanEqual findByPriceGreaterThan
{“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : null,”include_lower” : true,”include_upper” : true}}}}}
Before findByPriceBefore
{“bool” : {“must” : {“range” : {“price” : {“from” : null,”to” : ?,”include_lower” : true,”include_upper” : true}}}}}
After findByPriceAfter
{“bool” : {“must” : {“range” : {“price” : {“from” : ?,”to” : null,”include_lower” : true,”include_upper” : true}}}}}
Like findByNameLike
{“bool” : {“must” : {“field” : {“name” : {“query” : “?*”,”analyze_wildcard” : true}}}}}
StartingWith findByNameStartingWith
{“bool” : {“must” : {“field” : {“name” : {“query” : “?*”,”analyze_wildcard” : true}}}}}
EndingWith findByNameEndingWith
{“bool” : {“must” : {“field” : {“name” : {“query” : “*?”,”analyze_wildcard” : true}}}}}
Containing findByNameContaining
{“bool” : {“must” : {“field” : {“name” : {“query” : “?”,”analyze_wildcard” : true}}}}}
In findByNameIn(Collectionnames)
{“bool” : {“must” : {“bool” : {“should” : [ {“field” : {“name” : “?”}}, {“field” : {“name” : “?”}} ]}}}}
NotIn findByNameNotIn(Collectionnames)
{“bool” : {“must_not” : {“bool” : {“should” : {“field” : {“name” : “?”}}}}}}
True findByAvailableTrue
{“bool” : {“must” : {“field” : {“available” : true}}}}
False findByAvailableFalse
{“bool” : {“must” : {“field” : {“available” : false}}}}
OrderBy findByAvailableTrueOrderByNameDesc
{“sort” : [{ “name” : {“order” : “desc”} }],”bool” : {“must” : {“field” : {“available” : true}}}}
@Query
public interface BookRepository extends ElasticsearchRepository
自定义Query
Iterable search(QueryBuilder query);
Page search(QueryBuilder query, Pageable pageable);
Page search(SearchQuery searchQuery);
Page searchSimilar(T entity, String[] fields, Pageable pageable);
注意:Mybatis PageHelper 的起始页码是1,而Spring Data分页的起始页码是0
它们的Page也不一样,统一使用(将起始页码统一为1)时建议前端只看
total
pages
pageNum
pageSize
size
这些个属性。
定时任务
定时任务是基于Spring Scheduler实现的,代码在skeleton/config/SchedulerConfig和skeleton/scheduler。
@Configuration
@EnableScheduling
@ConfigurationProperties(prefix = "scheduler")
@PropertySource("classpath:task.properties")
@Getter
@Setter
public class SchedulerConfig implements SchedulingConfigurer {
private Integer poolSize;
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
taskRegistrar.setScheduler(taskExecutor());
}
@Bean(destroyMethod="shutdown")
public Executor taskExecutor() {
return Executors.newScheduledThreadPool(poolSize);
}
}这里配置了用于处理定时任务的线程池的大小。
Scheduler:
/**
* 业务相关的作业调度
* 1)cron
* 字段 允许值 允许的特殊字符
* 秒 0-59 , - * /
* 分 0-59 , - * /
* 小时 0-23 , - * /
* 日期 1-31 , - * ? / L W C
* 月份 1-12 或者 JAN-DEC , - * /
* 星期 1-7 或者 SUN-SAT , - * ? / L C #
* 年(可选) 留空, 1970-2099 , - * /
*
* "*"字符代表所有可能的值
* "?"字符仅被用于天(月)和天(星期)两个子表达式,表示不指定值
* "/" 字符用来指定数值的增量
* "L" 字符仅被用于天(月)和天(星期)两个子表达式,表示一个月的最后一天或者一个星期的最后一天
* 6L 可以表示倒数第6天
*
*
* 示例:
* "0 0 12 * * ?" 每天中午十二点触发
* "0 15 10 ? * *" 每天早上10:15触发
* "0 15 10 * * ?" 每天早上10:15触发
* "0 15 10 * * ? *" 每天早上10:15触发
* "0 15 10 * * ? 2005" 2005年的每天早上10:15触发
* "0 * 14 * * ?" 每天从下午2点开始到2点59分每分钟一次触发
* "0 0/5 14 * * ?" 每天从下午2点开始到2:55分结束每5分钟一次触发
* "0 0/5 14,18 * * ?" 每天下午2点至2:55和6点至6点55分两个时间段内每5分钟一次触发
* "0 0-5 14 * * ?" 每天14:00至14:05每分钟一次触发
* "0 10,44 14 ? 3 WED" 三月的每周三的14:10和14:44触发
* "0 15 10 ? * MON-FRI" 每个周一,周二,周三,周四,周五的10:15触发
* "0 15 10 15 * ?" 每月15号的10:15触发
* "0 15 10 L * ?" 每月的最后一天的10:15触发
* "0 15 10 ? * 6L" 每月最后一个周五的10:15触发
* "0 15 10 ? * 6#3" 每月的第三个周五的10:15触发
* "0 0/5 * * * ?" 每五钟执行一次
*
*
* 2)fixedRate:每隔多少毫秒执行一次该方法。如:
*
* //@Scheduled(fixedRate = 2000) // 每隔2秒执行一次
*
* 3)fixedDelay:当一次方法执行完毕之后,延迟多少毫秒再执行该方法。
*
* 4)@Scheduled(initialDelay=1000, fixedRate=5000)
*
* @Author SinjinSong
*/
@Component
@Slf4j
public class Scheduler {
@Autowired
private RedisCacheManager redisCacheManager;
// /**
// * 每隔1分钟定时清理缓存
// */
// @Scheduled(cron = "0 0/1 * * * ? ")
// public void cacheClear() {
// log.info("清空缓存");
// redisCacheManager.clearCache();
// }
}cron表达式可以在这个网站
http://cron.qqe2.com/
上自动生成。
环境部署
下面开始进入正题,研究如何将代码运行起来。

这里我们使用VMWare虚拟机来搭建同一网段下的服务器集群,模拟真实环境下的一个机房,之前本来打算用腾讯云服务器,但是没钱租那么多台…。直接在虚拟机中操作不是很方便,这里使用远程机器管理软件XShell5,批量连接多台服务器,配合Xftp5风味更佳。
这里我们采取循序渐进的方式部署这些服务器。
虚拟机安装
- 先下载一个CentOS 7镜像,必须是DVD或者Everything的,不能是Minimal。
然后在VMWare中安装。 - 安装好后设置镜像的固定IP地址
http://www.cnblogs.com/magialmoon/archive/2013/08/10/3250393.html
vi /etc/sysconfig/network-scripts/ifcfg-ens33
效果如下:
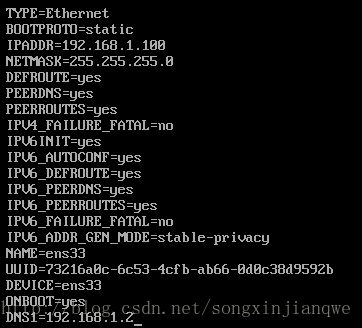
其中的IPADDR便是本机的IP地址。 - 拷贝镜像
重新设置第二个镜像的IP地址
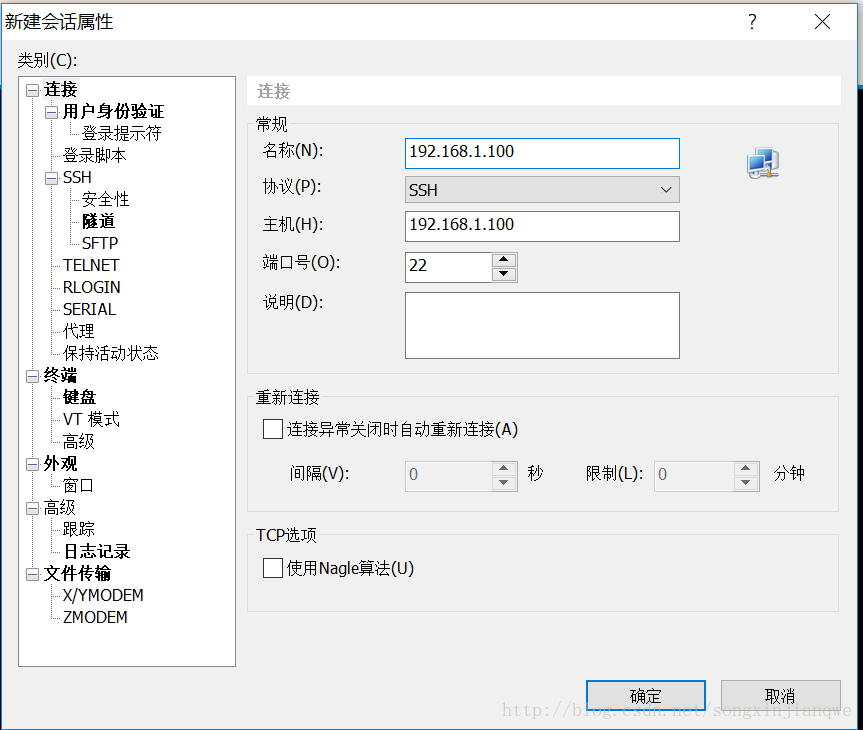
只需要改一个IPADDRXShell连接虚拟机
在XShell中新建会话。
- 修改每个虚拟机的hostname,目的是便于区分每台虚拟机的任务。
vi /etc/sysconfig/network
修改 HOSTNAME=别名
vi /etc/hosts
添加 192.168.xx.xx 别名1 别名2
然后重启服务器才能看到效果,修改IP地址也需要重启。 - 关闭防火墙
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
最简版本(对应着架构演变的第二步)
100:Spring Boot Application,只需要安装jdk
java -jar xxxxx.jar –spring.profiles.active=pro
101:Redis ,只需要安装redis
106:MySQL,只需要安装mysql
105:ES,只需要安装ElasticSearch
100指的是192.168.1.100这台机器。
必备软件
gcc
wget
telnet
使用 yum -y install 软件名 安装
安装JDK
首先在oracle官网上找到下载链接
http://download.oracle.com/otn-pub/java/jdk/8u144-b01/090f390dda5b47b9b721c7dfaa008135/jdk-8u144-linux-x64.rpm?AuthParam=1502364547_0581e92a8d5cce84553be8207a02665a
然后在主机中使用wget命令下载
wget http://download.oracle.com/otn-pub/java/jdk/8u144-b01/090f390dda5b47b9b721c7dfaa008135/jdk-8u144-linux-x64.rpm?AuthParam=1502364547_0581e92a8d5cce84553be8207a02665a
rpm -ivh jdk-8u144-linux-x64.rpm\?AuthParam\=1502364547_0581e92a8d5cce84553be8207a02665a
java –version
[root@app /]# find -name java
./etc/pki/ca-trust/extracted/java
./etc/pki/java
./etc/alternatives/java
./var/lib/alternatives/java
./usr/bin/java
./usr/java
./usr/java/jdk1.8.0_144/bin/java
./usr/java/jdk1.8.0_144/jre/bin/java
vi /etc/profile
补充
JAVA_HOME=/usr/java/jdk1.8.0_144
JRE_HOME=/usr/java/jdk1.8.0_144/jre
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME PATH CLASSPATH重启服务器
echo $JAVA_HOME
安装Redis
wget http://download.redis.io/releases/redis-3.2.10.tar.gz
tar -xzvf redis-3.2.10.tar.gz
yum –y install gcc
cd /redis-3.2.10
make MALLOC=libc
cd src
make install
cd ..
vi redis.conf
将daemonize改为yes
将bind注释掉
加上一行 requirepass 密码
启动服务器:
/usr/local/bin/redis-server /opt/redis/redis.conf
启动客户端:
/usr/local/bin/redis-cli
安装MySQL
wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
rpm -qa | grep mariadb
rpm -e –nodeps mariadb-libs-5.5.52-1.el7.x86_64
rpm -Uvh mysql57-community-release-el7-11.noarch.rpm
yum install –y mysql-community-server
service mysqld start
grep ‘temporary password’ /var/log/mysqld.log
mysql -uroot –p
mysql>SET PASSWORD = PASSWORD(‘Sxj19961226.’);
mysql>ALTER USER ‘root’@’localhost’ PASSWORD EXPIRE NEVER;
mysql> flush privileges;
mysql>quit;
chkconfig mysqld on
允许外部应用访问:

安装ES
需要先安装JDK
wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.4.4/elasticsearch-2.4.4.tar.gz
tar -zxvf elasticsearch-2.4.4.tar.gz -C /usr/local
/usr/local/elasticsearch-2.4.4/bin/elasticsearch -d -Des.insecure.allow.root=true
Elasticsearch 的配置文件在 /usr/local/elasticsearch-2.4.4/config/elasticsearch.yml
打开配置文件,加入如下配置
#集群名称,若有多台服务器
cluster.name: elasticsearch
#节点名称,本服务器的名称
node.name: node-1
#监听端口,默认为 9200
http.port: 9200
network.host: 0.0.0.0测试:curl http://localhost:9200/
每次重启后执行的命令
101,102,103:
/usr/local/bin/redis-server /opt/redis/redis.conf
105:
/usr/local/elasticsearch-2.4.4/bin/elasticsearch -d -Des.insecure.allow.root=true
106:
service mysqld start
100:
java –jar xxx.jar –spring.profiles.active=pro
加入Redis集群
步骤
102,103,107,108,109,110都安装Redis
102:master1
103:master2
107:master3
108:slave1
109:slave2
110:slave3每个机器的redis.conf
修改:
daemonize yes
bind 本机的IP
添加:
requirepass 130119
masterauth 130119
cluster-enabled yes
cluster-config-file
cluster-node-timeout 5000
appendonly yes- 每台机器
yum –y install ruby
gem update –system
gem install redis - 每台机器
vi /usr/local/share/gems/gems/redis-3.3.3/lib/redis/client.rb
将password改为”yourpassword” - 每台机器
/usr/local/bin/redis-server /opt/redis/redis.conf - 复制集群管理程序到/usr/local/bin
应该是哪一个节点都可以,这里使用102节点
cp /opt/redis-3.2.10/src/redis-trib.rb /usr/local/bin
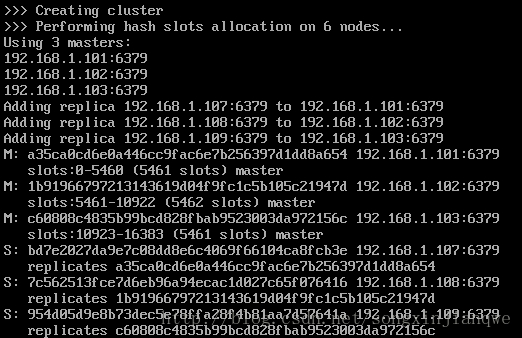
创建集群:
/usr/local/bin/redis-trib.rb create –replicas 1 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 192.168.1.107:6379 192.168.1.108:6379 192.168.1.109:6379
默认前三个是主节点,后三个是从节点
- 进入客户端
/usr/local/bin/redis-cli -c -h 192.168.1.101 -a 130119
每次重启后应该执行的命令
102,103,107,108,109,110
将每个节点下aof、rdb、nodes.conf本地备份文件删除;
放在root目录下
rm -rf /root/dump.rdb
rm -rf /root/nodes.conf/usr/local/bin/redis-server /opt/redis/redis.conf
- 102节点:
/usr/local/bin/redis-trib.rb create –replicas 1 192.168.1.102:6379 192.168.1.103:6379 192.168.1.107:6379 192.168.1.108:6379 192.168.1.109:6379 192.168.1.110:6379
105
/usr/local/elasticsearch-2.4.4/bin/elasticsearch -d -Des.insecure.allow.root=true
106
service mysqld start
100
java –jar xxx.jar –spring.profiles.active=pro
加入MySQL集群
106:MySQL写库(主库)
拷贝作为111,112,作为两个读库(从库)
主库用写的数据源,从库用读的数据源。
http://blog.csdn.net/ggjlvzjy/article/details/51544016
一共需要做两步:
1、Java代码实现动态切换数据源,即读写分离
2、保证主库和从库之间的同步,即主从复制,基于MySQL 的Replication
(1) master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
(2) slave将master的binary log events拷贝到它的中继日志(relay log);
(3) slave重做中继日志中的事件,将改变反映它自己的数据。
读写分离
skeleton/config/db下的配置文件都是为读写分离服务的,主要目的是读数据时使用读库,写数据使用写库,需要配置多个数据源并能动态切换。
主要参考了
http://blog.csdn.net/ggjlvzjy/article/details/51544016
但我的实现又有一些不同。
@Aspect
@Order(1)
@Configuration
@Slf4j
public class DataSourceAspect {
@Before("@annotation(transaction)")
public void switchDataSourceType(Transactional transaction) {
if(transaction.readOnly()){
DataSourceContextHolder.read();
log.info("dataSource切换到:Read");
}else{
DataSourceContextHolder.write();
log.info("dataSource切换到:Write");
}
}
}在数据源切换这部分,有的实现是根据方法名,我觉得不行,这样太死板了。我觉得根据@Transactional的是否设置readOnly判断是读还是写更灵活,只是所有service的方法都需要写一个@Transactional注解。
启动对@Aspectj的支持 true为cglib,false为jdk代理,为true的话,会导致拦截不了mybatis的mapper
注意数据源的切换必须要在事务开启之前,不能在开启事务时没有确定数据源。事务默认的Order是MAX_INTEGER,自定义的Aspect可以使用@Order来指定优先级,数值越小,优先级越高。
动态数据源切换与事务:
事务是加在Service上的,也就是一个service方法中间不能切换数据源
如果数据源的切换是拦截了DAO,那么是有问题的,因为在service开启事务时无法确定数据源,并且同一个事务中间即使调用了多个dao方法,也不能切换数据源。
解决方法1是拦截service
解决方法2是将事务加在service上,但是不推荐这样做。
现在采用的是方法1,是根据service的方法上的@Transactional注解的readOnly属性判断
这就要求我们在编写service时:
所有service上的方法都必须加上@Transactional注解
如果该方法不涉及任何的写操作,那么必须指定readOnly属性为true
该属性的默认值是false。
主从复制
参考资料
http://www.cnblogs.com/phpstudy2015-6/p/6485819.html
http://blog.csdn.net/hguisu/article/details/7325124/
http://www.cnblogs.com/luckcs/articles/2543607.html
http://369369.blog.51cto.com/319630/790921/
步骤
106有应用数据,111,112无应用数据,都安装了相同版本的MySQL
1. 主库修改/etc/my.cnf
在[mysqld]下面添加两行
log-bin=mysql-bin
server-id=106 不可重复,一般是IP地址最后一个数字
2. 从库修改/etc/my.cnf
server-id=111 不可重复,一般是IP地址最后一个数字
3. 重启所有服务器的mysql
service mysqld restart
4. 在主服务器上建立帐户并授权slave:
mysql>GRANT REPLICATION SLAVE ON . to ‘用户名,非root’@’从库IP地址’ identified by ‘密码’; //一般不用root帐号,表示所有客户端都可能连,只要帐号,密码正确,此处%可用具体客户端IP代替,如192.168.145.226,加强安全。
在Master的数据库中建立一个备份帐户:每个slave使用标准的MySQL用户名和密码连接master。进行复制操作的用户会授予REPLICATION SLAVE权限。用户名的密码都会存储在文本文件master.info中。
这里是建立一个Master的账号,Slave可以使用该账号访问Master的数据。
比如:
grant replication slave on . to ‘sinjinsong’@’192.168.1.111’ identified by ‘yourpassword’;
grant replication slave on . to ‘sinjinsong’@’192.168.1.112’ identified by ‘yourpassword’;
5. 关停Master服务器,将Master中的数据拷贝到Slave服务器中,使得Master和slave中的数据同步,并且确保在全部设置操作结束前,禁止在Master和slave服务器中进行写操作,使得两数据库中的数据一定要相同!
mysql>FLUSH TABLES WITH READ LOCK;
mysql> show master status;

6. 将主库的数据拷贝到从库中
将主服务器的数据文件(其目录在my.cnf中,比如/var/lib/mysql)复制到从服务器,建议通过tar归档压缩后再传到从服务器解压。
tar -cvf /opt/mysql.tar /var/lib/mysql
然后将其拷贝到从库服务器中
scp /opt/mysql.tar 192.168.1.111:/opt
在从库中将该tar包解压到/var/lib/mysql中
先删除/var/lib/mysql,然后解压
rm –rf /var/lib/mysql
cd /
tar -xvf /opt/mysql.tar
7. 取消主数据库锁定
mysql> UNLOCK TABLES;
8. 从库重启mysql
重启失败
查看/var/log/mysqld.log,发现
usr/sbin/mysqld: File ‘./mysql-bin.index’ not found (Errcode: 13)
于是输入
chcon -Rt mysqld_db_t /var/lib/mysql
chcon -Ru system_u /var/lib/mysql
chown -R mysql:mysql /var/lib/mysql
9. 在从库中进行同步
执行同步SQL语句
mysql> change master to
master_host=’192.168.10.130’,
master_user=’之前指定的用户名’,
master_password=’之前指定的密码’,
master_log_file=’之前查看的主库的FILE的名字’,
master_log_pos=之前查看的主库的FILE的位置;
比如:
change master to master_host=’192.168.1.106’,master_user=’sinjinsong’,master_password=”yourpassword,master_log_file=’mysql-bin.000003’,master_log_pos=154;
然后
mysql>start slave; //启动从服务器复制功能
mysql> show slave status\G
Slave_IO及Slave_SQL进程必须正常运行,即YES状态,否则都是错误的状态(如:其中一个NO均属错误)。
如果Slave_IO是NO,并且日志中显示Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work.
那么需要修改auto.cnf
找到data文件夹下的auto.cnf文件,修改里面的uuid值,保证各个db的uuid不一样,重启db即可
停止:stop slave;
每次重启后执行的命令
102,103,107,108,109,110:
将每个节点下aof、rdb、nodes.conf本地备份文件删除;
放在root目录下
rm -rf /root/dump.rdb
rm -rf /root/nodes.conf
/usr/local/bin/redis-server /opt/redis/redis.conf102节点:
/usr/local/bin/redis-trib.rb create –replicas 1 192.168.1.102:6379 192.168.1.103:6379 192.168.1.107:6379 192.168.1.108:6379 192.168.1.109:6379 192.168.1.110:6379
105:
/usr/local/elasticsearch-2.4.4/bin/elasticsearch -d -Des.insecure.allow.root=true106,111,112:
service mysqld start100:
java –jar xxx.jar –spring.profiles.active=pro
总结
限于篇幅,不能将涉及的所有技术点都讲一遍,大家可以自行阅读源码,以及搜索有关文章学习。如果想在本机把代码跑起来的话,最好是采用架构演进的第一步,部署起来较为方便,而且功能也都有。
虽然看起来涉及了大量的技术点,但也不是一口气学下来的,大概陆陆续续学了半年多,才把这些技术都整合了起来。如果是初学JavaEE的新手,建议从传统的SSM学起,我在Github上也有类似的Repo:
https://github.com/songxinjianqwe/JavaWebSkeleton
集中式的SpringBoot的Repo:
https://github.com/songxinjianqwe/SpringBootCentralizedSkeleton
分布式的SpringBoot的Repo:
https://github.com/songxinjianqwe/SpringBootDistributedSkeleton
这种架构基本可以适用于中小型Web项目,像淘宝这种大型Web项目则涉及业务拆分和服务化,比如现在流行的MicroService微服务。
下一步的学习目标就是基于Dubbo实现服务化分布式项目,以及阅读各种框架的源码,提升自己的内功。
本篇文章就是这些,谢谢大家,如果有任何疑问可以留言或在Github上联系我。