阿里云DTS订阅实现实时运营服务的方案及注意事项
一、背景
尝试在数据层面实现一个业务事件的侦听和发布的服务(即实时运营)。以使在公司多个不同系统或服务中都可以实时获取到事件通知,进而做各自对应的触发业务(比如 C 端可以即时为用户发送通知,B 端可以为运营人员发送短信和邮件等等)。
本文主要针对使用阿里云 DTS 同步订阅,实现类似【实时运营】这样的服务的过程中需要注意的点。
二、抛出问题
- 为什么不放在业务层?
- 如何获取数据的变化?
- 数据怎样具体定义一个事件?
2.1 为什么不放在业务层
想要监听某个业务事件,最简单的方式肯定是在业务代码里添加一些事件发布的逻辑(比如向DB或MQ中放置一条事件记录),当需要监听另一个业务事件时,重复这些操作,继续添加另外一些逻辑。
但是这样处理也有两方面的缺点:
- 核心业务代码和事件监听代码没有解耦(当然可以通过恰当的设计模式或方案来一定程度上避免)
- 每次添加一些新事件的监听,都要重新发版(当然监听事件比较少的情况下,这一点的影响较小,可以提前都规划好所有的事件;但是对于监听事件比较多且可能容易变化的情况就比较头疼),而对于很多业务系统来说,可能不会这么频繁地发布新版。
而结合我们自身的实际情况,选择在数据层做处理。
2.2 如何获取数据的变化
数据层要做事件的监听处理,必然需要实时得知数据的变化,然后再以特定的数据变化动作,来定义某种业务事件的发生。那么如何实时获取数据的变化?答案是可以借助数据库的 binlog 监听服务。
这种服务也有一些开源的实现,也可以借助于阿里云的 DTS 订阅服务(https://help.aliyun.com/document_detail/145715.html),其本质上也一样,另外具备Kafka生产者的功能,用来将 binlog 数据放在 Kafka 中。
2.3 数据怎样具体定义一个事件
假设我们已经购买并配置好了 DTS 订阅服务,且官方给出的 消费者 Demo 也跑通拿到数据了,我们先看一下消费者 Demo 输出的数据长什么样:
[2020-05-06 13:47:13,162] INFO recordID [3313806458]source [{"sourceType": "MySQL", "version": "5.7.20-log"}]dbTable [unifiedorder_db.checkoutapply]recordType [UPDATE]recordTimestamp [1588744030]extra tags [{pk_uk_info={"PRIMARY":["pid"]}, readerThroughoutTime=1588744030271},]
Field [pid]Before [30598]After [30598]
Field [contractId]Before [59008]After [59008]
Field [userId]Before [211072]After [211072]
Field [roomId]Before [13042]After [13042]
Field [unitMode]Before [0]After [0]
Field [operateType]Before [1]After [1]
Field [blame]Before [1]After [1]
Field [checkOutDate]Before [2019-08-31 00:00:00]After [2019-08-31 00:00:00]
Field [status]Before [450]After [450]
Field [lockState]Before [0]After [1]
Field [createBy]Before [[email protected]]After [[email protected]]
Field [createAt]Before [2019-08-31 21:06:31]After [2019-08-31 21:06:31]
Field [modifyBy]Before [batchAdmin]After [batchAdmin]
Field [modifyAt]Before [2020-05-06 13:42:12]After [2020-05-06 13:47:10]
Field [displayStatus]Before [WRD]After [WRD]
Field [remark]
(NotifyDemo)结合上面日志的打印,可以看出这是一个完整的 binlog 变化的数据,数据还是比较全的,需要重点关注的是数据库操作类型 recordType、库表名 dbName、数据变化前后镜像 Field 和 Before 和 After。
通过这些关键信息,对于绝大多数事件的定义来说,已经完全足够。但是 Demo 处理后的数据的样式似乎不太令人满意,我们更期望是一个对象,即可以用 JSON 表示出来,所以我们可以自己做一下处理。
接着终于到了定义事件的时候了,不需要过多解释,我的表结构和数据定义如下:

三、填坑
目前相当数量的企业都选择企业云,使用各种服务,比如我们用到的阿里云上的 ECS、RDS、Redis、OSS、Kafka、DTS 同步/订阅、DataV、SSL、CDN、SLB、域名和容器等等。
然而,在某些云服务的使用中,才能发现一些不在说明文档中提到的坑和 Bug。是的,一般选择企业云有一部分原因都是信赖其可靠性,但是至少在我使用 Kafka 和 DTS 订阅时,踩了几步坑。
本文只提一下 DTS 订阅服务中需要注意的问题。在此之前,首先贴一下官方文档中的注意事项:
- 订阅通道保存最近24小时的数据,过时的数据将会从订阅通道中删除。
- 在订阅通道运行过程中,请勿使用gh-ost或pt-online-schema-change等类似工具执行在线DDL变更,否则可能导致订阅失败。
下面是笔者遇到的坑及解决方案:
3.1 官方Demo存在疑似Bug
官方给的 Java 版的 Demo 中,存在疑似 bug,我已提交到 github。该 bug 会导致消费者Demo服务重启后不能接着上次的消费进度继续消费。
bug 链接:https://github.com/LioRoger/subscribe_example/issues/17
解决方案也在 bug 中提到了。
3.2 数据分区只有1个
经笔者实践及与售后客服确认,DTS 订阅服务的 Kafka 数据分区只有1个。
确认对话截图如下:

所以带来的问题是,无法让多个消费者并行消费,在同一时刻只能有 1 个 DTS 消费者端工作。因此为了让我们的服务达到无感知切换,必须要启另一个服务作为主备中的备份,等到主节点需要升级或者宕掉的时候,副节点自动接着消费。
为了达到上述目的,有以下两种方案:
- 可以考虑配置 Kafka 的消费模式为 Subscribe(ps:Demo 默认 Assign 模式),这样通过消费组的作用,轻松实现。但是 Demo 貌似对 Subscribe 模式的支持有问题,导致指定开始消费的时间戳不生效。所以需要自己熟悉并修改 Demo 中的处理。
- 面对分布式系统地问题,理所当然地可以借助 ZooKeeper 来实现主备切换,也比较简单,这里不去延伸。
3.3 消息幂等
严格来说,这一点不算坑,很多消息中间件的消费端都需要开发者们自己去考虑消息幂等性的问题。
就 Demo 来说,每次启动服务都是从指定的开始消费的时间戳开始消费数据的,而非消息偏移量。在这样的场景中可能会出现重复消费的问题,假设某一时间戳的数据量很大,在服务停掉时,这一时间戳的数据仍未消费完,那么在下次启动服务后,仍旧将从这个时间戳开始消费,而且是从这个时间戳最开始的那个偏移量开始,而前面这些偏移量对应的消息其实在我们上一次的服务中已经消费过了。
解决方案:
可以从 Demo 记录最新消费进度的文件 localCheckpointStore 中找到答案,将文件 localCheckpointStore 内容格式化后的数据结构如下:
{
"groupID": "dtstdfg57le212ittt",
"streamCheckpoint": [
{
"partition": 0,
"offset": 239468271,
"topic": "cn_hangzhou_rm_bp1r439675jqu3028_test_user",
"timestamp": 1590469246,
"info": "1590469246"
}
]
}可以看到里面记录了每次提交的最新消费时间戳和偏移量,所以我们在每次启动服务时,读取这个文件中的最新偏移量 offset 值,并在每条消息消费之前,比较当前消息的 offset 和文件中的 offset,若前者小于等于后者,则抛弃当前消息。
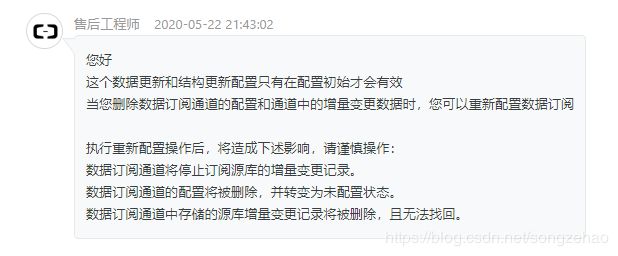
3.4 DTS控制台操作不生效
经与售后客服确认,DTS 订阅服务在控制台的某些操作是无效的(ps:而控制台没有给出应有的提示,让用户误以为操作成功。文档中也没看到这些注意事项说明)。
3.4.1 DTS控制台不能移除订阅对象
确认对话截图如下:


3.4.2 DTS控制台不能修改配置订阅数据类型
DTS 订阅的数据类型有两种:
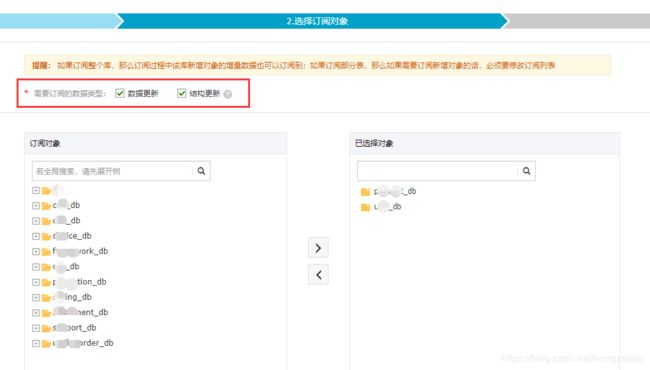
一旦创建好了一个数据订阅以后,再去修改它的订阅的数据类型是不生效的。
确认对话截图如下:

以上。