深度学习-何如计算误差(图片有问题,后期修复)
前言
误差计算是深度学习中的核心,非常重要!!! 关于误差计算,有如下概念:
- 损失函数(Loss Function) : 定义在单个样本上的, 算的是一个样本的误差
- 代价函数(Cost Function) : 定义在整个训练集上的, 是所有样本误差的平均, 也就是损失函数的平均
- 目标函数(Object Function): 最终优化的函数.等于经验风险+结构风险(也就是Cost Function+正则化项)
- 风险函数(Risk Function) : 风险函数是损失函数的期望
- 过拟合(Over-Fitting) : 过度拟合训练集, 导致它在真正预测时效果会很不好
- 正则化(Regularization) : 通过降低复杂模型的复杂度来防止过拟合的规则称为正则化,具体见'正则化'
- 极大似然估计(MLE) :
- 权重衰减(weight decay) : 具体见'正则化'
- Dropout : 具体见'Dropout'
- MSE: 均方误差(Mean squared error)
- RSS: 残差的平方和(residual sum of squares)
- 均方差代价函数: 见二次代价函数
下面我们举个例子解释一下:(图片来自Andrew Ng Machine Learning公开课视频):

上面三个图的函数依次为f1(x), f2(x), f3(x). 我们是想用这三个函数分别来拟合Price, Price的真实值记为Y
损失函数
我们给定x, 这三个函数都会输出一个f(X),这个输出的f(X)与真实值Y可能是相同的, 也可能是不同的. 为了表示我们拟合的好坏, 我们就用一个函数来度量拟合的程度:
这个函数就称为损失函数(loss function)或者叫代价函数(cost function) (有的地方将损失函数和代价函数没有细分也就是两者等同的).
损失函数越小, 就代表模型拟合的越好.
风险函数
那是不是我们的目标就只是让loss function越小越好呢?还不是!!!
由于我们输入输出的(X,Y)遵循一个联合分布, 但是这个联合分布是未知的(包含未知的样本),所以无法计算!!!
但是我们是有历史数据的-就是训练集, f(X)在训练集的平均损失称作经验风险
风险函数是损失函数的期望.所以我们的目标就是最小化经验风险,称为经验风险最小化
过拟合
经验风险最小就一定好吗?还不是!!!
我们看最右面的 f3(x) 的经验风险函数最小了, 因为它对历史的数据拟合的最好!!!
但是我们从图上来看它肯定不是最好的, 因为它过度学习训练集, 导致它在真正预测时效果会很不好, 这种情况称为过拟合(over-fitting)
过拟合不好,所以要尽量避免
防止过拟合, 比较常用的技术包括:
- 尽量减少选取参数的数量(当你舍弃一部分特征变量时, 你也舍弃了问题中的一些信息)
- L1, L2 范数
- 训练集合扩充,例如添加噪声、数据变换等
- Dropout
正则化(Regularization)
我们不仅要让经验风险尽量小, 还要让结构风险尽量小, 怎么解决???
通过对模型参数添加惩罚参数来限制模型能力,可以降低模型的复杂度来防止过拟合,这种规则称为正则化
正则化中我们将保留所有的特征变量, 但是会减小特征变量的数量级
我们定义了一个函数J(f) 用来度量模型的复杂度
常用的正则化公式:
- L1正则化项,标准如图(C0代表原始的代价函数, 后面那一项就是L1正则化项):
L1正则化项: 全部权重w的绝对值的和, 乘以λ/n
λ就是正则项系数, 权衡正则项与C0项的比重
L1正则化项求导:
上式中sgn(w)表示w的符号
L1正则化项对w的更新的影响:
比原始的更新规则多出了η * λ * sgn(w)/n这一项
通过上图可知:
在编程的时候令: sgn(0)=0, sgn(w>0)=1, sgn(w<0)=-1
当w为正时, 更新后的w变小; 当w为负时, 更新后的w变大;
它的效果就是使网络中的权重尽可能为0, 也就相当于减小了网络复杂度, 防止过拟合
L1 正则化可以理解为每次从权重中减去一个常数
- L2正则化项,标准如图(C0代表原始的代价函数, 后面那一项就是L2正则化项):
L2正则化项: 全部參数w的平方的和, 除以训练集的样本大小n
λ就是正则项系数, 权衡正则项与C0项的比重
'系数1/2'主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与'1/2'相乘刚好凑整
L2正则化项求导:
可以看到: L2对b的更新没有影响. 对w的更新有影响
L2正则化项对w的更新的影响:
w前面系数为'1−ηλ/n', 由于η、λ、n都是正的, 所以 '1−ηλ/n' 小于1
通过上图可知:
L2正则化的效果是减小w.这也就是权重衰减(weight decay)的由来
L2正则化效果实际上是使得参数a值每次都以一定的比例缩小, 防止参数变得过大, 防止过拟合
L2正则化可以理解为每次移除权重的 x%
通常情况下, 深度学习中只对参数添加约束, 对偏置项不加约束. 主要原因是偏置项一般需要较少的数据就能精确的拟合. 如果添加约束常常会导致欠拟合
目标函数
我们的目标是让经验风险尽量小, 还要让结构风险尽量小!!!
最优化经验风险和结构风险, 而这个函数就被称为目标函数, 公式如下:
结合上面的例子来分析:
- 最左面的f1(x) 结构风险最小(模型结构最简单), 但是经验风险最大(对历史数据拟合的最差)
- 最右面的f3(x) 经验风险最小(对历史数据拟合的最好), 但是结构风险最大(模型结构最复杂)
- 而f2(x) 达到了二者的良好平衡, 最适合用来预测未知数据集
没有最优的模型,只有更优的模型!!!
风险函数
机器学习的优化目标就是让预测值与真实值之间的误差越小越好, 这种差别也叫做风险
风险分为经验风险, 期望风险, 结构风险
- 经验风险(Empirical Risk) : 训练集的平均损失, 经验风险越小说明模型对训练集的拟合程度越好
- 结构风险(Structural Risk): 使用正则化度量模型结构的复杂度. 越复杂的模型,结构风险越大
- 期望风险(Expected Risk) : 所有样本(包含未知的样本和已知的训练样本)的平均损失
风险的性质:
- 经验风险表示的是局部的概念, 是可以可求的
- 期望风险表示的是全局的概念, 是理想化的不可求的
- 结构风险是针对模型复杂度的,用来折中 经验风险 与 期望风险
代价函数
什么是代价函数?
假设有训练样本(x,y), 模型为h, 参数为θ, h(θ) = θTx(θT表示θ的转置), 那么:
任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数就叫代价函数C(θ)
如果有多个样本, 则可以将所有代价函数的取值求均值, 记做J(θ)
总的代价函数J(θ)可以用来评价模型的好坏, 代价函数的性质:
- 对于每种算法来说, 代价函数不是唯一的
- 代价函数是参数θ的函数
- 代价函数越小说明模型和参数越符合训练样本
- J(θ)是一个标量
- 选择代价函数时, 最好挑选对参数θ可微的函数(全微分存在, 偏导数一定存在)
- 一个好的代价函数需要满足两个最基本的要求: 能够评价模型的准确性, 对参数θ可微
常用代价函数:
- 交叉熵函数(Cross Entropy Cost): 是一个常见的代价函数, 在神经网络中也会用到
- 二次代价函数(Quadratic Cost): 期望不符合,不太常用
二次代价函数(Quadratic Cost)
二次代价函数即均方差代价函数
二次代价函数: C表示代价, x表示样本, y表示实际值, a表示输出值, n表示样本的总数. 公式为:

当n=2时,简化公式为:

利用反向传播算法沿着梯度方向调整参数大小, w和b的梯度推导如下:
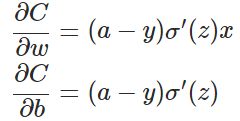
其中: z表示神经元的输入, δ表示激活函数.
从以上公式可以看出, w和b的梯度跟激活函数的梯度成正比, 激活函数的梯度越大, w和b的大小调整得越快.
而神经网络常用的激活函数为sigmoid函数, 该函数的曲线如下所示:

如图所示: 初始输出值为0.98对应的梯度明显小于输出值为0.82的梯度. 这就是初始的代价(误差)越大, 导致训练越慢的原因. 与我们的期望不符,即: 不能像人一样, 错误越大, 改正的幅度越大, 从而学习得越快.
更换激活函数解决这个问题,会引起更大问题!!! 所以不如换代价函数!!!
交叉熵代价函数(Cross Entropy Cost)
信息熵由香农提出, 它描述了数据的混乱程度. 熵越大, 混乱程度越高;反之, 熵越小, 混乱程度越低
交叉熵代价函数: C表示代价, x表示样本, y表示实际值, a表示输出值, n表示样本的总数. 公式为:
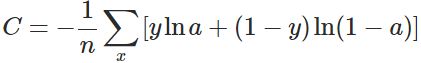
其中, x表示样本, n表示样本的总数. 那么重新计算参数w的梯度:
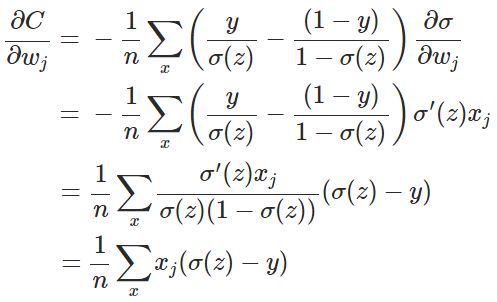
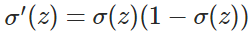
该梯度公式中的表示输出值与实际值之间的误差.所以当误差越大则梯度就越大,参数w调整得越快.
实际情况证明: 交叉熵代价函数带来的训练效果往往比二次代价函数要好!!!
损失函数
损失函数指的是对于单个样本的损失或误差.与代价函数的区别在于:代价函数是多样本的平均值
铰链损失(Hinge Loss)
用来解'间距最大化'的问题, 最有代表性的就是SVM(支持向量机)问题. 通用的函数表达式为:

y是预测值(-1到1之间), t为目标值(±1)
其含义为: y的值限定在-1到1之间. 当|y|>=1时, L(y)=0, 即并不鼓励分类器过度自信, 从而使得分类器可以更专注整体的分类误差.
Hinge Loss变种, 假设:
一方面, 我们可能更希望y更接近于一个概率, 即其值域最好是[0,1].
另一方面,很多时候我们希望训练的是两个样本之间的相似关系,而非样本的整体分类.
所以很多时候我们会用下面的公式:
l(y,y′) = max(0,m−y+y′)
其中: y是正样本的得分, y’是负样本的得分, m是margin(自己选一个数)
即我们希望正样本分数越高越好, 负样本分数越低越好, 但二者得分之差最多到m就足够了,差距增大并不会有任何奖励
铰链损失变种
一方面, 我们可能更希望y更接近于一个概率, 即其值域最好是[0,1]
一方面,很多时候我们希望训练的是两个样本之间的相似关系,而非样本的整体分类
所以很多时候我们会用下面的公式:
l(y,y′) = max(0,m−y+y′)
其中:
- y是正样本的得分
- y’是负样本的得分
- m是margin(自己选一个数)
- 即我们希望正样本分数越高越好, 负样本分数越低越好
- 但二者得分之差最多到m就足够了,差距增大并不会有任何奖励
对数损失函数或对数似然损失函数
对数损失函数(logarithmic loss function)或对数似然损失函数(log-likehood loss function)
假设样本服从伯努利分布(0-1分布), 那么可以通过概率的方式计算误差. 对数损失函数的标准形式:
上述公式表达的意思是:
样本X在分类Y的情况下, 使概率P(Y|X)达到最大值. 也就是说, 就是利用已知的样本分布, 找到最有可能(即最大概率)导致这种分布的参数值 或者说什么样的参数才能使我们观测到目前这组数据的概率最大. 因为Log函数是单调递增的, 所以logP(Y|X) 也会达到最大值,因此在前面加上负号之后, 最大化P(Y|X)就等价于最小化L
逻辑回归的P(Y=y|x)表达式如下:
其求导后的公式与交叉熵相似, 二者仅相差一个符号
对数损失函数用于'概率'方面,比如分类
Softmax损失函数(Softmax loss)
Softmax损失函数是Log损失函数的一种. Softmax损失函数的标准形式:
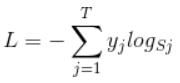
L是损失
Sj是softmax的输出向量S的第j个值, 表示的是这个样本属于第j个类别的概率
y是一个1*T的向量, 里面的T个值, yj是指向当前样本的真实标签
当输入P是softmax的输出时,Log损失函数即为Softmax损失函数
平方损失函数(Quadratic Loss Function)
平方损失函数 又称为 最小二乘法(Ordinary Least Squares), OLS
基本原则是: 最优拟合直线应该是使各点到回归直线的距离和最小的直线 - 即平方和最小
OLS是基于距离的, 而这个距离就是我们用的最多的欧几里得距离
Y-f(X)表示的是残差,整个式子表示的是残差的平方和.而我们的目的就是最小化这个目标函数值, 也就是最小化残差的平方和
如果预测的是一个任意实数(如回归),则无法使用交叉熵类的损失函数,可以使用OLS
均方误差损失函数(Mean-Square Error, MSE)
是反映估计量与被估计量之间差异程度的一种度量, 是目标变量与预测值之间距离平方之和
标准形式如图:

上式中, y为正确答案,而y'为神经网络给出的预测值
如果预测的是一个任意实数(如回归),则无法使用交叉熵类的损失函数,可以使用MSE
平均绝对误差损失函数(Mean Absolute Error, MAE)
反映估计量与被估计量之间差异程度的一种度量, 是目标变量与预测值之间差异绝对值之和
它在一组预测中衡量误差的平均大小, 而不考虑误差的方向. 标准形式如图:
上式中, y为正确答案,而h为神经网络给出的预测值
如果预测的是一个任意实数(如回归),则无法使用交叉熵类的损失函数,可以使用MAE
自定义损失函数
损失函数是可以自定义的,特此标记!!!
一个使用自定义损失函数的例子是机场准时的不对称风险。问题是:你要决定什么时候从家里出发,这样你才能在按时到达机场。我们不想太早走,在机场等上几个小时。同时,我们不想错过我们的航班。任何一方的损失都是不同的: 如果我们提前到达机场,情况真的没有那么糟;如果我们到得太晚而错过了航班,那真是糟透了
Dropout
L1、L2正则化是通过改动代价函数来实现的,而Dropout则是通过改动神经网络本身来实现的.
它是在训练网络时用的一种技巧(trike)
- 在训练開始时,我们随机地“删除”部分(一般为一半)的隐层单元, 视它们为不存在
- 保持输入输出层不变, 依照BP算法更新神经网络中的权值, 删除的单元不更新.
- 在第二次迭代中, 随机地'删除'部分隐层单元(注意是随机的!!!).
- 更新神经网络中的权值, 删除的单元不更新, 重复迭代直至训练结束.
- 随着训练的进行, 大部分网络都能够给出正确的分类结果, 少数的错误结果就不会对最终结果造成大的影响
结尾
关于误差方面的研究,目前概念比较多,还在持续更新...
- Log损失是通过概率计算的误差,所以在特定条件下Log损失与交叉熵的具有等价性
- Softmax函数会将结果映射到[0,1]间,并且总值是1,可以看做'概率'. 结合交叉熵作为代价函数, 就是Softmax损失函数.