此项目是自己学习搜索引擎过程中的一些心得,在使用go语言的时候,发现了悟空这个搜索引擎项目,结合此项目代码以及《信息检索导论》,自己对搜索引擎的原理是实现都有了一个初步的认识,然后结合工作中可能遇到的场景,做了一个简单的demo。写下这篇文章,可能比较啰嗦,希望帮助到需要的人。
基础知识
一个简单例子
假如有四个文档,分别代表四部电影的名字:
- The Shawshank Redemption
- Forrest Gump
- The Godfather
- The Dark Knight
如果我们想根据这四个文档建立信息检索,即输入查找词就可以找到包含此词的所有电影,最直观的实现方式是建立一个矩阵,每一行代表一个词,每一列代表一个文档,取值1/0代表该此是否在该文档中。如下:
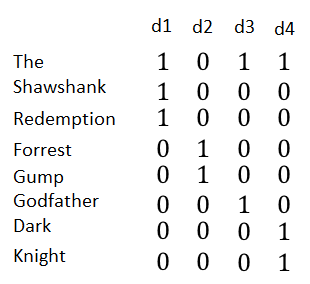
如果输入是Dark,只需要找到Dark对应的行,选出值为1对应的文档即可。当输入是多个单词的时候,例如:The Gump,我们可以分别找到The和Gump对应的行:1011和0100,如果是想做AND运算(既包括The也包括Gump的电影),1011和0100按位与操作返回0000,即没有满足查询的电影;如果是OR运算(包括The或者包括Gump的电影),1011和0100按位与操作返回1111,这四部电影都满足查询。
实际情况是我们需要检索的文档很多,一个中等规模的bbs网站发布的帖子可能也有好几百万,建立这么庞大的一个矩阵是不现实的,如果我们仔细观察这个矩阵,当数据量急剧增大的时候,这个矩阵是很稀疏的,也就是说某一个词在很多文档中不存在,对应的值为0,因此我们可以只记录每个词所在的文档id即可,如下:

查询的第一步还是找到每个查询词对应的文档列表,之后的AND或者OR操作只需要按照对应的文档id列表做过滤即可。实际代码中一般会保证此id列表有序递增,可以极大的加快过滤操作。上图中左边的每一个词叫做词项,整张表称作倒排索引。
实际搜索过程
如果要实现一个搜索功能,一般有如下几个过程
搜集要添加索引的文本,例如想要在知乎中搜索问题,就需要搜集所有问题的文本。
文本的预处理,把上述的收集的文本处理成为一个个词项。不同语言的预处理过程差异很大,以中文为例,首先要把搜集到的文本做分词处理,变为一个个词条,分词的质量对最后的搜索效果影响很大,如果切的粒度太大,一些短词搜索正确率就会很低;如果切的粒度太小,长句匹配效果会很差。针对分词后的词条,还需要正则化:例如滤除停用词(例如:
的把并且,一些几乎所有中文文档都包含的一些词,这些词对搜索结果没有实质性影响),去掉形容词后面的的字等。根据上一步的词项和文档建立倒排索引。实际使用的时候,倒排索引不仅仅只是文档的id,还会有其他的相关的信息:词项在文档中出现的次数、词项在文档中出现的位置、词项在文档中的域(以文章搜索举例,域可以代表标题、正文、作者、标签等)、文档元信息(以文章搜索举例,元信息可能是文章的编辑时间、浏览次数、评论个数等)等。因为搜索的需求各种各样,有了这些数据,实际使用的时候就可以把查询出来的结果按照需求排序。
查询,将查询的文本做分词、正则化的处理之后,在倒排索引中找到词项对应的文档列表,按照查询逻辑进行过滤操作之后可以得到一份文档列表,之后按照相关度、元数据等相关信息排序展示给用户。
相关度
文档和查询相关度是对搜索结果排序的一个重要指标,不同的相关度算法效果千差万别,针对同样一份搜索,百度和谷歌会把相同的帖子展示在不同的位置,极有可能就是因为相关度计算结果不一样而导致排序放在了不同的位置。
基础的相关度计算算法有:TF-IDF,BM25 等,其中BM25 词项权重计算公式广泛使用在多个文档集和多个搜索任务中并获得了成功。尤其是在TREC 评测会议上,BM25 的性能表现很好并被多个团队所使用。由于此算法比较复杂,我也是似懂非懂,只需要记住此算法需要词项在文档中的词频,可以用来计算查询和文档的相关度,计算出来的结果是一个浮点数,这样就可以将用户最需要知道的文档优先返回给用户。
搜索引擎代码
悟空搜索(项目地址: https://github.com/huichen/wukong)是一款小巧而又性能优异的搜索引擎,核心代码不到2000行,带来的缺点也很明显:支持的功能太少。因此这是一个非常适合深入学习搜索引擎的例子,作者不仅给出了详细的中文文档,还在代码中标注了大量的中文注释,阅读源码不是太难,在此结合悟空搜索代码和搜索原理,深入的讲解搜索具体的实现。
索引
索引的核心代码在core/index.go。
索引结构体
// 索引器
type Indexer struct {
// 从搜索键到文档列表的反向索引
// 加了读写锁以保证读写安全
tableLock struct {
sync.RWMutex
table map[string]*KeywordIndices
docsState map[uint64]int // nil: 表示无状态记录,0: 存在于索引中,1: 等待删除,2: 等待加入
}
addCacheLock struct {
sync.RWMutex
addCachePointer int
addCache types.DocumentsIndex
}
removeCacheLock struct {
sync.RWMutex
removeCachePointer int
removeCache types.DocumentsId
}
initOptions types.IndexerInitOptions
initialized bool
// 这实际上是总文档数的一个近似
numDocuments uint64
// 所有被索引文本的总关键词数
totalTokenLength float32
// 每个文档的关键词长度
docTokenLengths map[uint64]float32
}
// 反向索引表的一行,收集了一个搜索键出现的所有文档,按照DocId从小到大排序。
type KeywordIndices struct {
// 下面的切片是否为空,取决于初始化时IndexType的值
docIds []uint64 // 全部类型都有
frequencies []float32 // IndexType == FrequenciesIndex
locations [][]int // IndexType == LocationsIndex
}
tableLock中的table就是倒排索引,map中的key即是词项,value就是该词项所在的文档列表信息,keywordIndices包括三部分:文档id列表(保证docId有序)、该词项在文档中的频率列表、该词项在文档中的位置列表,当initOptions中的IndexType被设置为FrequenciesIndex时,倒排索引不会用到keywordIndices中的locations,这样可以减少内存的使用,但不可避免地失去了基于位置的排序功能。
由于频繁的更改索引会造成性能上的急剧下降,悟空在索引中加入了缓存功能。如果要新加一个文档至引擎,会将文档信息加入addCacheLock中的addCahe中,addCahe是一个数组,存放新加的文档信息。如果要删除一个文档,同样也是先将文档信息放入removeCacheLock中的removeCache中,removeCache也是一个数组,存放需要删除的文档信息。只有在对应缓存满了之后或者触发强制更新的时候,才会将缓存中的数据更新至倒排索引。
添加删除文档
添加新的文档至索引由函数AddDocumentToCache和AddDocuments实现,从索引中删除文档由函数RemoveDocumentToCache和RemoveDocuments实现。因为代码较长,就不贴在文章里面,感兴趣的同学可以结合代码和下面的讲解,更深入的了解实现方法。
删除文档
-
RemoveDocumentToCache首先检查索引是否已经存在docId,如果存在,将文档信息加入removeCache中,并将此docId的文档状态更新为1(待删除);如果索引中不存在但是在addCahe中,则只是把文档状态更新为1(待删除)。 - 如果
removeCache已满或者是外界强制更新,则会调用RemoveDocuments将removeCache中要删除的文档从索引中抹除。 -
RemoveDocuments会遍历整个索引,如果发现词项对应的文档信息出现在removeCache中,则抹去table和docState中相应的数据。
备注:removeCache和docIds均已按照文档id排好序,所以RemoveDocuments可以以较高的效率快速找到需要删除的数据。
添加文档
-
AddDocumentToCache首先会将需要添加的文档信息放入到addCahe中,如果缓存已满或者是强制更新,则会遍历addCache,如果索引中存在此文档,则把该文档状态置为1(待删除),否则置为2(新加)并将状态为1(待删除)的文档数据放在addCache列表前面,addCache列表后面都是需要直接更新的文档数据。 - 调用
RemoveDocumentToCache更新索引,如果更新成功,则把addCache中所有的数据调用AddDocuments添加至索引,否则只会把addCache中状态为2(新加)的文档调用AddDocuments添加至索引。 -
AddDocuments遍历每个文档的词项,更新对应词项的KeywordIndices数据,并保证KeywordIndices文档id有序。
备注:第二步相同的文档只会将最后一条添加的文档更新至索引,避免了缓存中频繁添加删除可能造成的问题。
搜索实现
从上面添加删除文档的操作可以发现,真正有效的数据是tableLock中的table和docState,其他的数据结构均是出于性能方面的妥协而添加的一些缓存。查询的函数Lookup也只是从这两个map中找到相关数据并进行排序。
合并搜索关键词和标签词,从
table中找到这些词对应的所有KeywordIndices数据从上面的
KeywordIndices数据中找出所有公共的文档,并根据文档词频和位置信息计算bm25和位置数据。
代码架构
悟空使用了很多异步的方式提高运行效率,针对我们开发高效的代码很有借鉴意义。项目文档里面有一份粗略的架构图,我根据engine源码,画出了一份详细的架构图。下面就以接口为粒度讲解具体的执行流程。
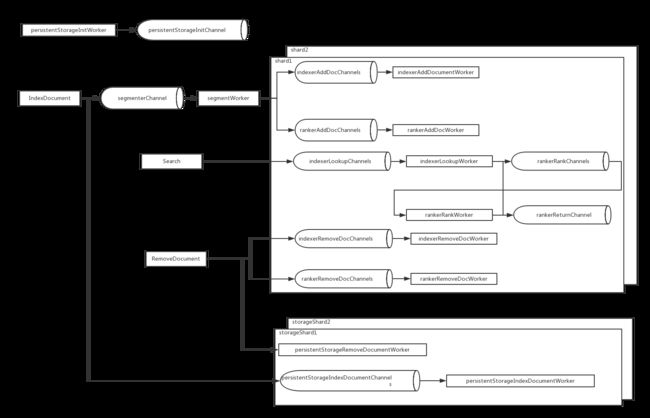
备注:圆柱体代表管道,矩形代表worker。
初始化引擎
这部分体现在图最上面的persistentStorageInitWorker和persistentStorageInitChannel,如果指定了索引的持久化数据库的信息,在引擎启动的时候,会异步调用persistentStorageInitWorker,这个routine会将持久化的索引数据(所有storage shard)加载到内存中,加载完毕后通过persistentStorageInitChannel通知主routine.
添加文档
IndexDocument是对外的添加文档的接口,当此接口执行的时候,先将需要分词的文本放入管道segmenterChannel,segmentWorker从segmenterChannel取出文本做分词处理,然后将分词的结果均匀的分配到各个shard对应的indexerAddDocChannels和rankerAddDocChannels,indexerAddDocumentWorker和rankerAddDocWorker分别从上面两个管道中取出数据更新索引数据和排序数据。
如果设置了持久化数据,IndexDocument还会将文档数据均匀的放入到各个storage shard的persistentStorageIndexDocumentChannels中,persistentStorageIndexDocumentWorker负责将管道中的文档数据持久化到文件中。
删除文档
RemoveDocument是对外的删除文档的接口,当接口执行的时候,找到文档所在的shard,然后将请求放入indexerRemoveDocChannels和rankerRemoveDocChannels,indexerRemoveDocWorker和rankerRemoveDocWorker分别监听上面两个管道,清除索引数据和排序数据。
查询
search是对外的搜索接口,它会针对所有的shard里的indexerLookupChannels发送请求数据,之后阻塞在监听rankerReturnChannel这一步,indexerLookupWorker会调用函数Lookup从倒排索引中找到制定的文档,如果不要求排序,直接将数据放入rankerReturnChannel,否则将数据交给rankerRankChannels,然后由rankerRankWorker排完序再放入rankerReturnChannel。当search发现所有数据都返回之后,再将各个shard的数据做一次排序,然后返回。
总结
由架构图可以很清晰地看出整个运行流程,同时知道此引擎无法分布式部署。如果需要做分布式部署,需要将每个shard作为一个独立的进程,而且上层有一个类似网管的进程做数据分发和汇总操作。
实例讲解
为了方便自己和大家的使用,我写了一个比较简单的例子,用orm的callback方式更新搜索引擎。
数据准备
文档数据是我从知乎的恋爱和婚姻话题爬取的精品回复,大概有1800左右回复,包括问题标题,回复正文,点赞个数以及问题标签,下载链接:https://github.com/LiuRoy/sakura/blob/master/spider/tables.sqlite,存储格式为sqlite,数据如下:

对如何爬取的同学可以参看代码https://github.com/LiuRoy/sakura/blob/master/spider/crawl.py,执行如下命令直接运行
cd sakura/spider/
pip install -r requirement
python scrawl.py
启动引擎
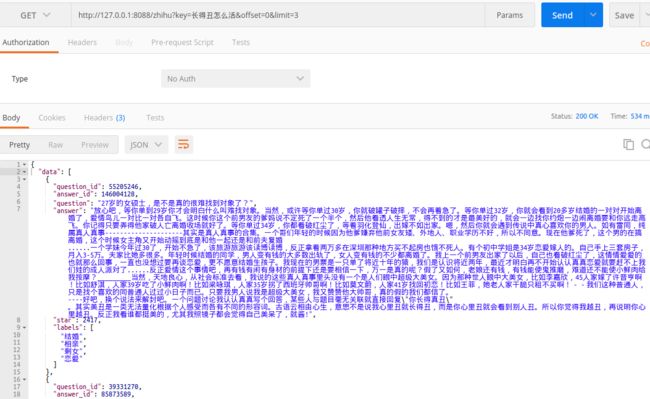
用上一步爬取的数据构建一个搜索引擎,代码参考server.go,在运行之前需要自己配置一下词典以及数据路径,悟空提供了一份分词词典和停用词列表,配置完成后运行go run server.go启动服务,然后通过浏览器就可以使用搜索服务了。
更新索引
一般搜索服务的数据都是动态变化的,如何在数据频繁变动的时候以最简单的方式更新索引呢?我能想到的方法有如下几种:
- 定时全量更新索引
- 定时查找数据库修改数据,将修改的数据更新至索引
- 读取数据库binlog,将数据变动实时更新到索引
- 每次数据库变更时,通过接口调用或者队列的方式通知搜索引擎修改索引
我采用了第四种方式做了一个demo,代码参考sender.go,为了避免代码耦合,通过orm的callback方式将修改的数据通过zeromq消息队列发送给搜索服务,搜索服务有一个goroutine来消费数据并更改索引,当执行go run sender.go后,新建的一条数据就可以马上被索引到。
