ICCV 2023 | UniFormerV2开源,K400首次90%准确率 基于ViT的高效视频识别,8数据集SOTA...
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
以下内容来源于知乎@Sakura.D
简单介绍一下我们最近放出来的工作UniFormerV2,方法受UniFormer的启发,设计了通用高效的时序建模模块,可以无缝插入到各种开源预训练图像ViT中,显著增强模型对时序信息的处理能力。为进一步提升主流benchmark上的性能,我们将K400/K600/K700进行数据清洗,得到更精简的K710数据集(0.66M训练视频),在该数据集上训练,只需简单微调即可得到超过1%的性能提升。基于CLIP提供的视觉编码器,我们的UniFormerV2最终在8个主流benchmark都取得了SOTA结果,包括场景相关数据集(短时的K400/K600/K700和Moments in Time,以及长时的ActivityNet和HACS),和时序相关数据集(Something-SomethingV1&V2)。仅单个模型(354M参数),我们最终在K400上首次取得了90.0%的准确率。

代码、模型和相应的训练配置均已开源,应该目前开源模型里,在这8个流行benchmark上性能最强的。欢迎小伙伴们试用,有用的话可以随身点个star~
Motivation
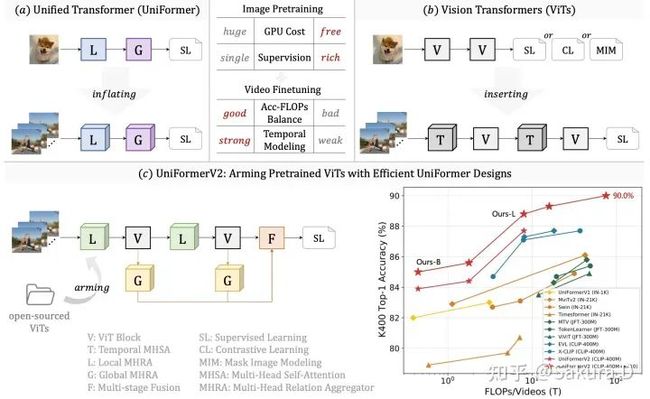
去年在做UniFormer[1]时,我们时常觉得实验的周期太长了。由于UniFormer是全新的框架,每次调整结构,我们都需要先经过一轮ImageNet图像预训练,之后将模型展开后,在Kinetics等视频数据集进行二次微调。根据结果反馈,再进行结构的改进。
更简洁的训练方式是直接在视频数据上从头预训练(如SlowFast[2]和MViT[3]),但这种方式只适合于Google/Meta等大的研究机构,并且直接在视频数据预训练,但训练开销也更加大。
尽管这能更仔细地设计对视频任务友好的高效框架,在相同FLOPs的确远超同期基于ViT的一些列工作(如TimeSformer[4]、ViViT[5]和Mformer[6]),但二次训练的代价高昂,也限制了我们去探索更大规模的模型。我们当时最大的模型为UniFormer-B(50M参数),输入32帧,需要使用32张V100在Kinetics上训练约2周。那么有没有更好的结构设计与训练方案,一来能保证模型的性能足够好,另外又能节省训练开销,让一般的实验室算力,也能进行2022年的视频框架探索呢?
回想起2019-2021年,彼时ViT还未提出,学术界设计了一系列基于ResNet的轻量视频模型,如TSM[7]和STM[8]等。这些方法设计即插即用的时序模块,在ResNet50和ResNet101进行了一系列充分的验证。由于ResNet网络较小,这些方法一直未能在视频数据集上取得突破性的性能提升,此时在Kinetics系列上最好的方法仍是Meta使用大数据集预训练的大模型CSN[9]和SlowFast等。
2021年,ViT的兴起也促使了TimeSformer和ViViT等工作的出现,这些工作进一步拓展实际了时间注意力,充分了利用开源的ImageNet-21K预训练ViT,一度刷新Kinetics系列的性能上限。然而注意力机制的开销仍不是一般实验室可以承受的,此时的模型的计算量已经以TFLOPs为计量单位。并且基于图像预训练ViT的方法,难以真正地提升时序建模能力,在Something-Something等强时序相关数据集上效果较差(甚至不如基于ResNet的轻量模型)。这也促使我们去探究卷积和注意力的特点,设计高效的视频框架UniFormer。
时间来到2022年,更多样预训练的ViT模型开源,如有监督的Deit III[10]、对比学习的CLIP[11]和DINO[12],以及掩码学习的MAE[13]和BeiT[14],规模也日益增长。我们完全可以充分利用上这些开源的预训练图像大模型,设计轻量的时序建模模块,以较小的训练代价迁移到视频任务中!
UniFormerV2也便是在这种想法下产生,我们沿用了UniFormerV1中的结构设计思想,设计了高效的局部与全局时空学习模块,可无缝插入到强预训练的图像ViT中,实现强大的视频建模。我们在一系列预训练以及不同规模的模型都进行了适配性实验,在流行的数据集上都能取得出众的性能。如上图右下角所示,我们的模型在K400上取得了最优的准确率和计算量权衡,并首次达到90.0%的top-1准确率。
Method

整体框架
模型的整体框架如上图所示,主要包含四个主要改进,后面消融实验也会进行具体介绍:
Temporal Downsampling: 在Patch Embedding层进行时序下采样,该操作将Patch Embedding拓展为3D卷积,在时序上下采样,变相在相同计算量的前提下,可输入两倍的帧数,可明显提升模型对强时序相关行为的判别能力。
Local UniBlock: 在保留原始ViT对空间的全局建模的前提下,我们额外引入局部时间建模,该模块遵循UniFormer局部模块的设计,但depth-wise卷积仅在时间维度操作。在较小计算量的前提下提升骨架网络的时序建模能力。
Global UniBlock: 对于视频任务而言,对全局时空token学习long-term dependencies尤其关键,为压缩全局模块的计算量,我们引入交叉注意力,使用单个可学的token作为query,不同层的输出token作为keys和values,设计。并且我们引入UniFormer中的DPE,增强token的时空位置信息。这样,每个全局模块会将对应层的时空信息压缩成单个informative token。
Multi-stage Fusion: 为了将不同层的informative token融合,得到更复杂的表征,我们探索了包括串行、并行、层次化等几种融合方式,并最终采用最简单的串行设计。即前面层出来的informative token会作为下一层的query token,不断迭代融合多层信息。最后,这些来自多层融合的时空表征会与骨架网络的输入表征进行加权融合,得到最终送入分类层的判别表征。

实现细节
对于结构,经过消融实验我们发现:
对于Kinetics系列等场景相关视频,也即单图即可较好判断行为的前提下,模型只需要在深层额外插入Global UniBlock,便可以满足这一大类数据的需求。
对于Something-Something这类强时序相关视频,对模型的时序建模能力要求极高,除了在Patch Embedding引入temporal downsampling之外,我们还在每层插入Local UniBlock,在网络的中层和深层插入Global UniBlock,方能实现强大的时序判别。
但饶是如此简单的结构,在训练时需要一些超参的设计保证模型正常收敛,我们在论文正文和附录的实现细节中有所说明:
模型初始化:为了保证模型初始训练与原图像模型输出一致,我们对插入的部分模块进行了零初始化,包括Local UniBlock输出的linear层、可学query、Global UniBlock中FFN的输出linear层,以及加权注意力的可学权重。
训练超参数:对强预训练模型,在视频任务上进行full-tuning迁移,需要使用较小的学习率,并且在数据规模较小是,需要引入额外的正则化如droppath等,具体超参可看原文附录Table11。

Kinetics-710
为了进一步增强图像预训练模型的迁移性能,目前SOTA的工作MTV[15]引入了大规模视频文本数据WTS-60M,进行二次多模态预训练。考虑到这种方式的训练成本(并且收集数据也太花钱了),我们产生只利用开源数据进行有监督预训练。我们尝试了多种数据集联合训练的方式,如COVER[16]中的多源数据集联合训练,但在我们的实验中K400+SSV2+MiT的设置难以work。于是我们干脆将同源数据联合,也即K400、K600和K700,其中主要涉及两个重要步骤:
数据清洗:由于不同数据集之间,训练集和训练集,训练集和测试集,以及测试集和测试集之前存在重叠,包含信息泄露,我们首先根据YouTube ID对重叠视频进行删除,得到0.66M视频。
标签清洗:我们根据YouTube ID和3个数据集的类别名,进行标签清洗,最终保留了710类标签,论文附录的Table20提供了标签map。
我们将这个精简的数据集称为Kinetics-710(K710),对于二次有监督预训练,我们直接使用单个数据集上训练超参,模型仅输入8帧。预训练完成后,无论输入多少帧(8/16/32/64),该模型都仅需要在单个数据集K400/K600/K700上训练5个epoch,即可实现超过1%的性能提升,同时极大地减小了训练开销。需要注意的是,在K710预训练模型微调时,我们会对分类层权重进行映射,即根据标签map保留400/600/700类对应权重。
实验
Kinetics

除了计算量和准确率以外,我们额外提供了几个指标,包括图像预训练模型是否ready(即不需要额外预训练),是否包含二次预训练,最终需要在单个数据集上训练多少epoch。综合考虑下,我们的UniFormerV2不仅在训练上高效,测试性能同样超越了以往的SOTA模型。
Moments in Time
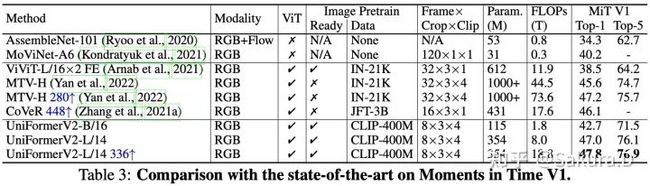
对MiT这种类内类间差异更大的行为,UniFormerV2同样取得了最佳的性能,充分验证了我们方案的鲁棒性。
Something-Something

在Something-SomethingV2这种强时序相关数据集上,UniFormerV2远好于以往基于ViT设计的一系列方法,值得注意的是,这些方法往往在Kinetics上表现优秀,这也说明了他们实质上并没有真正的对时间进行建模。与以往的SOTA方法相比,受助于强大图像预训练的优势,UniFormerV2只需要在单个视频数据上训练少量epoch,而以往方法往往需要先在K400上预训练,或者进行数千个epoch的自监督训练,才能达到最好的性能。

在Something-SomethingV1数据集上,UniFormerV2刷新了最先进的性能。如右表所示,我们也尝试过额外引入K400预训练,但fine-tuning效果反倒更差。可能的原因是,我们使用的模型经过400M图文数据预训练,而K400只包含0.24M训练视频,并且视频是场景相关的(即与单张图片效果类似),并且K400与Sth-Sth存在域差异,额外的K400训练可能会破坏CLIP预训练的特征分布。
ActivityNet和HACS

在长时行为数据集ActivityNet和HACS上,UniFormerV2以显著的优势高于先前的SOTA方法。
不同预训练ViT

我们对有监督预训练、对比学习、掩码学习的预训练ViT都进行了适配验证,可以看到即便使用ImageNet-1K预训练的ViT,我们的方法都能优于TimeSformer,尤其是在Sth-Sth这类强时序相关数据集上。另外一个有趣的观察时,不同的预训练方式并不能拉开太大的差距,但预训练的数据规模越大,在视频任务上的提升也越明显。
消融实验

我们在K400和Sth-SthV2上进行了广泛的消融实验,充分验证了我们方法中提出的各个模块的有效性,以及K710二次预训练的高效性,感兴趣的小伙伴可以到正文看看进一步的分析。
可视化
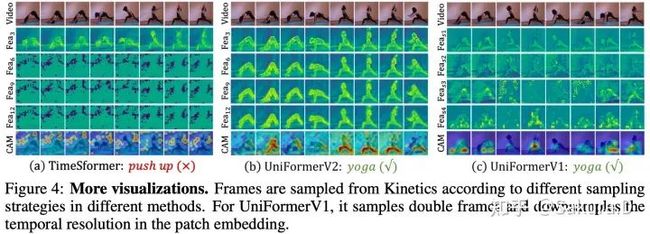
可视化特征可以发现,UniFormerV2能更好地在浅层和深层保留 特征的细节,并关注前景区域。
结束语
在UniFormerV2中,我们探索设计了更高效更通用的时空建模模块,可以无缝适配图像预训练ViT,显著增强对视频任务的处理效果。开源模型和K710的加持,让整个模型的训练谱系的训练十分高效。仅利用开源的CLIP预训练和开源的有监督数据,UniFormerV2可在8个流行benchmark上超越以往SOTA。
目前UniFormerV2的相关代码、模型和配置都已经开源,在这8个数据集上也是目前开源模型最强的。希望能为社区做出一点贡献,欢迎各位试用,帮忙找bug!
Paper:
https://arxiv.org/abs/2211.09552
Code:
https://github.com/OpenGVLab/UniFormerV2github.com/OpenGVLab/UniFormerV2
参考
^UniFormer https://arxiv.org/abs/2201.04676
^SlowFast https://arxiv.org/abs/1812.03982
^MViT https://arxiv.org/abs/2104.11227
^TimeSformer https://arxiv.org/abs/2102.05095
^ViViT https://arxiv.org/abs/2103.15691
^Mformer https://arxiv.org/abs/2106.05392
^TSM https://arxiv.org/abs/1811.08383
^STM https://arxiv.org/abs/1908.02486
^CSN https://arxiv.org/abs/1904.02811
^DeiT III https://arxiv.org/abs/2204.07118
^CLIP https://openai.com/blog/clip/
^DINO https://arxiv.org/abs/2104.14294
^MAE https://arxiv.org/abs/2111.06377
^BeiT https://arxiv.org/abs/2106.08254
^MTV https://arxiv.org/abs/2201.04288
^COVER https://arxiv.org/abs/2112.07175
提醒
点击“阅读原文”跳转到02:22:24
可以查看回放哦!
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1100多位海内外讲者,举办了逾550场活动,超600万人次观看。

我知道你
在看
哦
~
![]()
点击 阅读原文 观看回放!