施工场景下多目标跟踪
多目标跟踪乃是违规行为识别的前提与基础,只有在视频流中抽取出每一个目标的数据后才能定性去分析该目标的行为,而在复杂场景下的多目标跟踪又是一个极具挑战性的问题。总的来说,多目标跟踪这个领域得益于近来目标检测的研究成果进而取得了快速发展。融合目标检测做跟踪,即tracking-by-detection,是一个非常流行的方法,即在每一帧中使用目标检测器得出检测目标,然后再匹配关联不同帧中的目标得到目标的跟踪轨迹。该处理框架一方面利用高置信度的检测结果(YOLO、SSD等)来防止视频跟踪中的长时跟踪漂移问题,另一方面利用帧间上下文关系做预测(Kalmann滤波、LSTM等)还能处理遮挡等带来的检测误差。总之,检测与预测能相互取长补短,形成冗余的候选框;而目前的各种研究成果则在于如何把预测与检测进行去冗余处理、进行最佳的匹配,形成新的轨迹。其最大的挑战则在于处理目标相似和遭遇检测器不可靠的检测的情况:第一种挑战,目标具有相似的外观特征将会带来错误的关联匹配,解决该类挑战则在于提取各种辨别性的特征如形状、外观等;第二种挑战,检测器输出不可靠的检测,比如目标行人的姿态变换,遮挡等可引起漏检误检等,解决该类挑战则运用概率图模型等融合所有视频帧的检测结果求解一个全局的优化问题来匹配目标的跟踪轨迹,也可只利用之前的帧数据将其转化为更通用更实用的在线处理问题。由于要实际应用于施工场景中,实时性讲师一个重要的考量以及挑战。
1. 目标检测器
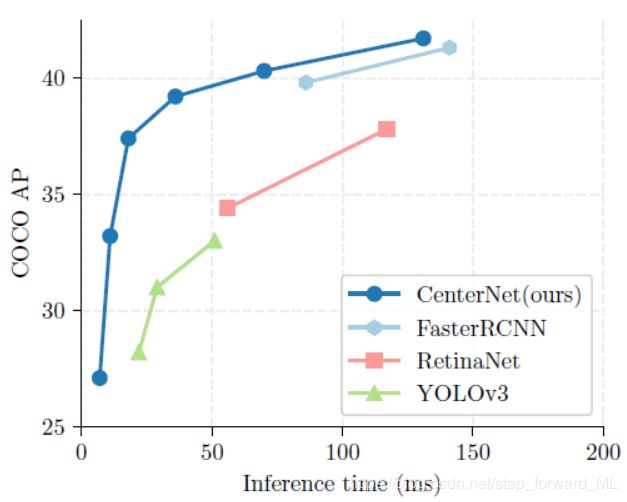
基于深度卷积网络的目标检测器近年来涌现出了大量研究成果,其发展经历了region-based、anchor-based和anchor-free的历程。Anchor-free的检测方法目前达到了准确率和效率的最佳平衡。这里介绍一种最新出的检测器,CenterNet(Xingyi Zhou, Dequan Wang, Philipp Krähenbühl,Objects as Points),其检测速度能匹配YOLOv3,准确率能匹配two-stage的检测器,如下图所示:
CenterNet,顾名思义就是将目标框用中心来表示,也即网络最终的输出肯定是一个heat map,其中的一系列峰值点就是潜在目标的中心点。考虑一个3通道的图像 I ∈ R W × H × 3 I \in R^{W\times H\times 3} I∈RW×H×3,经过一个全卷积的encode-decode网络,最终输出的feature map尺寸为 ( W / R , H / R , C ) (W/R,H/R,C) (W/R,H/R,C), R R R为output stride,C为类别个数。解释为根据输出的特征图,我们可以在某一个通道上找出峰值点,即该点为潜在的目标框的中心,类别为该通道的索引。文中测试的网络用了3种网络:stacked hourglass network, upconvolutional residual networks (ResNet), 和 deep layer aggregation (DLA)。那么在训练时如何构造ground truth呢?假设输入图像包含一个类别为3的检测框(中心为 x , y x,y x,y),则我们希望网络的输出特征图为除了索引为3的通道中里检测框中心对应点( └ x / R ┐ , └ y / R ┐ \llcorner x/R \urcorner,\llcorner y/R \urcorner └x/R┐,└y/R┐, └ ┐ \llcorner \urcorner └┐为取整操作) 为1外,其它位置及其它通道中位置均为0。当然,这是最理想情况,文中对ground truth取了一个自定义高斯窗的高斯核操作,即ground truth取值更为平滑。注意,当两个检测框属于同一类别且很靠近时,在构造该ground truth时,两个重叠的高斯取最大值。这里的损失采用了逐像素的focal loss,具体可参考论文。
上述中的检测框中心对应缩小后的输出特征图中进行了取整操作,那么如果将取整后的坐标再原封不动的影射回原始图中肯定会与真正的检测框中心出现偏差。因此,文中针对这种偏差通过网络输出进行补偿。即网络的另一个输出feature map尺寸为 ( W / R , H / R , 2 ) (W/R,H/R,2) (W/R,H/R,2),输出的每个点包含两个偏差补偿值( δ x , δ y \delta_x,\delta_y δx,δy)。即输出特征图中某一个峰值点的坐标在影射为原图前,先加上该点的偏差补偿值,再往回映射,即能保证不会出现偏差。那么该偏差特征图的ground truth输出为检测框中心映射到输出图尺寸时的偏差,即取整后遗留的小数点。因此,这里的损失采用简单的绝对值损失,而只有检测框中心点参与计算损失,其它点不参与计算损失(其它点不是检测框,不存在中心点映射)。
通过上述,一个完整的检测框除了中心,还得包含宽和高。而前面的步骤我们只能计算出检测框的中心。所以网络的第三个输出feature map尺寸为 ( W / R , H / R , 2 ) (W/R,H/R,2) (W/R,H/R,2),输出的每个点包含宽和高两个值。那么该宽高特征图的ground truth输出为检测框的宽和高。同样,这里的损失采用简单的绝对值损失,而只有检测框中心点参与计算损失,其它点不参与计算损失(其它点不是检测框,没有宽高值)。
综上,最终的输出特征图尺寸为 ( W / R , H / R , C + 2 + 2 ) (W/R,H/R,C+2+2) (W/R,H/R,C+2+2),且共享一个backbone网络。前C个通道的输出值确定待检测框的中心和类别,中间2个通道的值进行中心矫正,后2个通道的值确定宽和高。注意,在确定待检测框的中心时,简单的准则即当一个点的响应值高于其8领域时,且该响应值为特征图 ( W / R , H / R , C ) (W/R,H/R,C) (W/R,H/R,C)中top100,则该点即为峰值点即为一个潜在的输出检测框。
最终在COCO 数据集上, with 28:1% AP at 142 FPS, 37:4% AP at 52 FPS, and 45:1% AP with multi-scale testing at 1.4 FPS。本人在480P的视频流中进行目标跟踪时,前期目标检测使用YOLOv3时,跟踪帧率为8帧;而选用CenterNet时跟踪帧率为6帧。
2. 跟踪器
跟踪器部分根据历史数据预测当前帧位置,并结合检测器在当前帧的检测框位置进行进一步筛选和匹配形成新的跟踪轨迹。前面提到了检测,下面详细介绍预测。在视频流中,利用历史帧信息预测目标在下一帧中的位置,目前MOT这块采用kalman滤波、LSTM等,甚至将单目标跟踪融入预测部分。这里介绍一种采用卷积神经网络进行预测的方法。参考论文Frame-wise Motion and Appearance for Real-time Multiple Object Tracking。所提方法的网络结构如图,包含位置预测网络(Frame-wise Motion Fields (FMF))和深度特征提取网络(Frame-wise Re-ID Features (FAF)):
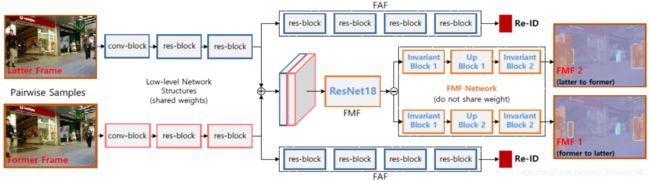
FMF:网络如图输入为两帧图像(包含检测器得到的检测框),输出为对应检测框的位置偏移。注意,这个位置偏移是一个相对值,比如第一帧相对于第二帧以及第二帧相对于第一帧。这里网络预测了目标的双向motion向量,主要是为了让motion向量更加鲁棒。两方面考虑: 1)前后两帧的表观和上下文信息可能差异较大,拆开考虑更鲁棒;2)可以解决部分遮挡问题,前后分别预测。因此,FMF输出的是一个4通道的特征图,分别代表第一帧相对于第二帧在横向和纵向的偏移以及第二帧相对于第一帧在横向和纵向的偏移。在训练该网络时,ground truth的构造只针对匹配的目标检测框集合的中心点,计算相应的4个偏移;训练时则采用简单的F范数,同样只针对匹配的目标框集合计算损失。下图为可视化的网络输出偏移
FAF:特征提取网络,该部分最主要的功能在于提取目标框的深度特征进行更好的相互匹配,而避免id错误匹配。一般而言,大多数研究采用独立的特征提取网络训练于大型的行人重识别数据集,而该论文则与预测共享网络而降低计算复杂度。对于输入的两帧图像,如何计算其中检测框对的相似性呢?对两帧中的对应检测框,我们希望相似性为1;而不同的检测目标相似性为0。那么这部分网络实质为训练一个二分类器。正样本为 对应检测框之间的特征拼接;负样本为 不同物体的检测框间的特征拼接。注意,正负样本的比例为1:4。损失函数则采用Binary Cross-Entropy (BCE) loss。在推理阶段:根据输入的两帧图像和对应的检测框,我们可以计算两帧间的任意框对间的相似性。根据FAF网络和crop、roi pooling,提取当前检测框的特征;拼接任意两个检测框的特征;喂如分类器中得到相似性的量化值。
预测与检测间的匹配:检测根据检测器获取;而预测根据FMF得到目标在下一帧中的位置(和下一帧的检测在上一帧中的位置)。那么如何进行匹配呢?如下图:

简单来说,根据每一个预测(track)去找到最佳匹配的检测(detection),最佳匹配以IOU和相似度做判据。以某一个预测为例:首先,根据该预测与所有detections计算IOU,再进行排序,并筛选出大于预设阈值的detections;然后,计算该预测与筛选出的detections根据FAF提取特征并计算相似度,选取最大相似度的detection与该预测进行匹配。对于没有进行匹配的预测,则进入第二步。由于FMF是双向的,则可以预测下一帧在上一帧的位置,所以匹配按照第一步进行相同的匹配。对于还没匹配的预测,则进入第三步,放松匹配要求,即同样按照第一步步骤,只根据特征相似度进行匹配,只要大于预设阈值即匹配成功。
将检测器与跟踪器结合,即实现了多目标跟踪。最后实验,在titan xp上测试对于480p的视频处理帧率为6帧,跟踪效果还是不错,但是跟丢以及id switch还是存在很大问题。