编译器设计-符号表-中间代码生成
Compiler Design - Symbol Table
Compiler - Intermediate Code Generation
一.Compiler Design - Symbol Table
符号表是编译器为存储变量名、函数名、对象、类、接口等各种实体的出现情况而创建和维护的一种重要的数据结构。符号表既可用于编译器的分析部分,也可用于编译器的综合部分。 符号表可用于以下目的,具体取决于所使用的语言:
将所有实体的名称以结构化形式存储在一个位置。
以验证是否已声明变量。
要实现类型检查,请验证源代码中的赋值和表达式在语义上是否正确。
确定名称的作用域(作用域解析)。
符号表只是一个可以是线性表或哈希表的表。它以以下格式为每个名称维护一个条目:
例如,如果符号表必须存储有关以下变量声明的信息:
static int interest;
然后它应该存储条目,例如:
, int, static> attribute子句包含与名称相关的条目。
实施Implementation
如果编译器要处理少量数据,那么符号表可以实现为无序列表,这很容易编码,但它只适用于小表。符号表可以通过以下方式之一实现:
线性(排序或未排序)列表
二叉搜索树
哈希表
其中,符号表主要实现为哈希表,其中源代码符号本身被视为哈希函数的键,返回值是关于符号的信息。
操作Operations
符号表(线性或哈希)应提供以下操作。
插入()
此操作在分析阶段使用得更频繁,即编译器的前半部分,其中标识了标记并将名称存储在表中。此操作用于在符号表中添加有关源代码中出现的唯一名称的信息。存储名称的格式或结构取决于手头的编译器。
源代码中符号的属性是与该符号关联的信息。此信息包含有关符号的值、状态、范围和类型。函数的作用是:将符号及其属性作为参数,并将信息存储在符号表中。
For example:
int a;
应该由编译器处理为should be processed by the compiler as:
insert(a, int);
查找()
lookup()操作用于搜索符号表中的名称以确定:
如果符号存在于表中。
如果在使用前声明。
如果在作用域中使用了该名称。
如果符号已初始化。
如果符号声明了多次。
lookup(symbol)
lookup()函数的格式因编程语言而异。基本格式应符合以下要求:
如果符号表中不存在该符号,则此方法返回0(零)。如果符号存在于符号表中,则返回存储在表中的其属性。
范围管理
编译器维护两种类型的符号表:一种全局符号表,它可以被所有过程访问,另一种是为程序中的每个作用域创建的作用域符号表。
为了确定名称的范围,符号表按层次结构排列,如下例所示:
. . .
int value=10;
void pro_one()
{
int one_1;
int one_2;
{ \
int one_3; |_ inner scope 1
int one_4; |
} /
int one_5;
{ \
int one_6; |_ inner scope 2
int one_7; |
} /
}
void pro_two()
{
int two_1;
int two_2;
{ \
int two_3; |_ inner scope 3
int two_4; |
} /
int two_5;
}
. . .
上述程序可以用符号表的层次结构表示:
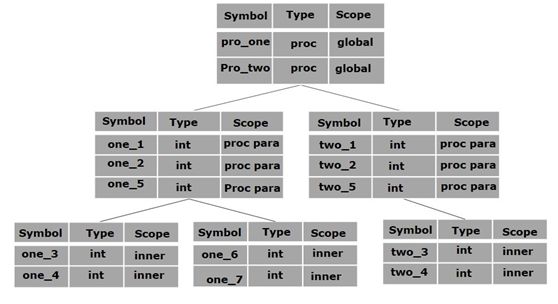
全局符号表包含一个全局变量(int值)的名称和两个过程名称,这些名称应该对上面显示的所有子节点都可用。pro_one symbol表(及其所有子表)中提到的名称不适用于pro_two symbol及其子表。
此符号表数据结构层次结构存储在语义分析器中,当需要在符号表中搜索名称时,将使用以下算法进行搜索:
首先在当前范围内搜索一个符号,即当前符号表。
如果找到名称,则搜索完成,否则将在父符号表中搜索,直到,
找到该名称或已在全局符号表中搜索该名称。
二.Compiler - Intermediate Code Generation
一个源代码可以直接翻译成它的目标机器代码,那么我们为什么要把源代码翻译成一个中间代码,然后再翻译成它的目标代码呢?让我们看看需要中间代码的原因。
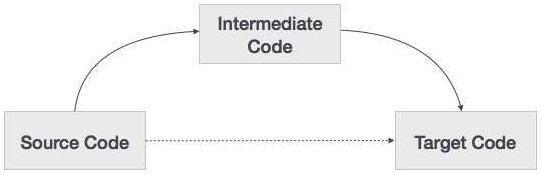
如果编译器在没有生成中间代码的选项的情况下将源语言转换为目标机器语言,那么对于每台新机器,都需要一个完整的本机编译器。
中间代码通过保持所有编译器的分析部分相同,消除了对每台唯一计算机使用新的完整编译器的需要。
编译器的第二部分,synthesis,是根据目标机器而改变的。
通过在中间代码上应用代码优化技术,可以更容易地应用源代码修改来提高代码性能。
中间表示法Intermediate Representation
中间代码可以用多种方式表示,它们有自己的优点。
高级别的IR-高级别的中间代码表示非常接近源语言本身。它们可以很容易地从源代码生成,我们可以很容易地应用代码修改来提高性能。但对于目标机优化,则不太可取。
低级别的IR-这是一个接近目标机器,这使得它适合于寄存器和内存分配,指令集选择等。这是一个很好的机器相关的优化。
中间代码可以是特定于语言的(例如,Java的字节码)或独立于语言的(三地址码)。
三地址码 Three-Address Code
中间代码生成器以带注释的语法树的形式接收来自其前一阶段语义分析器的输入。然后,可以将该语法树转换为线性表示法,例如后缀表示法。中间代码往往是与机器无关的代码。因此,代码生成器假设有无限数量的内存存储(寄存器)来生成代码。
For example:
a = b + c * d;
中间代码生成器将尝试将此表达式划分为子表达式,然后生成相应的代码。
r1 = c * d;
r2 = b + r1;
a = r2
r用作目标程序中的寄存器。
一个三地址码最多有三个地址位置来计算表达式。三地址码可以用两种形式表示:四位和三位。
四倍Quadruples
四位数表示中的每条指令分为四个字段:operator、arg1、arg2和result。以上示例以四位数格式表示如下:

三元组
三元组表示中的每条指令都有三个字段:op、arg1和arg2。各子表达式的结果由表达式的位置表示。三元组表示与DAG和语法树的相似性。它们在表示表达式时等价于DAG。

三元组在优化时面临代码不可移动的问题,因为结果是位置的,更改表达式的顺序或位置可能会导致问题。
间接三元组
此表示是对三元组表示的增强。它使用指针而不是位置来存储结果。这使优化器能够自由地重新定位子表达式以生成优化的代码。
声明 Declarations
变量或过程在使用之前必须声明。声明涉及内存空间的分配以及符号表中类型和名称的输入。一个程序的编码和设计可以考虑到目标机器的结构,但可能并不总是能够准确地将源代码转换成目标语言。
将整个程序作为过程和子过程的集合,就可以声明过程的所有本地名称。内存分配是以连续的方式完成的,名称是按照在程序中声明的顺序分配给内存的。我们使用offset变量并将其设置为零{offset=0},表示基址。
源程序设计语言和目标机器体系结构的名称存储方式可能不同,因此使用相对寻址。当从内存位置0{offset=0}开始分配第一个名称时,后面声明的下一个名称应该在第一个名称旁边分配内存。
例子:
我们以C语言为例,其中一个整数变量被分配2字节的内存,一个浮点变量被分配4字节的内存。
int a;
float b;
Allocation process:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}
要在符号表中输入此详细信息,可以使用过程enter。该方法可以具有以下结构:
enter(name, type, offset)
此过程应在符号表中为变量名创建一个条目,将其类型设置为类型,并在其数据区域中设置相对地址偏移量。