Linux下从0开始GPU环境搭建与启动测试
引言
本篇梳理了整个Linux下安装深度学习环境需要用到的东西,另外也介绍了一些个人使用的经验,也算是之后如果忘了能回头翻阅的笔记。
算法环境
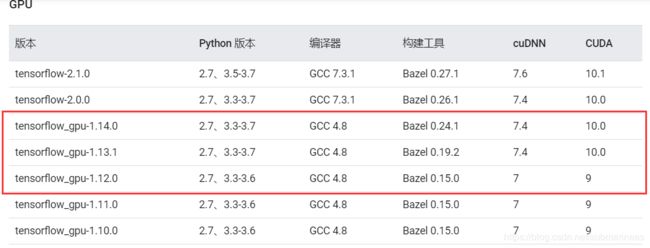
- tensorflow-gpu==1.14.0
- torch==1.3.1
- torchvision==0.4.2
cuda与cudnn对应版本关系:
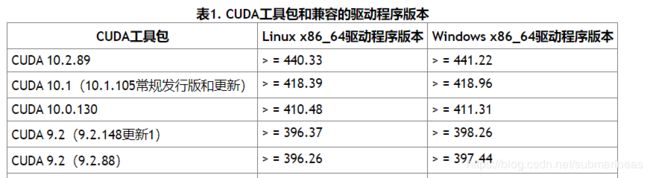
上两图链接如下:
NVIDIA CUDA工具包发行说明
从源代码构建tensorflow
框架搭建
安装顺序
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
cuDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。如果你要用GPU训练模型,cuDNN不是必须的,但是一般会采用这个加速库。
只有在同时完成上面两个的安装后,tensorflow-gpu才能成功编译并效率提高。首先确保电脑的显卡驱动安装正确,如果是重装过系统再来安装相应的环境,这里有两种安装方式,一种是centos和ubuntu都通用的格式,还有一种就是TensorFlow的官网推荐的ubuntu安装,本篇侧重点在通用格式,即顺序为先装显卡驱动,再安装cuda、cudnn,最后用requirement.txt文件pip install或者conda install一下,pip和conda安装也有区别,后者更利于做版本管理,但具体的相应优缺点在后面一一介绍,那么话不多说就开始吧。
首先安装的显卡驱动,直接去英伟达官网找到对应的版本,按照它的步骤基本没有问题,最后会提示需要reboot Linux服务器,重启后输入nvidia-smi测试,如果提示找不到命令找不到那么就安装失败:
![]()
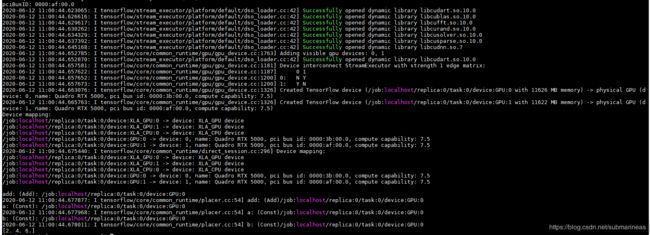
成功的话可以看我下面的在程序启动后的图,提示GPU在使用,并且显示出当前系统显卡型号,还有状态就算驱动匹配成功。那么按照上图中以cuda 10.0和cudnn 7.4装1.14版本的tensorflow-gpu。
cuda安装
首先进入如下下载链接:
https://developer.nvidia.com/cuda-toolkit-archive
cuda 10.2开始,能直接通过wget拿到网络源,但10.2之前的版本还需要手动安装到本地,再上传至服务器,这一步的速度按照网速来判定,2.5G的安装包如果网络好可能比wget还要快。然后按照官网的步骤:
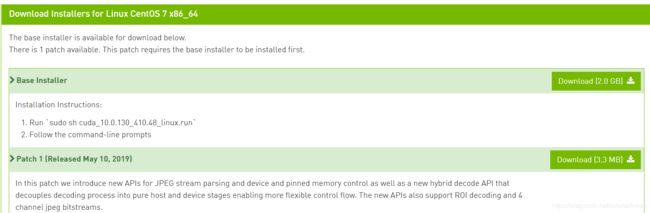
运行后就会看到大段的协议,需要按住键盘下键直到弹出如下界面:
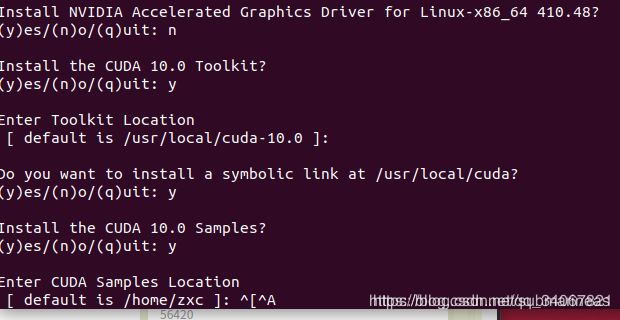
上图取自Ubuntu 18.10 下安装CUDA10/CUDA10.1,它是ubuntu下载,而我是centos 7,但殊途同归,上面同样是4个选项,我记得我当时除了 install the cuda 10.0 toolkit和install a symbolic link为Y,其它全部为n,上图第一个n是表示要不要安装cuda的同时顺便安装显卡驱动,但这一步它并没有检索当前系统的驱动,如果安装后,会将原先已经适配的驱动替换,那么之后测试会发生的错误:Failed to initialize NVML: Driver/library version mismatch。第二个选项没有争议,第三个我记得第一次装的时候,选的n,但它还是有安装到/local/cuda下,第四个只是一个example,cuda官网上是用它来测试安装成功与否,但作用不大,测试方法很多种。
安装完后后加入环境变量:
vim ~/.bashrc
添加到最后
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
保存退出
source ~/.bashrc
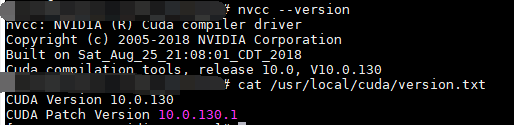
然后就可以进行测试,如下表示安装成功:
cudnn安装
cudnn的安装同样可以参考NVIDIA官网:https://docs.nvidia.com/deeplearning/sdk/cudnn-install/index.html
然后cudnn资源在:cuDNN Archive
它里面推荐的是ubuntu按照deb文件安装,centos按照rpm安装,但两种服务器,这两种安装我都尝试了下,光是从拉到本地就已经速度很慢了,按照NVIDIA的安装过程,Linux下它只写了ubuntu的安装方式,需要安装三个包,但我在实际安装过程发现第二个包cuDNN Developer Library下载奇慢,不如直接下源码包,并且ubuntu下完,centos还可以拿着接着通用:
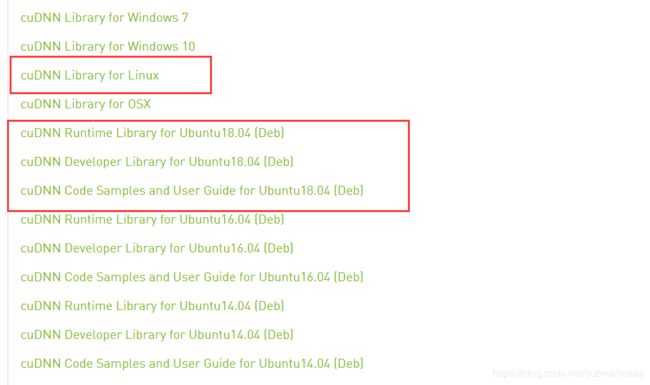
下载完后的命令为:
tar -zxvf cudnn-10.0-linux-x64-v7.4.2.tgz
sudo cp cuda/include/cudnn.h /usr/local/cuda/include/ #解压后的文件夹名为cuda
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h #增加所有用户对文件的可执行权限
sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
然后进行测试如下,输入:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2

那么到这里,cudnn和cuda就全部安装成功,并且适配成功。
然后最开始我提到还有一种tensorflow官网推荐的安装方式,这里也可以记录一下,在我最开始本机安装的时候,就是用的它那种安装方式,也没什么问题,该网站需要梯子,另外安装方式也是将源放进仓库,我不记得当初安装快不快,因为梯子没断,下面贴出它的过程:
Ubuntu 18.04 (CUDA 10.1):
# Add NVIDIA package repositories
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.1.243-1_amd64.deb
sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
sudo dpkg -i cuda-repo-ubuntu1804_10.1.243-1_amd64.deb
sudo apt-get update
wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb
sudo apt install ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb
sudo apt-get update
# Install NVIDIA driver
sudo apt-get install --no-install-recommends nvidia-driver-430
# Reboot. Check that GPUs are visible using the command: nvidia-smi
# Install development and runtime libraries (~4GB)
sudo apt-get install --no-install-recommends \
cuda-10-1 \
libcudnn7=7.6.4.38-1+cuda10.1 \
libcudnn7-dev=7.6.4.38-1+cuda10.1
# Install TensorRT. Requires that libcudnn7 is installed above.
sudo apt-get install -y --no-install-recommends libnvinfer6=6.0.1-1+cuda10.1 \
libnvinfer-dev=6.0.1-1+cuda10.1 \
libnvinfer-plugin6=6.0.1-1+cuda10.1
tensorflow GPU 支持
项目启动测试
推荐算法环境用anaconda包,如果是web或者后端conda会显得臃肿与难管理,因为现阶段的easy_install、pipenvs、virtualenvwrapper我觉得从资源上面比conda多得多,如果做除了算法外的开发,有时候用conda建立了一个虚拟环境,但会发现conda的资源库里少很多包,比如说opencv-python,还有pyaudio等等,我之前博客中有提到过,这里就不多叙述了。
conda的优势在于机器学习环境下的包确实齐全而又不缺依赖,并且强在版本管理。如果我没记错的话,推荐算法里的surprise包conda下不会报错,但如果用python去安装会说缺少依赖种种,所以都有所互补吧。另外就拿本篇博客来讲,如果我的tensorflow-gpu或者torch进行了升级,用conda管理的环境只需要conda install python==xxx就能完成整个环境的提升,而不是重新部署整个环境,否则就会出现不兼容,就好像torch 1.13不支持低于3.6.2以下的python版本,否则会报cpp错误。
anaconda安装过程,整个写得很详细,基本没有什么要补充,另外本身conda的安装也简单:
Linux下安装Anaconda(64位)详细过程
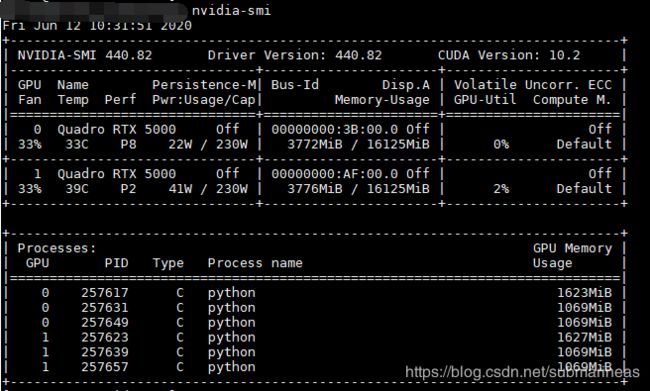
那么tensorflow-gpu和torch我就不说咋安装的了,写进requirement直接装,当用GPU环境启动项目后,我们可以NVIDIA-smi看使用情况:
另外提供测试脚本为:
import tensorflow as tf
with tf.device('/cpu:0'):
a = tf.constant([1.0,2.0,3.0],shape=[3],name='a')
b = tf.constant([1.0,2.0,3.0],shape=[3],name='b')
with tf.device('/gpu:1'):
c = a+b
#注意:allow_soft_placement=True表明:计算设备可自行选择,如果没有这个参数,会报错。
#因为不是所有的操作都可以被放在GPU上,如果强行将无法放在GPU上的操作指定到GPU上,将会报错。
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True))
#sess = tf.Session(config=tf.ConfigProto(log_device_placement=True))
sess.run(tf.global_variables_initializer())
print(sess.run(c))
torch测试代码:
import torch
flag = torch.cuda.is_available()
print(flag)
"""
True
"""