kafka学习笔记总结
kafka学习笔记总结
参考:
http://orchome.com/kafka/index
https://blog.csdn.net/qq_24084925/article/details/78842844
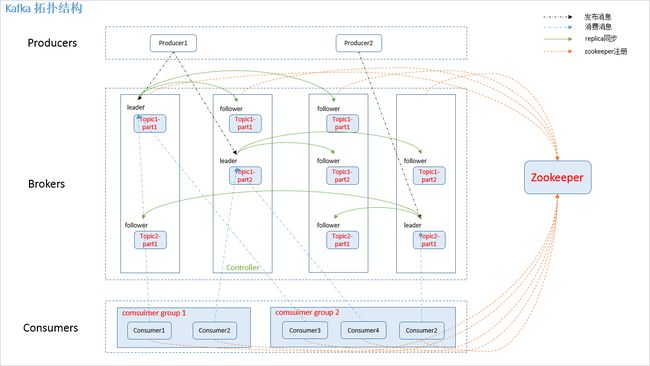
角色说明
Message
通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
Producer
消息生产者,是消息的产生的源头,负责生成消息并发送到Kafka 服务器上。
Consumer
消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。
Consumer group:
high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。
Topic
主题,由用户定义并配置在Kafka服务器,用于建立生产者和消息者之间的订阅关系:生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。
Broker
即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker
Group
消费者分组,用于归组同类消费者,在Kafka中,多个消费者可以共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
Offset
消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个偏移量就是所谓的Offset。
partition:
kafka 分配的单位是 partition。
partition 是物理上的概念,每个 topic 包含一个或多个 partition。
一个 topic可以分为多个 partition,每个 partition 是一个有序的队列。
partition中的每条消息都会被分配一个有序的 id(offset)
replica:
partition 的副本,保障 partition 的高可用。
leader:
replica 中的一个角色, producer 和 consumer 只跟 leader 交互。
Leader 是负责给定分区的所有读取和写入的节点。
每个分区都有一个服务器充当Leader
follower:
replica 中的一个角色,从 leader 中复制数据。
controller:
kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。
zookeeper:
kafka 通过 zookeeper 来存储集群的 meta 信息。
概念
我们认为,一个流处理平台具有三个关键能力:
发布和订阅消息(流),在这方面,它类似于一个消息队列或企业消息系统;
以容错的方式存储消息(流);
在消息流发生时处理它们;
kafka应用于2大类应用:
构建实时的流数据管道,可靠地获取系统和应用程序之间的数据。
构建实时流的应用程序,对数据流进行转换或反应
一些基本概念(The high-level consumer API):
kafka作为一个集群运行在一个或多个服务器上
kafka集群存储的消息是以topic为类别记录的,不同的topic之间是相互独立的
Message在Broker中通过Log追加的方式进行持久化存储,并进行分区(patitions)
为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数
无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间后会被删除
消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息
每个topic可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
partition中的每条Message包含了以下三个属性:
offset 即:消息唯一标识:对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容。kafka 的分配单位是 patition,每个 consumer 都属于一个 group,一个 partition 只能被同一个 group 内的一个 consumer 所消费;
保障了一个消息只能被 group 内的一个 consuemr 所消费,但是多个 group 可以同时消费这个 partition;一个consumer可以消费多个partitions中的消息(消费者数据小于Partions的数量时),consumer 采用 pull 模式从 broker 中读取数据;
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息;
一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每个partition在存储层面是append log文件;
partition是以文件的形式存储在文件系统中的,任何发布到此partition的消息都会被直接追加到log文件的尾部 - 属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)
partition的数据文件索引基于稀疏存储,每隔一定字节的数据建立一条索引;
分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的(Kafka 保证一个 Partition 内的消息的有序性);
通讯过程:
客户端打开与服务器端的Socket
往Socket写入一个int32的数字(数字表示这次发送的Request有多少字节)
服务器端先读出一个int32的整数从而获取这次Request的大小
然后读取对应字节数的数据从而得到Request的具体内容
服务器端处理了请求后,也用同样的方式来发送响应。
kafka有四个核心API:
应用程序使用 Producer API 发布消息到1个或多个topic(主题)。
应用程序使用 Consumer API 来订阅一个或多个topic,并处理产生的消息。
应用程序使用 Streams API 充当一个流处理器,从1个或多个topic消费输入流,并生产一个输出流到1个或多个输出topic,有效地将输入流转换到输出流。
Connector API允许构建或运行可重复使用的生产者或消费者,将topic连接到现有的应用程序或数据系统。例如,一个关系数据库的连接器可捕获每一个变化。
工作流程
消费模式:
The high-level consumer API
high-level consumer API 提供了 consumer group 的语义;
一个消息只能被 group 内的一个 consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
The SimpleConsumer API
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
1. 多次读取一个消息
2. 只消费一个 patition 中的部分消息
3. 使用事务来保证一个消息仅被消费一次
但是使用此 API 时,partition、offset、broker、leader 等对你不再透明,需要自己去管理。你需要做大量的额外工作:
1. 必须在应用程序中跟踪 offset,从而确定下一条应该消费哪条消息
2. 应用程序需要通过程序获知每个 Partition 的 leader 是谁
3. 需要处理 leader 的变更
使用 SimpleConsumer API 的一般流程如下:
1. 查找到一个“活着”的 broker,并且找出每个 partition 的 leader
2. 找出每个 partition 的 follower
3. 定义好请求,该请求应该能描述应用程序需要哪些数据
4. fetch 数据
5. 识别 leader 的变化,并对之作出必要的响应
发布-订阅消息的工作流程(The high-level consumer API)
生产者定期向主题发送消息。
Kafka代理存储为该特定主题配置的分区中的所有消息。 它确保消息在分区之间平等共享。 如果生产者发送两个消息并且有两个分区,Kafka将在第一分区中存储一个消息,在第二分区中存储第二个消息。
消费者订阅特定主题。
一旦消费者订阅主题,Kafka将向消费者提供主题的当前偏移,并且还将偏移保存在Zookeeper系综中。
消费者将定期请求Kafka新消息。
一旦Kafka收到来自生产者的消息,它将这些消息转发给消费者。
消费者将收到消息并进行处理。
一旦消息被处理,消费者将向Kafka代理发送确认。
一旦Kafka收到确认,它将偏移更改为新值,并在Zookeeper中更新它。 由于偏移在Zookeeper中维护,消费者可以正确地读取下一封邮件。
以上流程将重复,直到消费者停止请求。
消费者可以随时回退/跳到所需的主题偏移量,并阅读所有后续消息。
订阅具有相同 Group ID 的主题的消费者被认为是单个组,并且消息在它们之间共享。 让我们检查这个系统的实际工作流程:
队列消息/用户组的工作流(The high-level consumer API)
生产者以固定间隔向某个主题发送消息。
Kafka存储在为该特定主题配置的分区中的所有消息,类似于前面的方案。
单个消费者订阅特定主题,假设 Topic ID为Topic-01,Group ID 为 Group-1 。
Kafka以与发布 - 订阅消息相同的方式与消费者交互,直到新消费者以相同的组ID 订阅相同主题 Topic-01 1 。
一旦新消费者到达,Kafka将其操作切换到共享模式,并在两个消费者之间共享数据。 此共享将继续,直到用户数达到为该特定主题配置的分区数。
一旦消费者的数量超过分区的数量,新消费者将不会接收任何进一步的消息,直到现有消费者取消订阅。 出现这种情况是因为Kafka中的每个消费者将被分配至少一个分区(一个分区同时最多分配给一个消费者),并且一旦所有分区被分配给现有消费者,新消费者将必须等待。
此功能也称为消费者组。
ZooKeeper的作用
Apache Kafka的一个关键依赖是Apache Zookeeper,它是一个分布式配置和同步服务。 Zookeeper是Kafka代理和消费者之间的协调接口。 Kafka服务器通过Zookeeper集群共享信息。 Kafka在Zookeeper中存储基本元数据,例如关于主题,代理,消费者偏移(队列读取器)等的信息。
由于所有关键信息存储在Zookeeper中,并且它通常在其整体上复制此数据,因此Kafka代理/ Zookeeper的故障不会影响Kafka集群的状态。 Kafka将恢复状态,一旦Zookeeper重新启动。 这为Kafka带来了零停机时间。 Kafka代理之间的领导者选举也通过使用Zookeeper在领导者失败的情况下完成。
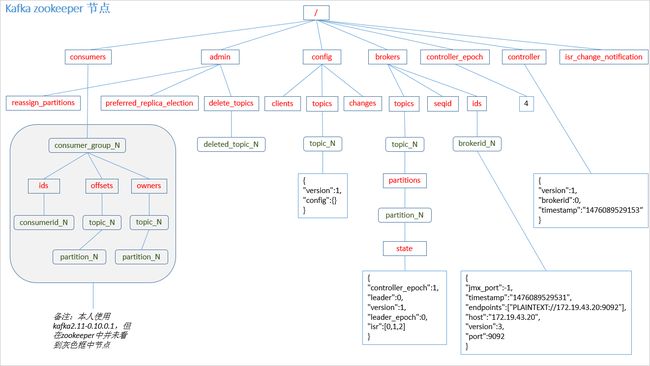
Topic创建、删除流程
//创建
1. controller 在 ZooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被创建,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
2. controller从 /brokers/ids 读取当前所有可用的 broker 列表,对于 set_p 中的每一个 partition:
2.1 从分配给该 partition 的所有 replica(称为AR)中任选一个可用的 broker 作为新的 leader,并将AR设置为新的 ISR
2.2 将新的 leader 和 ISR 写入 /brokers/topics/[topic]/partitions/[partition]/state
3. controller 通过 RPC 向相关的 broker 发送 LeaderAndISRRequest
//删除
1. controller 在 zooKeeper 的 /brokers/topics 节点上注册 watcher,当 topic 被删除,则 controller 会通过 watch 得到该 topic 的 partition/replica 分配。
2. 若 delete.topic.enable=false,结束;否则 controller 注册在 /admin/delete_topics 上的 watch 被 fire,controller 通过回调向对应的 broker 发送 StopReplicaRequest。
写入流程
- producer 先从 zookeeper 的 “/brokers/…/state” 节点找到该 partition 的 leader
- producer 将消息发送给该 leader
- leader 将消息写入本地 log
- followers 从 leader pull 消息,写入本地 log 后 leader 发送 ACK
- leader 收到所有 ISR 中的 replica 的 ACK 后,增加 HW(high watermark,最后 commit 的 offset) 并向 producer 发送 ACK
数据传输的事务定义
- At most once 消息可能会丢,但绝不会重复传输
- At least one 消息绝不会丢,但可能会重复传输
- Exactly once 每条消息肯定会被传输一次且仅传输一次
当 producer 向 broker 发送消息时,一旦这条消息被 commit,由于 replication 的存在,它就不会丢;
但是如果 producer 发送数据给 broker 后,遇到网络问题而造成通信中断,那 Producer 就无法判断该条消息是否已经 commit;
虽然 Kafka 无法确定网络故障期间发生了什么,但是 producer 可以生成一种类似于主键的东西,发生故障时幂等性的重试多次,这样就做到了 Exactly once,但目前还并未实现;
所以目前默认情况下一条消息从 producer 到 broker 是确保了 At least once,可通过设置 producer 异步发送实现At most once。
kafka-php使用
参考:
https://github.com/weiboad/kafka-php/blob/master/README_CH.md
https://github.com/weiboad/kafka-php/blob/master/docs/ch/Configure.md
使用 Composer 安装
添加 composer 依赖 nmred/kafka-php 到项目的 composer.json 文件中即可,如:
{
"require": {
"nmred/kafka-php": "0.2.*"
}
}Produce:
异步回调方式调用
require '../vendor/autoload.php';
date_default_timezone_set('PRC');
use Monolog\Logger;
use Monolog\Handler\StdoutHandler;
// Create the logger
$logger = new Logger('my_logger');
// Now add some handlers
$logger->pushHandler(new StdoutHandler());
$config = \Kafka\ProducerConfig::getInstance();
$config->setMetadataRefreshIntervalMs(10000);
$config->setMetadataBrokerList('10.13.4.159:9192');
$config->setBrokerVersion('0.9.0.1');
$config->setRequiredAck(1);
$config->setIsAsyn(false);
$config->setProduceInterval(500);
$producer = new \Kafka\Producer(function() {
return array(
array(
'topic' => 'test',
'value' => 'test....message.',
'key' => 'testkey',
),
);
});
$producer->setLogger($logger);
$producer->success(function($result) {
var_dump($result);
});
$producer->error(function($errorCode) {
var_dump($errorCode);
});
$producer->send(true);同步方式调用
php
require '../vendor/autoload.php';
date_default_timezone_set('PRC');
use Monolog\Logger;
use Monolog\Handler\StdoutHandler;
// Create the logger
$logger = new Logger('my_logger');
// Now add some handlers
$logger->pushHandler(new StdoutHandler());
$config = \Kafka\ProducerConfig::getInstance();
$config->setMetadataRefreshIntervalMs(10000);
$config->setMetadataBrokerList('127.0.0.1:9192');
$config->setBrokerVersion('0.9.0.1');
$config->setRequiredAck(1);
$config->setIsAsyn(false);
$config->setProduceInterval(500);
$producer = new \Kafka\Producer();
$producer->setLogger($logger);
for($i = 0; $i < 100; $i++) {
$result = $producer->send(array(
array(
'topic' => 'test1',
'value' => 'test1....message.',
'key' => '',
),
));
var_dump($result);
}Consumer
php
require '../vendor/autoload.php';
date_default_timezone_set('PRC');
use Monolog\Logger;
use Monolog\Handler\StdoutHandler;
// Create the logger
$logger = new Logger('my_logger');
// Now add some handlers
$logger->pushHandler(new StdoutHandler());
$config = \Kafka\ConsumerConfig::getInstance();
$config->setMetadataRefreshIntervalMs(10000);
$config->setMetadataBrokerList('10.13.4.159:9192');
$config->setGroupId('test');
$config->setBrokerVersion('0.9.0.1');
$config->setTopics(array('test'));
//$config->setOffsetReset('earliest');
$consumer = new \Kafka\Consumer();
$consumer->setLogger($logger);
$consumer->start(function($topic, $part, $message) {
var_dump($message);
});